

티스토리 뷰
Paper/TTS
[Paper 리뷰] DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
feVeRin 2024. 5. 26. 12:05반응형
DiffGAN-TTS: High-Fidelity and Efficient Text-to-Speech with Denoising Diffusion GANs
- Denoising Diffusion Probabilistic Model (DDPM)은 음성 합성에서 우수한 성능으로 보이고 있지만, 높은 sampling cost의 문제가 있음
- DiffGAN-TTS
- Denoising distribution을 근사하기 위해 adversarially-trained expressive model을 채택한 denoising diffusion generative adversarial network (GAN)을 기반으로 함
- 추가적으로 추론 속도를 더욱 향상하기 위해 active shallow diffusion mechanism을 도입
- Two-stage training scheme을 통해 first stage에서 train 된 basic TTS acoustic model을 second stage에서 train 되는 DDPM에 대한 valuable prior information으로 제공
- 논문 (ICML 2022) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 주어진 text input에 대해 speaker identity, emotion 등을 포함하는 다양한 speech output을 생성하는 것을 목표로 함
- 이때 TTS 모델은 크게 acoustic model과 vocoder로 구성됨
- Acoustic model은 linguistic representation을 mel-spectrogram과 같은 time-frequency domain acoustic feature로 변환하는 역할
- Vocoder는 acoustic feature로부터 time-domain waveform을 생성하는 역할 - 특히 합성된 음성의 expressiveness와 fidelity를 향상하기 위해, acoustic model에서 one-to-many mapping 문제의 다양한 acoustic variation information을 모델링할 수 있는 방법들이 제시됨
- 대표적으로 autoregressive (AR) model은 frame-by-frame으로 acoustic feature를 생성하는 방식을 활용함
- BUT, AR model은 추론 과정에서 accumulate 되는 prediction error로 인해 word skipping, repeating 등의 문제가 발생하고, sequential process로 인해 상당히 느린 추론 속도를 가짐 - 이때 Non-AR model은 기존 AR model의 추론 속도를 개선하기 위해 도입됨
- Flow-based model, Variation AutoEncoder (VAE), Generative Adversarial Network (GAN) 등
- 대표적으로 autoregressive (AR) model은 frame-by-frame으로 acoustic feature를 생성하는 방식을 활용함
- 한편으로 최근의 Denoising Diffusion Probabilistic Model (DDPM)과 같은 diffusion model은 complex data distribution을 모델링하는데 우수한 성능을 보이고 있음
- 이때 diffusion model은 parameter-free $T$-step Markov chain인 diffusion process와 parameterized $T$-step Markov chain인 denoising/reverse process로 구성됨
- Diffusion process는 data에 small random noise를 점진적으로 추가하고, reverse process는 denoising function을 통해 추가된 noise를 remove 함 - BUT, 이러한 diffusion model은 수천번 이상의 denoising step이 필요하므로 real-time으로 동작하기 어려움
- 일반적으로 diffusion model에서 sampling 속도 문제는 denoising distribution이 Gaussian distribution으로 근사된다는 가정에 기반함
- 해당 가정은 denoising step size가 작고, diffusion step이 충분히 커야 한다는 constraint를 모델에 impose 하기 때문 - 이때 효율적인 sampling이 가능한 large denoising step size를 사용하기 위해, non-Gaussian multimodal function을 denoising distribution을 모델링하는 conditional GAN으로써 도입할 수 있음
- 일반적으로 diffusion model에서 sampling 속도 문제는 denoising distribution이 Gaussian distribution으로 근사된다는 가정에 기반함
- 이때 TTS 모델은 크게 acoustic model과 vocoder로 구성됨
-> 그래서 TTS에서 denoising diffusion GAN을 도입하여 느린 sampling 속도를 개선한 DiffGAN-TTS를 제안
- DiffGAN-TTS
- Denoising diffusion GAN을 기반으로 true denoising distribution과 match 하도록 adversarially train 된 expressive generator를 사용하여 denoising distribution을 모델링
- 추론 과정에서 large denoising step을 허용하여 denoising step 수를 크게 줄이고, 추가적으로 active shallow diffusion mechanism을 도입하여 sampling을 가속화
- Two-stage training scheme을 활용해 first stage에서 train 된 basic acoustic model이 second stage에서 train 된 denoising model에 대한 strong prior information을 제공하도록 함
< Overall of DiffGAN-TTS >
- Denoising distribution을 근사하기 위해 adversarially-trained expressive model을 채택한 denoising diffusion GAN을 기반으로 하고, 추론 속도 향상을 위해 active shallow diffusion mechanism을 도입
- Two-stage training scheme을 통해 first stage에서 train 된 basic TTS acoustic model을 second stage에서 train 되는 diffusion model에 대한 valuable prior information으로 제공
- 결과적으로 기존 diffusion TTS model 보다 빠른 추론 속도와 우수한 합성 품질을 달성
2. Diffusion Models
- Diffusion model은 parameter-free $T$-step Markov chain인 diffusion process와 parameterized $T$-step Markov chain인 reverse/denoising process로 구성됨
- Diffusion process는 step $T$에서 data structure가 totally destroyed 될 때까지 data에 small Gaussian noise를 점진적으로 추가하고,
- Reverse process는 추가된 noise를 denoising 하여 data structure를 restore 하는 denoising function을 학습함 - 먼저 $q(\mathbf{x}_{0})$를 $\mathbb{R}^{L}$에 대한 data distribution이라고 하자
- $L$ : data dimension, $q(\mathbf{x}_{T}) \sim \mathcal{N}(0,I)$ : step $T$의 latent variable
- 여기서 diffusion step의 index를 $t$라 하고, $t=0,1,...,T$에 대해 $\mathbf{x}_{t}\in\mathbb{R}^{L}$을 동일한 dimension을 가지는 variable의 sequence라고 하면,
- Diffusion process는 variance schedule $\beta_{1},...,\beta_{T}$를 사용하여 data $\mathbf{x}_{0}$에서 latent variable $\mathbf{x}_{T}$까지의 Gaussian transformation chain으로 모델링 됨:
(Eq. 1) $q(\mathbf{x}_{1:T}|\mathbf{x}_{0})=\prod_{t\geq 1}q(\mathbf{x}_{t}|\mathbf{x}_{t-1})$
- $q(\mathbf{x}_{t}|\mathbf{x}_{t-1}):=\mathcal{N}(\mathbf{x}_{t};\sqrt{1-\beta_{t}}\mathbf{x}_{t-1},\beta_{t}I)$ - Reverse/denoising process는 $\theta$에 의해 parameterize 되어:
(Eq. 2) $p_{\theta}(\mathbf{x}_{0:T})=p(\mathbf{x}_{T})\prod_{t\geq 1}p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})$
- 여기서 denoising distribution $p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})$는 $p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t}):=\mathcal{N}(\mathbf{x}_{t-1};\mu_{\theta}(\mathbf{x}_{t}),\sigma_{t}^{2}I)$와 같은 conditional Gaussian distribution으로 모델링 될 수 있음
- $\mu_{\theta}(\mathbf{x}_{t}), \sigma_{t}^{2}I$ : denoising model의 평균, 분산 - Well-learned parameter $\theta$를 사용하여 parameterize 된 reverse process가 주어지면, sampling/generation process는 다음과 같이 구성됨:
- 먼저 Gaussian noise $\mathbf{x}_{T}\sim\mathcal{N}(0,I)$를 sampling 하고
- Langevin dynamics와 같은 reverse process를 따라 $t=T,T-1,...,1$에 대해 $\mathbf{x}_{t-1}\sim p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})$를 iteratively sampling 함
- $\mathbf{x}_{0}$ : 생성된 data
- 이때 likelihood $p_{\theta}(\mathbf{x}_{0})=\int p_{\theta}(\mathbf{x}_{0:T})d\mathbf{x}_{1:T}$는 intractable 함
- 따라서 training objective를 Evidence Lower BOund ($\mathrm{ELBO}\leq \log p_{\theta}(\mathbf{x}_{0})$)를 최대화하는 것으로 설정하면,
- 다음과 같이 parameterized denoising model $p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})$와 true denoising distribution $q(\mathbf{x}_{t-1}|\mathbf{x}_{t})$를 matching 시키는 방식으로 최적화됨:
(Eq. 3) $\mathrm{ELBO}=\sum_{t\geq 1}\mathbb{E}_{q(\mathbf{x}_{t})}[D_{KL}(q(\mathbf{x}_{t-1}|\mathbf{x}_{t}) ||p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t}) )]+c$
- $D_{KL}$ : Kullback-Leibler (KL) diviergence, $c$ : $\theta$에 dependent 하지 않은 constant term
- 한편으로 (Eq. 3)의 KL-divergence term 역시 unknown true denoising distribution $q(\mathbf{x}_{t-1}|\mathbf{x}_{t})$로 인해 일반적으로 intractable 함
- 따라서 DDPM에서는 variance schedule의 step size $\beta_{t}$가 작고, denoising step $T$가 충분히 크다고 가정하여, diffusion/denoising process 모두가 동일한 functional form (conditional Gaussian)을 가지도록 함
- 즉, DDPM은 ELBO 최적화 문제를 simple regression으로 변환하는 특정한 parameterization을 활용함
- Diffusion process는 step $T$에서 data structure가 totally destroyed 될 때까지 data에 small Gaussian noise를 점진적으로 추가하고,
3. DiffGAN-TTS
- Diffusion model은 complex data distribution을 효과적으로 모델링할 수 있지만, 느린 추론 속도로 인해 real-time application에서 사용하기 어려움
- 이는 다음의 2가지 commonly-made 가정 때문:
- Denoising distribution $p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})$는 Gaussian distribution으로 모델링 됨
- Denoising step $T$는 충분히 큼
- 특히 denoising step이 커지고 data distribution이 non-Gaussian이면, true denoising distribution은 더 complex 하고 multimodal이 됨
- 이 경우, denoising distribution을 근사하기 위해 parameterized Gaussian을 채택하는 것은 적합하지 않음 - 한편으로 이러한 multimodal denoising distribution을 모델링하기 위해 conditional GAN을 채택할 수 있음
- 따라서 논문은 해당 conditional GAN을 TTS task로 확장하는 것을 목표로 함
- 이는 다음의 2가지 commonly-made 가정 때문:

- Acoustic Generator and Discriminator
- DiffGAN-TTS는 phoneme sequence $\mathbf{y}$를 input으로 하여 multi-speaker acoustic generator를 통해 intermediate mel-spectrogram feature $\mathbf{x}_{0}$를 생성한 다음, HiFi-GAN vocoder를 통해 time-domain waveform을 합성함
- 이때 ill-posed multimodal phoneme-to-mel-spectorgram 문제를 해결하기 위해 DDPM이 acoustic generator에 도입됨
- 여기서 논문은 합성 품질을 유지하면서 real-time 수준의 추론 속도를 얻기 위해, DiffGAN-TTS의 denoising step $T$ 수를 줄이는 것을 목표로 함 (e.g., $T\leq 4$)
- 따라서 DiffGAN-TTS는 conditional GAN-based acoustic generator $p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})$를 training하여 true denoising distribution $q(\mathbf{x}_{t-1}|\mathbf{x}_{t})$를 근사함
- 이때 denoising step 당 divergence $D_{adv}$를 최소화하는 adversarial loss를 사용:
(Eq. 4) $\min_{\theta}\sum_{t\geq 1}\mathbb{E}_{q(\mathbf{x}_{t})}[D_{adv}(q(\mathbf{x}_{t-1}|\mathbf{x}_{t})||p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t}) )]$
- $D_{adv}$를 최소화하기 위해 least-squares GAN의 training formulation을 채택
- 따라서 DiffGAN-TTS는 conditional GAN-based acoustic generator $p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})$를 training하여 true denoising distribution $q(\mathbf{x}_{t-1}|\mathbf{x}_{t})$를 근사함
- Speaker ID를 $s$라고 하면, discriminator는 diffusion-step-dependent하고 speaker-aware하도록 설계됨
- 이때 learnable parameter $\phi$를 가지는 discriminator $D_{\phi}(\mathbf{x}_{t-1},\mathbf{x}_{t},t,s)$는 Joint Conditional and Uncoditional (JCU)로 모델링 됨
- 결과적으로 unconditional logit 뿐만 아니라, diffusion step embedding과 speaker embedding을 condition으로 하는 conditional logit도 output함 - Implicit denoising model로써 denoising function을 parameterize 하기 위해,
- $\mathbf{x}_{t}$로부터 $\mathbf{x}_{t-1}$을 예측하여 $p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})$를 직접 모델링하는 대신, denoising function을 $p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t}):=q(\mathbf{x}_{t-1}|\mathbf{x}_{t},\mathbf{x}_{0}=f_{\theta}(\mathbf{x}_{t},t))$로 모델링함
- 즉, $\mathbf{x}_{0}$는 $\theta$로 parameterize 된 diffusion function $f_{\theta}(\mathbf{x}_{t},t)$를 사용하여 diffuse 된 sample $\mathbf{x}_{t}$에서 예측됨 - Training 중에 $\mathbf{x'}_{t-1}$은 posterior distribution은 $q(\mathbf{x'}_{t-1}|\mathbf{x'}_{0},\mathbf{x}_{t})$를 사용하여 sampling 됨
- $\mathbf{x'}_{0}$ : 예측된 $\mathbf{x}_{0}$ - 이후 예측된 tuple $(\mathbf{x'}_{t-1},\mathbf{x}_{t})$은 JCU discriminator에 전달되어 해당하는 bonafide counterpart $(\mathbf{x}_{t-1},\mathbf{x}_{t})$에 대한 divergence $D_{adv}$를 계산함
- $\mathbf{x}_{t}$로부터 $\mathbf{x}_{t-1}$을 예측하여 $p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})$를 직접 모델링하는 대신, denoising function을 $p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t}):=q(\mathbf{x}_{t-1}|\mathbf{x}_{t},\mathbf{x}_{0}=f_{\theta}(\mathbf{x}_{t},t))$로 모델링함
- 논문에서는 latent variable $\mathbf{z}\sim\mathcal{N}(0,I)$를 acoustic generator의 input으로 사용하지 않음
- Diffusion decoder는 acoustic generator의 variance adaptor에서 얻어지는 variance-adapted text encoding과 speaker ID를 auxiliary input으로 사용하기 때문
- 즉, implicit distribution $f_{\theta}(\mathbf{x}_{t},t)$는 acoustic generator $G_{\theta}(\mathbf{x}_{t},\mathbf{y},t,s)$로 모델링됨
- 이는 phoneme input $\mathbf{y}$, diffusion step index $t$, speaker ID $s$를 condition으로 하여 $\mathbf{x}_{t}$에서 $\mathbf{x}_{0}$를 예측
- 이때 ill-posed multimodal phoneme-to-mel-spectorgram 문제를 해결하기 위해 DDPM이 acoustic generator에 도입됨

- Training Loss
- 먼저 discriminator는 다음을 최소화하는 것으로 train 됨:
(Eq. 5) $\mathcal{L}_{D}=\sum_{t\geq 1}\mathbb{E}_{q(\mathbf{x}_{t})q(\mathbf{x}_{t-1}|\mathbf{x}_{t})}[(D_{\phi}(\mathbf{x}_{t-1},\mathbf{x}_{t},t,s)-1)^{2}]+\mathbb{E}_{p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})}[D_{\phi}(\mathbf{x}_{t-1},\mathbf{x}_{t},t,s)^{2}]$ - 한편으로 acoustic generator를 training 하기 위해, 논문에서는 feature space에서 real/fake data를 discriminate 하는 similarity metric을 학습하는 feature matching loss $\mathcal{L}_{fm}$을 도입함
- 여기서 $\mathcal{L}_{fm}$은 real sample과 생성된 sample의 모든 discriminator feature map 간의 $l_{1}$ distance를 summing 하여 계산됨:
(Eq. 6) $\mathcal{L}_{fm}=\mathbb{E}_{q(\mathbf{x}_{t})}[\sum_{i=1}^{N}||D_{\phi}^{i}(\mathbf{x}_{t-1},\mathbf{x}_{t},t,s)-D_{\phi}^{i}(\mathbf{x'}_{t-1},\mathbf{x}_{t},t,s) ||_{1}]$
- $N$ : discriminator의 hidden layer 수 - Acoustic reconstruction loss는 FastSpeech2를 따라 additional loss로 사용됨:
(Eq. 7) $\mathcal{L}_{recon}=\mathcal{L}_{mel}(\mathbf{x}_{0},\mathbf{x'}_{0})+\lambda_{d}\mathcal{L}_{duration}(\mathbf{d},\hat{\mathbf{d}})+\lambda_{p}\mathcal{L}_{pitch}(\mathbf{p},\hat{\mathbf{p}})+\lambda_{e}\mathcal{L}_{energy}(\mathbf{e},\hat{\mathbf{e}})$
- $\mathbf{d},\mathbf{e},\mathbf{p}$ : 각각 target duration, energy, pitch
- $\hat{\mathbf{d}}, \hat{\mathbf{e}}, \hat{\mathbf{p}}$ : 각각 예측된 druation, energy, pitch
- $\lambda_{d}, \lambda_{e}, \lambda_{p}$ : loss weight로써, 논문에서는 0.1로 설정
- $\mathcal{L}_{mel}$은 MAE loss를 사용하고, $\mathcal{L}_{duration}, \mathcal{L}_{pitch}, \mathcal{L}_{energy}$는 MSE loss를 사용함 - 결과적으로 total acoustic generator loss는:
(Eq. 8) $\mathcal{L}_{G}=\mathcal{L}_{adv}+\mathcal{L}_{recon}+\lambda_{fm}\mathcal{L}_{fm}$
- 여기서,
(Eq. 9) $\mathcal{L}_{adv}=\sum_{t\geq 1}\mathbb{E}_{q(\mathbf{x}_{t})}\mathbb{E}_{p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t})}[(D_{\phi}(\mathbf{x}_{t-1},\mathbf{x}_{t},t,s)-1)^{2}]$
- $\lambda_{fm}$ : dynamically scaled scalar로써 $\lambda_{fm}=\mathcal{L}_{recon}/\mathcal{L}_{fm}$과 같이 계산됨
- 전체적인 training, inference 과정은 아래 [Algorithm 1], [Algorithm 2]와 같음
- 여기서 $\mathcal{L}_{fm}$은 real sample과 생성된 sample의 모든 discriminator feature map 간의 $l_{1}$ distance를 summing 하여 계산됨:

- Active Shallow Diffusion Mechanism
- TTS에서 대부분의 acoustic model은 MSE나 MAE 같은 simple loss로 training 됨
- 이때 해당 acoustic model에서 생성된 acoustic feature는 data에 대한 incorrect unimodal 가정으로 인해 over-smoothing 문제가 발생하고 합성 품질의 저하로 이어짐
- BUT, 이러한 blurry acoustic prediction이 완전히 무의미하지는 않음
- MSE, MAE loss로 train 된 acoustic model의 output은 coarse harmonic structure와 같은 acoustic feature에 대한 strong prior knowledge를 제공할 수 있기 때문
- 따라서 DDPM에 해당 prior knowledge를 반영하면 refined feature를 얻을 수 있고 성능 개선이 가능
- 따라서 DiffGAN-TTS는 추론을 가속화하고 합성 성능을 보장하기 위해 active shallow diffusion mechanism을 도입하고, 아래 그림과 같은 two-stage training scheme을 설계함
- First stage에서는 $\psi$로 parameterize 된 basic acoustic model $G_{\psi}^{\text{base}}(\mathbf{y},s)$가 training 됨:
(Eq. 10) $\min_{\psi}\sum_{t\geq 0}\mathbb{E}_{q(\mathbf{x}_{t})}[\mathrm{Div}(q_{\text{diff}}^{t}(G_{\psi}^{\text{base}}(\mathbf{y},s) ),q_{\text{diff}}^{t}(\mathbf{x}_{0}) )]$
- $\mathrm{Div}(\cdot,\cdot)$ : ground-truth와 예측값 간의 divergence를 계산하는 distance function
- $q_{\text{diff}}^{t}(\cdot)$ : step $t$에서의 diffusion sampling function ($\mathbf{x}_{t}=q_{\text{diff}}^{t}(\mathbf{x}_{0})$)
- 특히, $q_{\text{diff}}^{0}(\cdot)$은 identity function이고, 해당 training objective는 basic acoustic model이 ground-truth에서 diffuse 된 sample과 예측된 sample을 indistinguishable 하게 만드는 방법을 학습하도록 함 - Second stage에서는 basic acoustic model의 pre-trained weight가 copy 되어 DiffGAN-TTS의 acoustic generator의 weight를 initialize 하고, frozen 됨
- 이때 basic acoustic model은 diffusion decoder에 의해 condition 되는 coarse mel-spectrogram $\hat{\mathbf{x}_{0}}$를 생성함
- 그러면 (Eq. 10)의 divergence $D_{adv}(q(\mathbf{x}_{t-1}|\mathbf{x}_{t})|| p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t}))$는 $D_{adv}(q(\mathbf{x}_{t-1}|\mathbf{x}_{t})||p_{\theta}(\mathbf{x}_{t-1}|\mathbf{x}_{t},\hat{\mathbf{x}}_{0}))$에 의해 근사됨
- First stage에서는 $\psi$로 parameterize 된 basic acoustic model $G_{\psi}^{\text{base}}(\mathbf{y},s)$가 training 됨:
- 특히, 위 과정을 통해 DiffGAN-TTS는 denoising step을 1로 줄일 수 있음
- 추론 시 acoustic model은 한 번의 diffusion step으로 diffuse 된 sample $\hat{\mathbf{x}_{1}}$을 계산하여 coarse mel-spectrogram $\hat{\mathbf{x}}_{0}$을 생성함
- 이후, $\hat{\mathbf{x}_{1}}$을 prior로 취하고, 한 번의 denoising step을 수행하여 final output을 얻음

- Model Architecture
- DiffGAN-TTS의 acoustic generator에서 transformer encoder는 FastSpeech2를 따라 4개의 Feed-Forward Transformer (FFT) block으로 구성됨
- FFT block의 1D convolution에 대한 hidden size, attention head 수, kernel size, fitler size는 각각 $256, 2, 9, 1024$로 설정됨
- Variance adaptor 역시 구조적으로는 FastSpeech2와 동일하게 duration/pitch/energy predictor로 구성됨
- 이때 pitch, energy predictor는 각각 phoneme-level fundamental frequency $F_{0}$ contour와 energy contour를 output 하고,
- 해당 label은 Hidden-Markov-Model (HMM) force aligner로 얻어진 phoneme-audio alignment information에 따라 frame-level $F_{0}$와 energy를 평균하여 얻어짐 - DiffGAN-TTS의 diffusion decoder는 non-causal WaveNet architecture를 활용함
- Dilation rate는 1로 설정하고, noisy mel-spectrogram $\mathbf{x}_{t}$에서 kernel size 1을 사용하여 1D convolution을 적용함
- Diffusion step $t$는 sinusoidal positional encoding을 사용하여 encode 됨 - Mel-spectrogram feature map은 diffusion step embedding에 추가된 다음, hidden dimension이 256인 20개의 WaveNet residual block에 전달됨
- Transformer encoder의 output은 separate Conv $1\times 1$ layer를 통과한 다음, hidden feature map에 더해짐
- 이후 gated mechanism을 사용하여 feature map을 further process 함 - 논문은 모든 WaveNet block에서 skip connection을 추가한 다음, ReLU activation으로 interleave 된 2개의 Conv $1\times 1$ layer를 통과시켜 diffusion decoder output을 얻음
- 이때 모든 WaveNet residual block에는 speaker ID가 embeddding vector로 변환되어 반영됨
- Dilation rate는 1로 설정하고, noisy mel-spectrogram $\mathbf{x}_{t}$에서 kernel size 1을 사용하여 1D convolution을 적용함
- JCU discriminator는 puerly convolution network를 기반으로 함
- Conv1D block은 LeakyReLU를 activation으로 사용하는 3개의 1D convolution layer로 구성되고, diffusion step embedding layer는 앞선 diffusion decoder와 동일함
- Unconditional block과 conditional block은 2개의 1D convolution layer로 구성된 동일한 network를 가짐
- Convolution channel은 $64, 128, 512, 128, 1$을 사용하고, kernel size는 $3,5,5,5,3$, stride는 $1,2,2,1,1$로 설정
- Basic acoustic model의 transformer encoder와 variance adaptor 역시 acoustic generator와 동일하고, mel decoder로는 4개의 FTT block을 사용함

4. Experiments
- Settings
- Dataset : Chinese speech data (internal)
- Comparisons : FastSpeech2, GANSpeech, DiffSpeech
- Results
- Objective/Subjective Evaluation
- 각 metric에서 DiffGAN-TTS는 다른 모델들과 비교하여 가장 우수한 성능을 보임
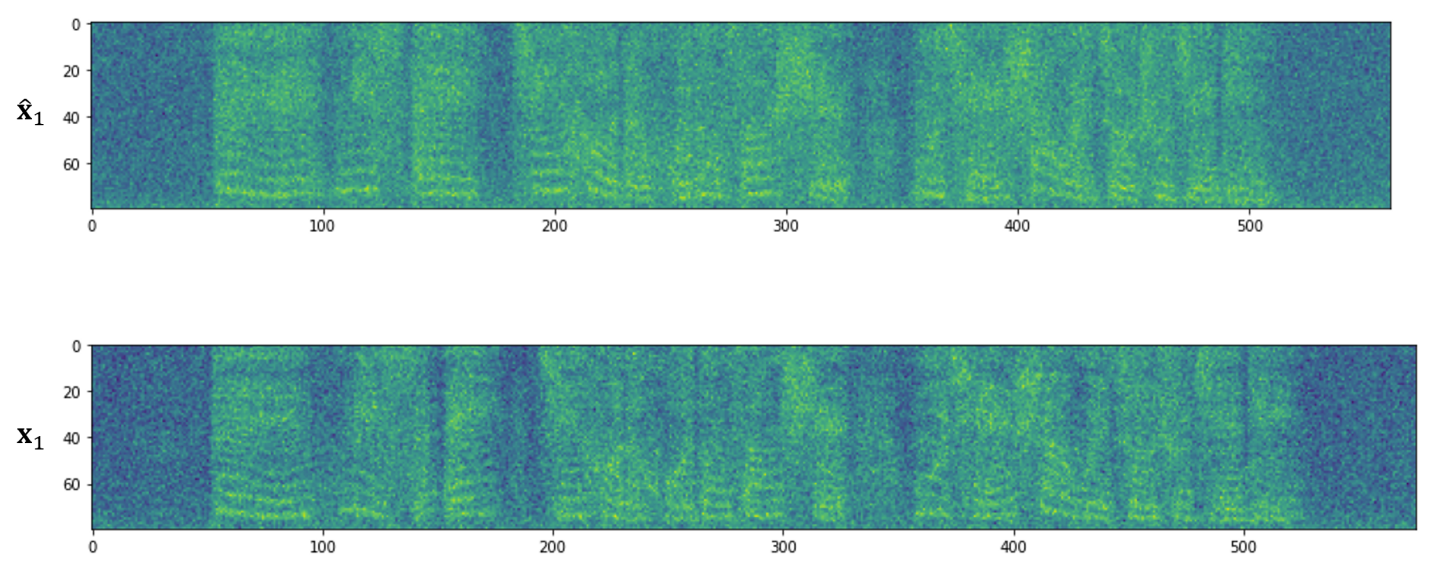
- Mel-spectrogram 측면에서 비교해 보면, 예측된 $\hat{\mathbf{x}}_{1}$가 ground-truth $\mathbf{x}_{1}$과 비슷한 harmonic structure를 보임

- Synthesis Speed
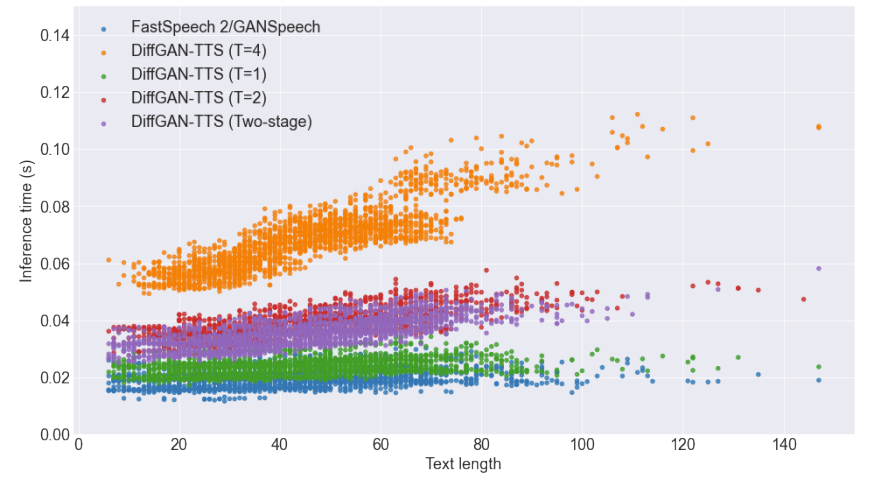
- Text length에 대한 추론 시간을 비교해 보면, DiffGAN-TTS ($T=1$)는 text length에 대해 FastSpeech2와 유사한 scaling 성능을 보임
- Ablation Study
- DiffGAN-TTS에 대해 mel loss $\mathcal{L}_{mel}$, feature matching loss $\mathcal{L}_{fm}$의 효과와 diffusion decoder에서 latent variable $\mathbf{z}$의 영향을 알아보면
- 두 loss가 모두 제거되는 경우, 모델이 전혀 training 되지 않는 것으로 나타남
- 즉, DiffGAN-TTS를 training 하는데 adversarial loss 만으로는 충분하지 않음
- 한편으로 $\mathcal{L}_{fm}$과 $\mathcal{L}_{mel}$을 비교해 보면, mel loss가 좀 더 효과적임 - 추가적으로 latent variable을 모델에 추가하는 경우, 전체적인 성능이 다소 저하되는 것으로 나타남
- Variance adaptor, speaker conditioning이 acoustic variation을 이미 모델링하기 때문

- Synthesis Variation
- DiffGAN-TTS는 denoising step에서 sampling을 수행하고 생성된 음성에 variation을 inject 할 수 있음
- 실제로 DiffGAN-TTS로 생성된 sample의 $F_{0}$ contour를 비교해 보면, 아래 그림의 (a)와 같이 다양한 pitch의 음성을 생성하는 것으로 나타남
- 한편으로 DiffGAN-TTS는 (b)와 같이 서로 다른 speaker에 대해서도 다양한 prosody pattern을 표현할 수 있음

반응형
'Paper > TTS' 카테고리의 다른 글
댓글