

티스토리 뷰
Paper/TTS
[Paper 리뷰] STEN-TTS: Improving Zero-Shot Cross-Lingual Transfer for Multi-Lingual TTS with Style-Enhanced Normalization Diffusion Framework
feVeRin 2024. 7. 26. 10:09반응형
STEN-TTS: Improving Zero-Shot Cross-Lingual Transfer for Multi-Lingual TTS with Style-Enhanced Normalization Diffusion Framework
- Multilingual text-to-speech는 주로 fine-tuning을 활용하거나 personal style을 추출하는데 중점을 둠
- STEN-TTS
- 3초의 reference 만으로 multilingual 합성을 수행하고 style을 유지하는 Style-Enhanced Normalization (STEN)을 도입
- 추가적으로 diffusion model에 해당 STEN module을 결합하여 style을 simulate 함
- 논문 (INTERSPEECH 2023) : Paper Link
1. Introduction
- Multilingual adaptive text-to-speech (TTS)는 다양한 language에 대한 dataset을 수집하는 것이 어려움
- 특히 human voice에는 prosody, identity, emotion 등의 많은 information이 포함되어 있으므로 speaking style을 반영하는 것에 한계가 있음
- 이를 극복하기 위해 1~5분의 sample을 통해 fine-tuning 하는 방법을 활용할 수 있음
- BUT, 관련 sample을 학습하기 위해 여전히 많은 iteration이 필요함 - 한편으로 Meta-StyleSpeech, AdaSpeech와 같이 audio reference에서 speaker embedding을 통해 latent vector를 추출하는 방법을 사용할 수도 있음
- Unseen speaker에 대해 few-second의 short audio input만으로도 우수한 adaptation 성능을 보이지만, speaking style variation을 반영하는 데는 한계가 있음
- 이를 극복하기 위해 1~5분의 sample을 통해 fine-tuning 하는 방법을 활용할 수 있음
- 추가적으로 multilingual TTS에서 FastSpeech2, VITS와 같은 non-autoregressive 모델을 사용하는 경우 white noise가 발생할 수 있음
- 특히 YourTTS, SANE-TTS는 short audio input을 통해 cross-lingual TTS를 수행할 때 white noise로 인해 음성 품질이 크게 저하됨 - 이때 DiffSinger, DiffGAN-TTS와 같이 diffusion probabilistic model을 활용하면 해당 white noise를 제거할 수 있음
- Forward process에서 model은 input에 small noise를 추가하고, reverse process에서 denoising model을 통해 $K$ time step으로 original data를 recover 하는 방식으로 동작하기 때문
- BUT, 대부분의 diffusion TTS는 single speaker에 초점을 맞추고 있음
- 특히 human voice에는 prosody, identity, emotion 등의 많은 information이 포함되어 있으므로 speaking style을 반영하는 것에 한계가 있음
-> 그래서 diffusion-based TTS를 cross-domain synthesis로 확장한 STEN-TTS를 제안
- STEN-TTS
- 3초의 audio input 만으로도 cross-lingual TTS가 가능한 diffusion framework
- Style-Enhanced Normalization (STEN) module을 도입하여 seen/unseen speaker 모두에 대한 personal style을 반영
< Overall of STEN-TTS >
- STEN module과 diffusion model을 결합하여 cross-lingual TTS를 수행
- 결과적으로 English, Chinese, Japanese, Indonesian, Vietnamese의 5개 language에 대해 기존보다 우수한 합성 품질을 달성

2. Method
- Text-to-Speech
- STEN-TTS는 FastSpeech2를 기반으로 encoder, variance adaptor, decoder로 구성됨
- Encoder는 phoneme embedding을 input으로 사용하여 hidden sequence로 변환한 다음, Style-Adaptive Layer Normalization에 따라 personal style $PS$ vector와 결합함
- Variance adaptor에서 hidden sequence는 phoneme duration, pitch contour, energy로 augment 됨
- Decoder는 해당 hidden sequence와 $PS$ vector를 fusion 한 다음, HiFi-GAN vocoder를 통해 signal wave를 생성함

- Style Encoder
- Personal Style $PS$를 추출하기 위해, Style Encoder $\text{StyEnc}$ input 이전에 few-second audio $X$는 mel-spectrogram $M_{in}$으로 변환됨
- Style encoder의 output은 128-dimensional vector로써:
(Eq. 1) $PS = \text{StyEnc}(M_{in}),\,\,\, PS\in \mathbb{R}^{N}$ - 구조적으로는 spectral extraction, temporal extraction, multi-head attention으로 구성됨
- Spectral Extraction
- 3개의 linear layer, spectral normalization, Mish activation으로 구성
- Mel-spectrogram $M_{in}$을 input으로 하여 feature vector sequence로 변환 - Temporal Extraction
- Input speaker의 important information을 capture 하는 convolution, batch normalization으로 구성 - Multi-Head Attention
- Temporal block의 output이 multi-head attention으로 전달되고, query/key/value에 따라 speaker에 principal feature를 얻음
- 이후 해당 feature는 fully-connected layer로 전달되고, temporal average pooling을 적용하여 128-dimensional vector로 compress 함
- Spectral Extraction
- Style encoder의 output은 128-dimensional vector로써:
- Style-Enhanced Diffusion Mechanism
- Diffusion model은 training process 동안 initial data sample에 Gaussian noise를 추가함
- 이를 통해 $T$ time step 이후에 input data를 Gaussian noise distribution으로 변환:
(Eq. 2) $M_{t}=\sqrt{\bar{\alpha}_{t}}(M_{t-1})+\sqrt{1-\bar{\alpha}_{t}}\epsilon_{t},\,\,\, t\in(1,...,T)$
- $M_{0}=M_{in}$ : input sample, $\bar{\alpha}_{t}=\prod_{s=1}^{t}\alpha_{s}$
- $T$ time step으로 small noise를 consecutively add 하면 $M_{T}\sim\mathcal{N}(0,I)$가 됨 - 이후 Markov chain을 적용하여 다음을 얻을 수 있음:
(Eq. 3) $q(M_{t}|M_{0})=\mathcal{N}(M_{t};\sqrt{\bar{\alpha}_{t}}M_{0}, (1-\bar{\alpha}_{t})I)$ - Denoising network $\epsilon_{\theta}$를 training 하기 위해 model은 input $M_{t}$를 사용하여 noise $\epsilon\sim \mathcal{N}(0,I)$를 예측하고, 이때 target function은:
(Eq. 4) $\mathcal{L}=\mathbb{E}_{M,\epsilon\sim \mathcal{N}(0,I)}|| \epsilon-\epsilon_{\theta}(M_{t},t)||_{2}^{2}$ - 일반적으로 denoising network $\epsilon_{\theta}$는 U-Net을 채택하고, denoising process를 통해 personal style을 remove 함
- 이때 STEN-TTS에서는 synthesis speech에서 white noise를 제거하면서 detailed vital information을 유지하기 위해 Style-Enhanced Normalization (STEN)을 도입함
- 구체적으로 STEN은 text encoder $TE$와 personal style $PS$의 두 가지 information을 활용 - 먼저 input mel-spectrogram의 hidden vector $h$가 주어지면 layer normalization을 적용하고:
(Eq. 5) $y=\frac{h-\mathbb{E}[h]}{\sqrt{\text{Var}[h]}}*\gamma +\beta$
- $\gamma, \beta$ : learnable hyperparameter - Text representation information을 augment 함:
(Eq. 6) $y=y+\text{Conv}(TE)$ - 그리고 personal style $PS$ vector를 사용하여 adaptability를 향상:
(Eq. 7) $y=f_{g}(PS)*y+f_{h}(PS)$
- $f_{g},f_{h}$ : hidden vector $h$에 대해 scaling, shifting operation을 수행하는 fully-connected layer
- 이때 STEN-TTS에서는 synthesis speech에서 white noise를 제거하면서 detailed vital information을 유지하기 위해 Style-Enhanced Normalization (STEN)을 도입함
- 구조적으로는 U-Net의 각 residual block에 STEN module을 적용하여 denoising moduel $\epsilon_{\theta}$는 few-second reference로부터 similar output을 생성할 수 있음
- 추론 시에 STEN-TTS는 $\widehat{M}_{out}$을 input으로 취하고 $K$ time step으로 denoise 함
- 이를 통해 $T$ time step 이후에 input data를 Gaussian noise distribution으로 변환:
3. Experiments
- Settings
- Dataset : LibriTTS, AISHELL-3, INDSpeech, JVS, Vietnamese Speech
- Comparisons : StyleSpeech, DiffSinger

- Results
- Evaluation for Seen and Unseen Speakers
- Seen/Unseen speaker 모두에 대해서 STEN-TTS가 가장 우수한 성능을 달성함

- Cross Evaluation
- Cross-lingual TTS 측면에서도 마찬가지로 STEN-TTS의 성능이 가장 우수함
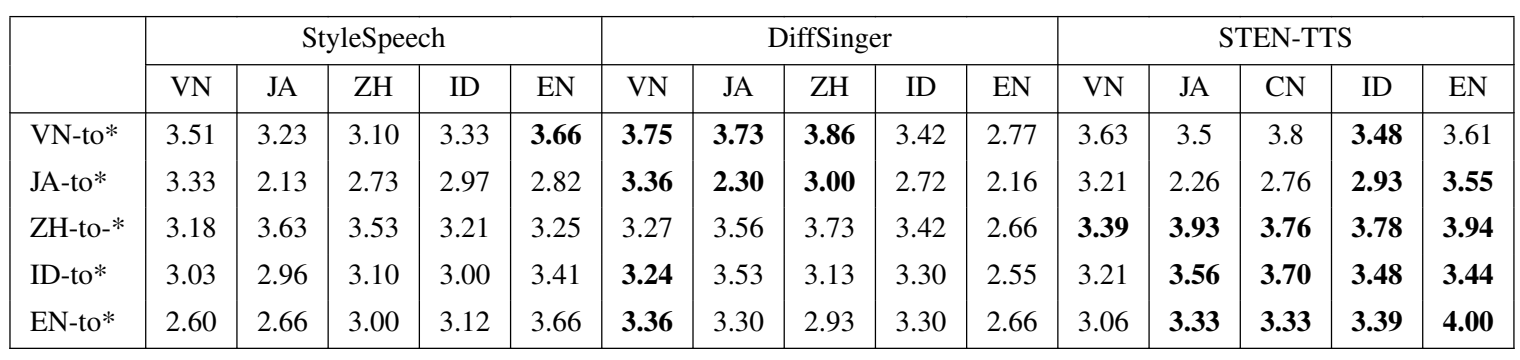
- Similarity Accuracy
- STEN-TTS는 다른 모델들보다 높은 similarity를 보임

- Speaker Visualization
- t-SNE를 통해 speaker embedding을 시각화하면, STEN-TTS는 각 speaker를 명확하게 분리하는 것으로 나타남
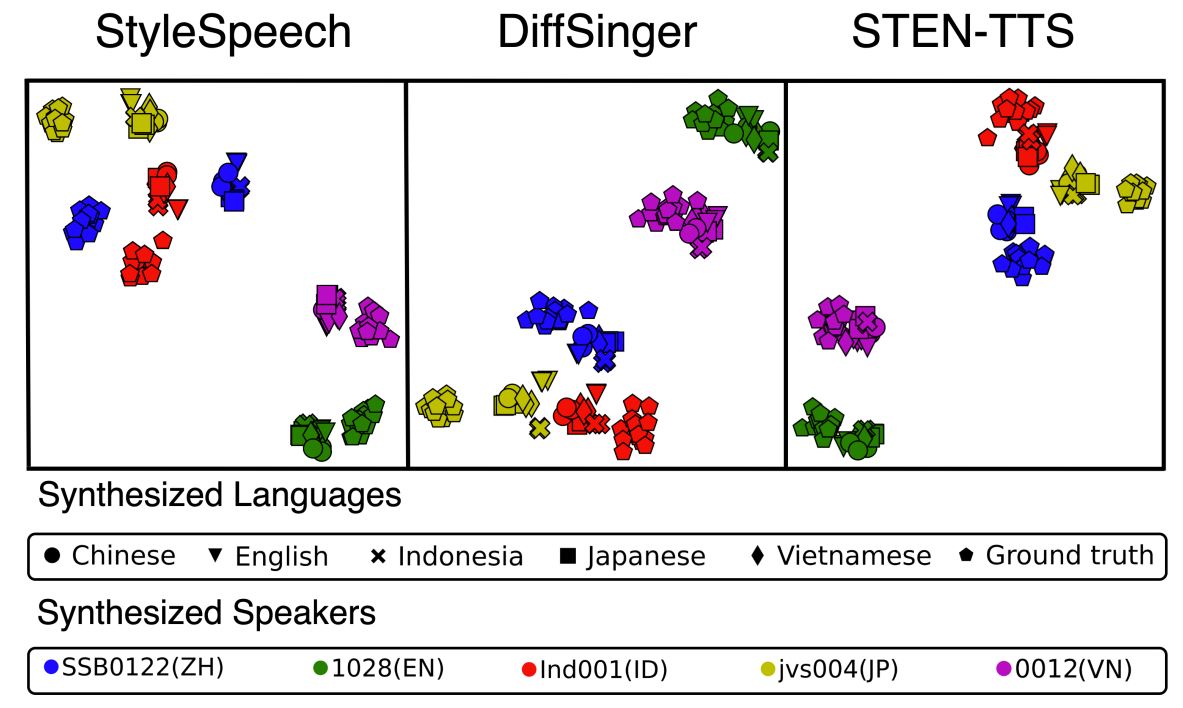
반응형
'Paper > TTS' 카테고리의 다른 글
댓글