
티스토리 뷰
Paper/TTS
[Paper 리뷰] EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
feVeRin 2024. 7. 22. 09:32반응형
EmoSphere-TTS: Emotional Style and Intensity Modeling via Spherical Emotion Vector for Controllable Emotional Text-to-Speech
- Emotional text-to-speech는 pre-defined label로 제한되므로 emotion의 변화를 효과적으로 반영하지 못함
- EmoSphere-TTS
- Emotional style, intensity를 control 하는 spherical emotion vector를 채택
- Human annotation 없이 arousal, valence, dominance pseudo-label을 사용하여 Cartesian-spherical transformation을 통해 emotion을 모델링
- Dual conditional adversarial network를 통해 multi-aspect characteristic을 반영하여 음성 품질을 개선
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Emotional text-to-speech (TTS)는 PromptStyle, ZET-Speech 등에서 우수한 합성 품질을 보이고 있지만, 여전히 high-level interpretable emotion control에 대해서는 한계가 있음
- 일반적으로 emotional TTS는 emotion label과 reference audio를 통해 emotional expression을 control 함
- 대표적으로 relative attribute 방식은 learned ranking function이나 distance-based quantization을 활용하여 fine-grained emotional intensity를 반영
- Scaling factor 방식은 emotion embedding에 multiply 되어 emotion intensity를 control
- BUT, 해당 방식들은 emotion label이나 reference에 기반하므로 emotion expression을 uniform style로 reduce 하고, mismatch로 인해 nuance를 capture 하기 어렵다는 문제가 있음
- 한편으로 arousal, valence, dominance (AVD)에 대한 emotional dimension을 활용하여 expression을 control 하는 방식을 고려할 수 있음
- 해당 emotion dimension은 continuous, fine-grained description을 제공하므로 discrete emotion보다 detail 한 control이 가능
- 일반적으로 emotional TTS는 emotion label과 reference audio를 통해 emotional expression을 control 함
-> 그래서 spherical emotion vector space를 활용한 emotional TTS 모델인 EmoSphere-TTS를 제안
- EmoSphere-TTS
- Speech emotion recognition의 pseudo-labeling에 대한 AVD의 emotional dimension을 도입
- Cartesian-spherical transformation을 통한 spherical emotion vector space를 구성하여 Cartesian coordinate에서의 emotion 모델링 한계를 극복
- 추가적으로 dual conditional adversarial training을 통해 음성 품질을 개선
< Overall of EmoSphere-TTS >
- Emotion sphere와 dual conditional adversarial training을 활용한 emotional TTS 모델
- 결과적으로 기존보다 뛰어난 controllability와 합성 품질을 달성
2. Method
- Emotional Style and Intensity Modeling
- EmoSphere-TTS는 다음의 component를 중심으로 spherical emotion vector space를 구성하여 다양한 emotional expression을 모델링함:
- AVD Encoder
- Cartesian-Spherical Transformation
- AVD Encoder
- Human annotation의 emotional dimension을 사용하는 대신 wav2vec 2.0 기반의 SER model을 채택하여 audio에서 consistently continuous, detailed representation을 추출함
- 이때 해당 model은 Cartesian coordinate에서 $[0,1]$ range에 속하는 $e_{ki}=(d_{a},d_{v},d_{d})$에 대한 예측을 생성함
- $d_{a}$ : arousal, $d_{v}$ : valence, $d_{d}$ : dominance
- $e_{ki}$ : $k$-th emotion의 $i$-th coordinate
- Cartesian-Spherical Transformation
- 논문은 emotion의 complex nature를 모델링하기 위해 neutral center에서 relative distance와 angle vector를 represent 하는 spherical emotion vector space를 도입함
- Emotion style과 intensity를 continuous scalar로 control하는 coordinate transformation을 기반으로, 다음 가정에 따라 AVD pseudo-label의 모든 point를 spherical coordinate로 변환함
- Emotional intensity는 neutral emotion center에서 멀어질수록 증가함
- Neutral emotion center에 대한 angle은 emotional style을 결정함
- 먼저 neutral emotion center $M$을 origin으로하여 transformed Cartesian coordinate $e'_{ki}=(d'_{a},d'_{v},d'_{d})$를 얻음:
(Eq. 1) $e'_{ki}=e_{ki}-M, \,\, \text{where}\,\, M=\frac{1}{N_{n}}\sum_{i=1}^{N_{n}}e_{ni}$
- $N_{n}$ : neutral coordinate $e_{ni}$의 총 개수 - 그러면 Cartesian coordinate에서 spherical coordinate $(r,\vartheta, \varphi)$로의 transformation은:
(Eq. 2) $r=\sqrt{{d'_{a}}^{2}+{d'_{v}}^{2}+{d'_{d}}^{2}}$
(Eq. 3) $\vartheta=\arccos\left(\frac{d'_{d}}{r}\right),\,\, \varphi=\arctan\left(\frac{d'_{v}}{d'_{a}}\right)$ - Cartesian-Spherical transformation 이후, radial distance $r$을 $[0,1]$ range로 scale 해 emotion intensity를 normalize 함
- 여기서 min-max normalization process는 interquartile range technique을 사용
- 추가적으로 directional angle $\vartheta,\varphi$를 각각 A, V, D axis의 positive/negative direction으로 정의되는 8개의 octant로 segmenting 하여 emotion style을 quantize 함

- Spherical Emotion Encoder
- Spherical emotion encoder는 spherical emotion vector space와 emotion ID를 blend 하여 spherical emotion embedding을 구성함
- 먼저 projection layer를 통해 emotion class embedding과 emotion style vector의 dimension을 align 함
- 이후 해당 projection을 concatenate 하고 softplus activation과 layer normalization (LN)을 적용함
- 최종적으로 spherical emotion embedding $\mathbf{h}_{emo}$는 다음과 같이 projected emotion intensity vector에 merge 됨:
(Eq. 4) $\mathbf{h}_{emo}=\text{LN}(\text{softplus}(\text{concat}(\mathbf{h}_{sty},\mathbf{h}_{cls}))) +\mathbf{h}_{int}$
- $\mathbf{h}_{sty}, \mathbf{h}_{int}, \mathbf{h}_{cls}$ : 각각 emotional style vector, emotional intensity vector, emotional class embedding에 대한 projection layer의 output
- Dual Conditional Adversarial Training
- EmoSphere-TTS의 합성 품질을 개선하기 위해, multiple CNN-based discriminator를 도입해 adversarial training을 수행함
- 해당 discriminator는 multiple stacked 2D-convolutional layer와 fully connected (FC) layer로 구성된 Conv2D stack을 활용함
- Input으로는 서로 다른 length $t$의 random window를 가지는 random mel-spectrogram clip을 사용 - 논문은 GANSpeech를 따라 emotion, speaker embedding을 활용하여 multi-aspect characteristic을 capture 함
- 여기서 한 Conv2D stack은 mel-spectrogram clip만 receive 하고 나머지 stack은 condition embedding과 mel-spectrogram clip의 combination을 receive 함
- Concatenation을 위해 mel-spectrogram clip의 length와 match 하도록 condition embedding은 extend 됨 - 결과적으로 discriminator $D$, generator $G$에 대한 loss function $\mathcal{L}$은:
(Eq. 5) $\displaystyle \mathcal{L}_{D}=\sum_{c\in \{spk,emo\}}\sum_{t}\mathbb{E} [(1-D_{t}(y_{t},c))^{2}+D_{t}(\hat{y}_{t},c)^{2}]$
(Eq. 6) $\displaystyle \mathcal{L}_{G}=\sum_{c\in \{spk, emo\}}\sum_{t}\mathbb{E}[(1-D_{t}(\hat{y}_{t},c))^{2}]$
- $y_{t}, \hat{y}_{t}$ : 각각 ground-truth, generated mel-spectrogram
- $c$ : condition type
- 여기서 한 Conv2D stack은 mel-spectrogram clip만 receive 하고 나머지 stack은 condition embedding과 mel-spectrogram clip의 combination을 receive 함
- 해당 discriminator는 multiple stacked 2D-convolutional layer와 fully connected (FC) layer로 구성된 Conv2D stack을 활용함
- TTS Model
- Emotion style, intensity information을 제공하는 emotion spherical vector를 제외한 나머지 architecture는 FastSpeech2의 구성을 따름
- 이때 speaker ID는 다양한 speaker characteristic을 나타내기 위해 embedding $\mathbf{h}_{spk}$에 mapping 되고, speaker/emotion embedding을 concatenate 하여 variance adaptor로 전달됨
- 추론 시에는 manual style, intensity vector를 사용하여 emotional expression을 control 함
- 결과적으로 spherical emotion vector space에서 emotion style과 intensity를 manipulate 함으로써 다양한 emotion을 반영 가능
3. Experiments
- Settings
- Dataset : Emotional Speech Dataset (ESD)
- Comparisons : FastSpeech2
- Results
- Model Performance
- 전체적인 성능 측면에서 EmoSphere-TTS가 가장 우수한 성능을 달성함

- Emotion Intensity Controllability
- Relative attribute는 intensity를 control 하는데 효과적이지만, intensity가 증가함에 따라 pitch도 함께 증가함
- Scaling factor는 sad emotion에서는 뛰어난 성능을 보이지만, static emotion에 대해서는 낮은 성능을 보임
- 그에 비해 EmoSphere-TTS는 여러 emotion에 대해 안정적인 성능을 달성함
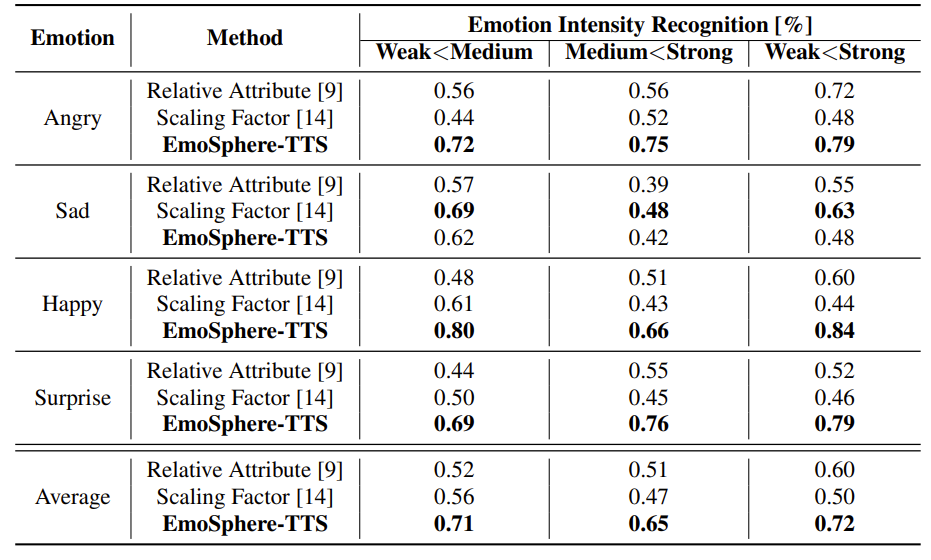
- 한편으로 relative attribute에서 emotion label만 고려하는 경우 subtle emotional nuance를 capture 하기 어렵고 uniform style로 reduce 될 수 있음
- 반면 EmoSphere-TTS는 주어진 intensity scale에 따라 적절한 pitch를 모델링함

- Emotion Style Shift
- Style vector가 shifting 되는 경우, emotion intensity pattern이 shifted axis에 따라 변화함
- 즉, spherical emotion vector는 다양한 emotional expression을 반영하고 detailed manipulation을 제공함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글