

티스토리 뷰
Paper/TTS
[Paper 리뷰] SSR-Speech: Towards Stable, Safe and Robust Zero-Shot Text-based Speech Editing and Synthesis
feVeRin 2025. 4. 29. 17:48반응형
SSR-Speech: Towards Stable, Safe and Robust Zero-Shot Text-based Speech Editing and Synthesis
- Stable, safe, robust zero-shot text-to-speech model이 필요함
- SSR-Speech
- Transformer decoder를 기반으로 classifier-free guidance를 incorporate
- Watermark EnCodec을 통해 edited region에 대한 frame-level watermark를 embed
- 논문 (ICASSP 2025) : Paper Link
1. Introduction
- YourTTS와 같은 zero-shot text-based speech generation model은 Speech Editing, Text-to-Speech (TTS) task를 위해 사용될 수 있음
- 먼저 zero-shot SE는 original speech의 unchanged portion을 preserving 하면서 target transcript에 맞게 specific word나 phrase를 modify 함
- BUT, SE task의 경우 multiple span, noisy speech 등을 처리하는데 한계가 있고 human voice를 easily clone 하므로 AI safety 측면에서 위험성이 있음 - 한편으로 zero-shot TTS는 target transcript에 따라 whole speech를 generate 함
- 이때 SoundStorm, VoiceBox 등과 같이 large-scale data를 사용하여 stability를 크게 향상할 수 있음
- BUT, phoneme-acoustic alignment에 의존적이고 training process가 complex 함 - 한편으로 VALL-E, VoiceCraft, UniAudio 등은 Language Model (LM)-based Autoregressive (AR) model을 활용함
- BUT, unstable inference 문제가 있음
- 이때 SoundStorm, VoiceBox 등과 같이 large-scale data를 사용하여 stability를 크게 향상할 수 있음
- 먼저 zero-shot SE는 original speech의 unchanged portion을 preserving 하면서 target transcript에 맞게 specific word나 phrase를 modify 함
-> 그래서 Stable, Safe, Robust zero-shot synthesis를 위한 SSR-Speech를 제안
- SSR-Speech
- Stable inference를 위해 inference-only classifier-free guidance를 도입
- Watermark EnCodec을 통해 frame-level watermark를 적용한 safe speech를 생성
- Single-span, multi-span editing을 지원하여 robust editing을 지원
< Overall of SSR-Speech >
- Inference-only classifier-free guidance, watermark EnCodec을 활용한 Stable, Safe, Robust speech synthesis model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- SSR-Speech는 text token, audio neural codec token을 input으로 사용하고 language modeling manner로 masked audio token을 predict 하는 Transformer decoder를 활용함
- Modeling
- Speech signal이 주어지면, EnCodec을 통해 discrete token $A=\{a_{1},a_{2},...,a_{T}\}$로 quantize 함
- 여기서 $T$는 audio token length이고 각 token $a_{i}=\{a_{i,1},a_{i,2},...,a_{i,K}\}$는 EnCodec의 $K$ codebook에 해당함
- Training 시에는 audio의 $P$ continuous span을 randomly mask 함
- Masked token은 special token $[m_{1}],[m_{2}], ..., [m_{P}]$와 concatenate 되고 각 token 뒤에는 special token $[eog]$가 추가됨
- Unmasked token (context token)은 special token $[m_{1}], [m_{2}],...,[m_{P}]$와 유사하게 concatenate 되고 sequence beginning/end에 각각 additional special token $[sos],[eos]$를 사용함
- 이후 audio token의 entire set을 combine 하여 new audio sequence $A'=\{a'_{1},a'_{2},...,a'_{T'}\}$를 구성함
- $T'$ : new length
- 이를 위해 논문은 Transformer decoder를 사용하여 speech transcript에 따라 masked token을 autoregressively modeling 함
- 즉, phoneme sequence $Y=\{y_{1},y_{2},...,y_{L}\}$로 embed 됨
- $L$ : phoneme token length - $A'$의 각 time step $t$에서 model은 phoneme sequence $Y$, $A'$에서 $a'_{t}$까지의 all preceding token $X_{t}$를 condition으로 하는 linear layer를 사용하여 $a'_{t}$를 predict 함:
(Eq. 1) $\mathbb{P}_{\theta}(A'|Y)=\prod_{t}\mathbb{P}_{\theta}(a'_{t}|Y,X_{t})$
- $\theta$ : model parameter - Training loss는 negative log-likelihood로 정의됨:
(Eq. 2) $\mathcal{L}(\theta)=-\log \mathbb{P}_{\theta}(A'|Y)$
- 즉, phoneme sequence $Y=\{y_{1},y_{2},...,y_{L}\}$로 embed 됨
- VoiceCraft를 따라 논문은 causal masking, delayed masking을 고려하고 later codebook에 larger weight를 적용함
- 이때 all token이 아니라 special token을 제외한 masked token에 대해서만 prediction loss를 calculate 함
- 이를 통해 training cost를 줄일 수 있음 - 추가적으로 speech의 beginning/end를 포함한 audio의 all region을 mask 하여 real-world application에 align 함
- 특히 TTS training을 향상하기 위해 certain probability로 speech end를 consistently masking 함
- 이때 all token이 아니라 special token을 제외한 masked token에 대해서만 prediction loss를 calculate 함

- Inference
- SE task의 경우 original transcript를 target transcript와 비교하여 masked word를 identify 해야 함
- 먼저 original transcript의 word-level forced alignment를 사용하여 audio token의 masked span을 locate 함
- 이후 target transcript의 phoneme token과 unmasked audio token을 concatenate 하고 SSR-Speech에 전달하여 new audio token을 autoregressively predict 함
- 이때 SE task에서는 edited span에 대한 neighboring word도 co-articulation effect를 accurately modeling 하기 위해 adjust 되어야 함
- 따라서 논문은 small margin hyperparameter $\alpha$를 도입하여 left/right side 모두에서 $\alpha$ 만큼의 masked span length를 extend 함 - TTS task의 경우 voice prompt transcript가 generated speech의 target transcript와 combine 됨
- 해당 input은 voice prompt의 audio token과 함께 SSR-Speech에 전달됨
- 이때 SE task에서는 edited span에 대한 neighboring word도 co-articulation effect를 accurately modeling 하기 위해 adjust 되어야 함
- 한편으로 autoregressive generation의 stochastic nature로 인해 unnatural-sounding speech가 생성되므로, Classifier-Free Guidance (CFG)를 고려할 수 있음
- BUT, 기존의 CFG approach는 AR model의 dead loop를 해결할 수 없고 training을 unstable 하게 만듦 - 따라서 논문은 unconditional training이 필요 없는 inference-only CFG를 활용함
- 즉, inference 시 random text sequence를 unconditional input으로 사용하고 conditional/unconditional probability의 linear combination으로 얻어진 distribution을 sample 함:
(Eq. 3) $\gamma\mathbb{P}_{\theta}(A'|Y)+(1-\gamma)\mathbb{P}_{\theta}(A'|Y')$
- $\gamma$ : guidance scale, $Y'$ : $Y$와 같은 length를 가지는 random phoneme sequence - 추가적으로 CFG는 silence token을 excessively remove 할 수 있으므로, 추론 시 $\beta$ stride로 CFG를 활용함
- $\beta$ : hyperparameter
- 즉, inference 시 random text sequence를 unconditional input으로 사용하고 conditional/unconditional probability의 linear combination으로 얻어진 distribution을 sample 함:

3. Watermark EnCodec
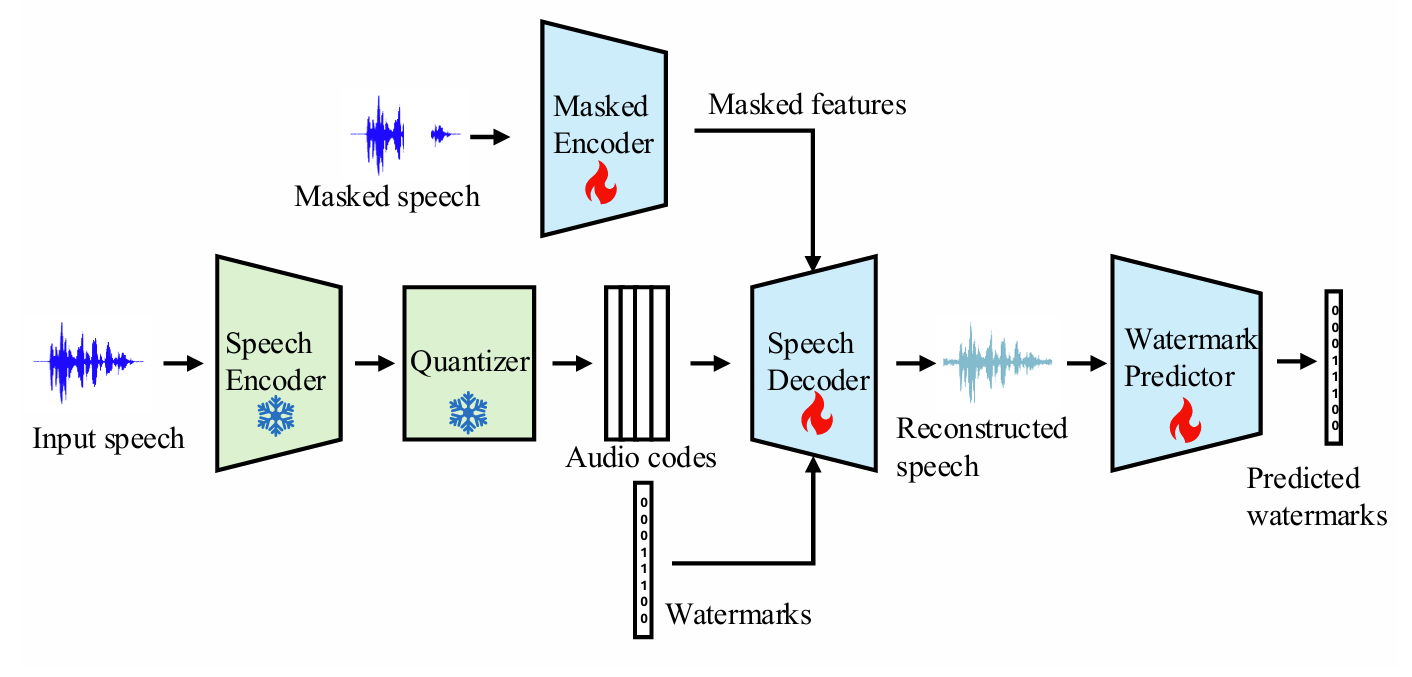
- Watermark EnCodec은 SE task에서 generated audio에 watermark를 적용함
- 구조적으로는 speech encoder, quantizer, speech decoder, masked decoder, watermark predictor로 구성됨
- WaterMarking (WM)
- Speech encoder는 EnCodec encoder와 동일한 network architecture를 사용하고, Watermark predictor는 EnCodec encoder에 binary classification을 위한 final linear layer를 추가하여 구성됨
- 먼저 논문은 EnCodec을 pre-train 하고 해당 encoder parameter를 사용하여 watermark predictor를 initialize 함
- Quantizer는 EnCodec quantizer와 동일함 - Speech decoder는 audio code를 input으로 speech를 reconstruct 함
- 구조적으로는 EnCodec decoder를 기반으로 combined feature를 audio feature와 동일한 dimension으로 project 하는 extra linear layer를 사용함
- Speech decoder parameter 역시 EnCodec decoder로 initialize 됨
- Training 시에는 speech encoder, quantizer가 frozen 됨
- Watermark는 speech encoder가 output 하는 audio frame과 동일한 length를 가지는 binary sequence로써 masked frame은 1, unmasked frame은 0으로 mark 됨
- Watermark feature는 watermark에 embedding layer를 적용하여 얻어짐
- 먼저 논문은 EnCodec을 pre-train 하고 해당 encoder parameter를 사용하여 watermark predictor를 initialize 함
- Context-Aware Decoding (CD)
- EnCodec은 audio code를 사용하여 waveform을 reconstruct 함
- SE task의 경우 unedited span을 유지하는 것이 중요하므로, 논문은 unedited waveform을 watermark EnCodec decoder의 additional input으로 사용하는 Context-Aware Decoding method를 도입함
- 먼저 original waveform의 edited segment를 silence clip으로 mask 한 다음, masked encoder를 사용하여 해당 masked input에서 feature를 추출함
- Masked encoder는 EnCodec encoder와 동일한 architecture를 share 하고 EnCodec parameter로 initialize 됨 - 결과적으로 speech decoder에 대한 input은 audio code, watermark, masked feature로 구성됨
- 먼저 original waveform의 edited segment를 silence clip으로 mask 한 다음, masked encoder를 사용하여 해당 masked input에서 feature를 추출함
- 추가적으로 skip connection을 사용하면 reconstruction quality와 model convergence를 향상할 수 있음
- 따라서 논문은 U-Net을 따라 각 block 간에 multi-scale feature를 fuse 함
- SE task의 경우 unedited span을 유지하는 것이 중요하므로, 논문은 unedited waveform을 watermark EnCodec decoder의 additional input으로 사용하는 Context-Aware Decoding method를 도입함
4. Experiments
- Settings
- Dataset : GigaSpeech, RealEdit, LibriTTS
- Comparisons : VALL-E, VoiceCraft
- Results
- Speech Editing 측면에서 SSR-Speech 성능이 가장 뛰어남

- TTS task에서도 SSR-Speech는 가장 우수한 성능을 보임

반응형
'Paper > TTS' 카테고리의 다른 글
댓글