

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] FlowMAC: Conditional Flow Matching for Audio Coding at Low Bit Rates
feVeRin 2025. 4. 22. 17:52반응형
FlowMAC: Conditional Flow Matching for Audio Coding at Low Bit Rates
- Low bit-rate에서 동작하는 high-quality general audio compression model이 필요함
- FlowMAC
- Conditional Flow Matching을 기반으로 scalable, memory-efficient training을 지원
- 추론 시 ODE solver를 통해 continuous normalizing flow를 integrate 하여 high-quality mel-spectrogram을 생성
- 논문 (ICASSP 2025) : Paper Link
1. Introduction
- 최근의 neural codec은 12 kbps 보다 낮은 bitrate에서 high quality compression이 가능함
- 대표적으로 SoundStream은 additional GAN loss를 활용해 VQ-VAE를 end-to-end (e2e) training 함
- 여기서 encoder는 learned latent를 추출하고, residual VQ는 bit stream을 생성하고, decoder는 audio를 합성함 - 특히 SoundStream을 개선한 EnCodec, DAC 등은 model size를 extend 하여 high-quality performance를 달성함
- 이때 FunCodec과 같은 e2e VQ-GAN 방식을 활용하면 codec complexity를 줄일 수 있음
- BUT, 6 kbps 이하의 bitrate에서는 expected quality를 만족하지 못함
- 한편으로 LaDiffCodec, MBD와 같이 Denoising Diffusion Probabilistic Model (DDPM)을 neural codec에 도입할 수도 있음
- BUT, high complexity로 인해 활용이 어렵고 pre-trained bit stream에 대한 dependency로 인해 compression capability가 제한됨
- 대표적으로 SoundStream은 additional GAN loss를 활용해 VQ-VAE를 end-to-end (e2e) training 함
-> 그래서 simple pipeline과 high-quality compression을 지원하는 FlowMAC을 제안
- FlowMAC
- Conditional Flow Matching (CFM) objective와 simple reconstruction loss를 결합하여 mel-spectrogram encoder, residual VQ, decoder를 training
- 특히 CFM-based decoder는 discrete latent에서 realistic mel-spectrogram을 생성
< Overall of FlowMAC >
- CFM을 활용한 efficient low-bitrate neural codec
- 결과적으로 3 kbps의 low bitrate에서도 우수한 성능을 달성
2. Background: Flow Matching
- Neural audio coding을 위해서는 input mel-spectrogram을 quantized bit stream으로 compress 하는 encoder-decoder architecture를 학습해야 함
- 여기서 논문은 해당 bit stream information을 사용하여 high-quality mel-spectrogram generation을 위한 CFM-based mel-spectrogram decoder를 conditioning 함
- 즉, input audio signal의 mel-spectrogram distribution $q$에 대해 Gaussian prior $p_{0}$를 $q$로 transform 하는 flow인 time-dependent vector field $\mathbf{u}_{t}$를 학습함 - Flow matching은 $t\in [0,1], \mathbf{x}\in\mathbb{R}^{d}$에 대해 simple sampling distribution $p_{0}(\mathbf{x})$와 target data distribution $q(\mathbf{x})$ 간의 time-dependent probability path $p_{t}:[0,1]\times \mathbb{R}^{d}\rightarrow \mathbb{R}^{\geq 0}$을 fitting 하는 방식으로 동작함
- 결과적으로 논문은 vector field $\mathbf{u}_{t}$를 directly learning 하여 CNF $\phi_{t}$를 training 함
- 먼저 $p_{0}$가 standard Gaussian이고 $p_{1}$이 small variance의 $\mathbf{x}_{1}$을 중심으로 하는 Gaussian일 때 Gaussian path는:
(Eq. 1) $p_{t}(\mathbf{x}|\mathbf{x}_{1})=\mathcal{N}(\mathbf{x};\mu_{t}(\mathbf{x}_{1}),\sigma_{t}(\mathbf{x}_{1})^{2}I)$
- $\mathbf{x}_{1}\sim q(\mathbf{x}_{1})$ : training set에서 얻어지는 sample
- $\mu_{t}(\mathbf{x}_{1})=t\mathbf{x}_{1},\sigma_{t}(\mathbf{x}_{1})=1-(1-\sigma_{\min})t, \,\,\, \sigma_{\min}\ll 1$ - 이때 해당 probability path는 Optimal Transport Conditional Vector Field에 의해 생성됨:
(Eq. 2) $\mathbf{u}_{t}(\mathbf{x}|\mathbf{x}_{1})=\frac{\mathbf{x}_{1}-(1-\sigma_{\min})\mathbf{x}}{1-(1-\sigma_{\min})t}$ - 그러면 이를 기반으로 conditional flow matching objective를 얻을 수 있음:
(Eq. 3) $\mathcal{L}_{CFM}(\theta)=\mathbb{E}_{t,q(\mathbf{x}_{1}),p_{t}(\mathbf{x}|\mathbf{x}_{1})}|| \mathbf{v}_{t}(\mathbf{x};\theta)-\mathbf{u}_{t}(\mathbf{x}|\mathbf{x}_{1}|)||^{2}$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, =\mathbb{E}_{t,q(\mathbf{x}_{1}),p_{0}(\mathbf{x}_{0})}=||\mathbf{v}_{t}(\mathbf{x};\theta)-(\mathbf{x}_{1}-(1-\sigma_{\min})\mathbf{x}_{0})||^{2}$
- $\mathbf{v}_{t}(\mathbf{x},\theta)$ : $\theta$로 parameterize 된 DNN
- $t\sim\mathbb{U}[0,1]$ : uniform distribution에서 sampling 된 time-step
- 먼저 $p_{0}$가 standard Gaussian이고 $p_{1}$이 small variance의 $\mathbf{x}_{1}$을 중심으로 하는 Gaussian일 때 Gaussian path는:
- 논문에서 neural network $\mathbf{v}_{t}(\mathbf{x};\theta)$는 learned mel-spectrogram compression network에서 얻어진 decoded bit stream $c$로 additionally condition 됨
- 추론 시 $\mathbf{v}_{t}$는 $c$와 Gaussian noise sample $\mathbf{x}_{0}$를 input으로 하여 CNF의 derivative를 output 함
- 이후 해당 flow는 Euler method와 같은 ODE solver를 통해 integrate 됨
- 여기서 논문은 해당 bit stream information을 사용하여 high-quality mel-spectrogram generation을 위한 CFM-based mel-spectrogram decoder를 conditioning 함
3. Method
- Mel Encoder-Decoder
- 128 mel-spectrogram band는 512 hop size, 2048 window를 가지는 24kHz input audio에서 calculate 되고 평균, 표준편차는 whole dataset에 대해 offline으로 calculate 되어 input에 대한 fixed normalization factor로 사용됨
- Normalized mel-spectrogram은 128 channel이 있는 $1\times 1$ convolution layer로 전달되어 encoder feature를 추출함
- 구조적으로 encoder는 Multi-Head Attention (MHA), dropout, layer normalization, feed-forward, dropout으로 구성되어 quantize 할 latent vector를 생성함
- 해당 block은 $N=6$번 반복되고, decoder 역시 동일한 structure를 활용함
- 마지막의 $1\times 1$ convolution layer는 decoded quantized mel-spectrogram을 생성하기 위한 final projection layer로 사용됨
- 이때 MSE, MAE loss의 summation $\mathcal{L}_{prior}$를 input mel-spectrogram에 대한 reconstruction loss로 사용함
- Quantization의 경우, VQ-VAE에 기반한 learned residual VQ를 사용하여 small dimensional space에 대한 projection을 수행함
- 이때 논문은 265 codebook size, 8 quantizer stage, 128-dimensional latent에 대한 16 downsampling dimension을 사용함 - 결과적으로 FlowMAC은 초당 47 frame으로 level 당 8 bit를 사용하므로, 총 3 kpbs에서 동작함
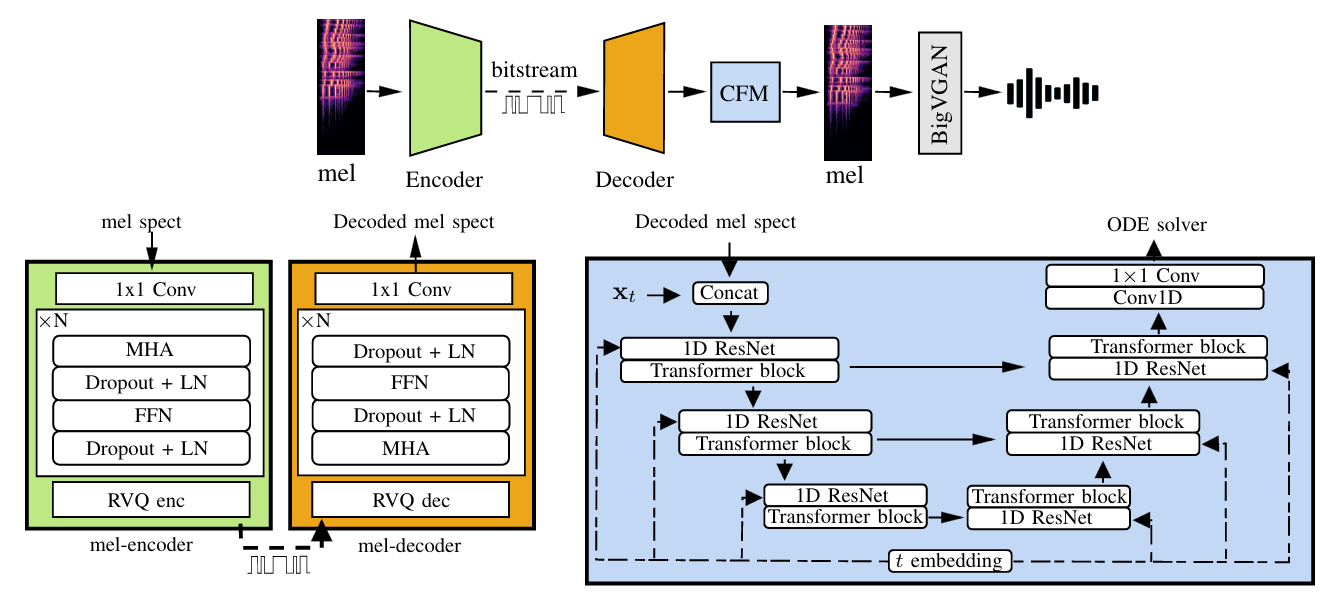
- CFM Module
- CFM architecture는 Matcha-TTS를 따라 residual 1D convolution block이 있는 U-Net과 snakebeta activation을 가지는 Transformer block으로 구성됨
- U-Net output은 1D convolution, group normalization, Mish activation을 통과한 다음, $1\times 1$ convolution을 통해 final output을 생성함
- Time-step embedding은 Grad-TTS를 따라 RoPE-embedding을 사용함
- CFM decoder는 vector field를 추정하기 위해, input Gaussian noise에 대한 concatenation을 통해 decoded quantized mel-spectrogram에 conditioning 됨
- 결과적으로 overall training objective는:
(Eq. 4) $\mathcal{L}=\lambda_{p}\mathcal{L}_{prior}+\lambda_{v}\mathcal{L}_{q}+\lambda_{CFM}$
- $\lambda_{p}=0.01, \lambda_{v}=0.25$ : 각각 prior, VQ-VAE loss $\mathcal{L}_{q}$에 대한 weighting factor - 추가적으로 CFM training을 개선하기 위해 각 mini-batch에 대한 logit normal distribution에 따라 timestep $t$를 sampling 하고 Classifier-Free Guidacne (CFG)를 적용함
- 이때 decoded mel-spectrogram condition은 $p_{g}=0.2$의 probability로 0으로 설정되어 signal quality를 향상함
- U-Net output은 1D convolution, group normalization, Mish activation을 통과한 다음, $1\times 1$ convolution을 통해 final output을 생성함
- Mel-to-Audio Module
- FlowMAC은 Mel-to-Audio module로써 BigVGAN을 활용함
- 이때 decoder initial channel을 1024로 줄이고, additional upsampling layer를 사용하여 smaller architecture를 구성함
- 결과적으로 BigVGAN의 highest quality로 인해 FlowMAC 역시 우수한 성능을 달성할 수 있음
- FlowMAC Inference
- Residual vector quantizer를 통해 inference 시 codebook level을 drop out 하여 bit rate scalability를 달성하고, Euler method의 iterative nature로 인해 CFM decoder에 대한 Numer of Function Evaluation (NFE)를 자유롭게 설정할 수 있음
- 결과적으로 FlowMAC은 1.5 kbps, 3 kbps에서 동작가능하고 ODE solver에 32 step, CFG에 factor 1을 사용하므로, 총 64 NFE를 가짐
- 이때 mel-encoder의 subsystem이 quickly saturate 될 수 있으므로, 6 kbps에서 separately training 된 FlowMAC-CQ를 구성함
- Quality-complexity trade-off를 위해, CFG 없이 Euler method에 대한 single step을 사용하여 총 1 NFE를 가지는 FlowMAC-LC도 추가적으로 고려함
- 한편으로 64 이상의 NFE를 사용해도 quality 향상은 크지 않으므로, CFG factor choice가 더 중요할 수 있음
- 여기서 0.2 보다 작은 값을 사용하면 noisy signal, 2 보다 큰 값을 사용하면 unwanted artifact가 발생함
- 결과적으로 FlowMAC은 1.5 kbps, 3 kbps에서 동작가능하고 ODE solver에 32 step, CFG에 factor 1을 사용하므로, 총 64 NFE를 가짐
3. Experiments
- Settings
- Results
- RTF 측면에서 FlowMAC은 real-time 보다 더 빠르게 동작함
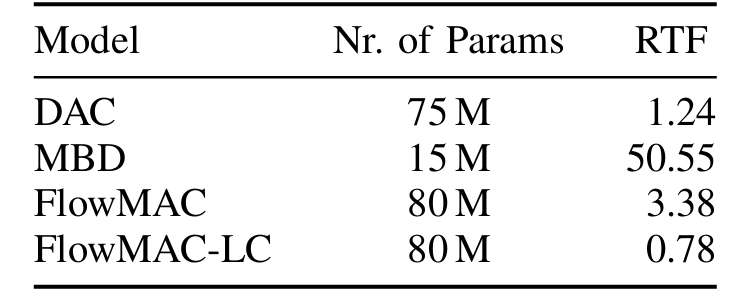
- P.808 DCR listening test 측면에서 FlowMAC은 3 kpbs에서 가장 우수한 성능을 보이고 6 kbps에서 MBD, EnCodec과 유사한 성능을 보임
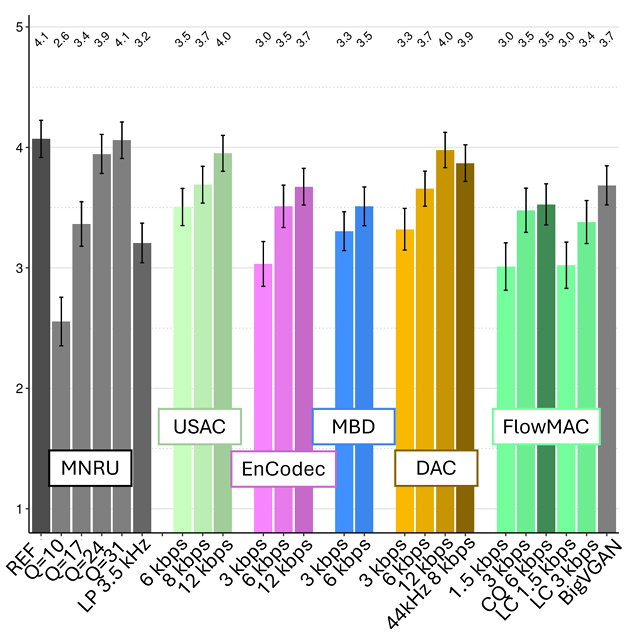
- MUSHRA test에서도 FlowMAC은 우수한 성능을 달성함

반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글