

티스토리 뷰
Paper/TTS
[Paper 리뷰] Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation
feVeRin 2024. 2. 23. 09:41반응형
Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation
- Text-to-Speech 모델은 주어진 speaker에서 나온 few audio sample 만을 사용하여 고품질 음성을 합성할 수 있어야 함
- StyleSpeech
- 고품질 합성이 가능하고 새로운 speaker에 대해 효과적으로 adaptaion 하는 TTS 모델
- Reference에서 추출된 style에 따라 text input의 gain과 bias를 align 하는 Style-Adaptive Layer Normalization을 도입
- Meta-StyleSpeech
- 새로운 speaker에 대한 StyleSpeech의 adaptation을 향상하기 위해 style prototype으로 학습된 discriminator를 도입
- Episodic training을 적용하여 meta-learning 방식으로 확장
- 새로운 speaker에 대한 StyleSpeech의 adaptation을 향상하기 위해 style prototype으로 학습된 discriminator를 도입
- 논문 (ICML 2021) : Paper Link
1. Introduction
- 대부분의 text-to-speech (TTS) 모델은 주어진 text에서 single speaker의 음성을 합성하는 것을 목표로 함
- 하지만 personalized 음성 생성을 위해서는 few speech sample 만으로 주어진 speaker의 음성을 capture 할 수 있는 TTS 모델이 필요함
- 이때 인간의 음성은 expressive하고 speaker identity와 prosody 같은 다양한 factor를 포함하고 있음 - 따라서 TTS 모델은 unseen speaker에 adapt하고 multiple speaker의 음성을 합성할 수 있어야 함
- 이를 해결하기 위해 다양한 speaker의 음성으로 구성된 dataset을 기반으로 pre-train을 수행하고 target speaker에 대해 fine-tuning 하는 방식을 주로 활용함
- BUT, target speaker의 음성을 얻기 어렵고 대량의 fine-tuning step이 필요한 한계가 있음 - Reference audio를 사용하여 speaker identity, prosody, style 등을 capture 하는 latent vector를 추출할 수도 있음
- Text input 외에도 주어진 speaker에서 추출된 latent style vector를 기반으로 conditioned speech를 생성함
- 이러한 style-based 방식은 fine-tuning 없이 우수한 성능을 얻을 수 있지만, source dataset에 크게 의존하기 때문에 새로운 speaker에 대한 adaptation 성능이 낮음
- 이를 해결하기 위해 다양한 speaker의 음성으로 구성된 dataset을 기반으로 pre-train을 수행하고 target speaker에 대해 fine-tuning 하는 방식을 주로 활용함
- 한편 meta-learning은 학습된 모델이 few sample 만으로 새로운 task에 빠르게 adapt 할 수 있도록 함
- 이러한 특성으로 few-shot generative model에서 meta-learning이 적용되고 있음
- BUT, 대부분의 few-shot approach는 이미지 domain을 대상으로 하기 때문에 TTS 모델에 직접 적용하기 어려움
- 하지만 personalized 음성 생성을 위해서는 few speech sample 만으로 주어진 speaker의 음성을 capture 할 수 있는 TTS 모델이 필요함
-> 그래서 multi-speaker adaptive TTS를 위해 StyleSpeech를 제안하고, meta-learning을 통해 adaptation 성능을 향상한 Meta-StyleSpeech로 확장
- StyleSpeech & Meta-StyleSpeech
- StyleGAN의 방법론을 활용하여 StyleSpeech를 구성
- Reference audio에서 추출된 style vector에 따라 text input의 gain과 bias를 align 하는 Style-Adaptive Layer Normalization (SALN)을 도입 - Adaptation 성능 향상을 위해, discriminator로 meta-learning을 수행하여 Meta-StyleSpeech로 확장
- 각 episode 마다 one-shot adaptation case를 simulation하여 episodic training을 수행
- Adversarial loss를 포함한 style / phoneme discriminator를 학습
- 이때 style discriminator는 generator가 각 speaker의 음성을 생성하여, speaker identity를 embedded 하는 correct style prototype에 가까워지도록 enforce 하는 style prototype set를 학습
- StyleGAN의 방법론을 활용하여 StyleSpeech를 구성
< Overall of StyleSpeech & Meta-StyleSpeech >
- Short-length reference audio에서 추출된 style로 음성을 합성하는 multi-speaker adaptive TTS 모델인 StyleSpeech를 제시
- Style prototype과 episodic meta-learning을 활용한 phoeneme / style discriminator를 사용하여 Meta-StyleSpeech로 확장
- 결과적으로 multi-speaker TTS 및 one-shot adaptation에 대해 우수한 성능을 달성
2. StyleSpeech
- Multi-Speaker generation을 위한 StyleSpeech는, mel-style encoder와 generator로 구성됨
- Mel-Style Encoder
- Mel-Style Encoder $Enc_{s}$는 reference speech $X$를 input으로 사용
- Mel-style encoder는 speaker ID와 주어진 음성 $X$의 style을 포함하는 vector $w \in \mathbb{R}^{N}$을 추출하는 것을 목표로 함
- Mel-style encoder는 크게 세 부분으로 구성됨
- Spectral processing
- Mel-spectrogram을 fully-connected layer에 input하여 mel-spectrogram의 각 frame을 hidden sequence로 변환 - Temporal processing
- 이후 gated CNN을 사용하여 주어진 음성에서 sequential information을 capture - Multi-head self-attention
- Global information을 encoding하기 위해 residual connection이 있는 multi-head self-attention을 적용
- 짧은 sample에서도 style information을 잘 추출할 수 있도록 frame-level에서 attention을 적용
- 이후 self-attention의 output을 temporally average 하여 1D style vector $w$를 얻음
- Spectral processing
- Generator
- Generator $G$는 phoneme (or text) sequence $t$와 style vector $w$가 주어지면 음성 $\tilde{X}$를 생성하는 것을 목표로 함
- 이를 위해 FastSpeech2를 기반으로 generator architecture를 구성
- Generator는 크게 세 부분으로 구성됨
- Phoneme Encoder
- Phoneme encoder는 phoneme sequence를 hidden phoneme sequence로 변환하는 역할 - Variance Adaptor
- Variance adaptor는 phoneme-level의 pitch, energy와 같은 다양한 variance를 예측함
- 추가적으로 hidden phoneme sequence의 length를 speech frame length로 regulate 하기 위해 각 phoneme의 duration을 예측 - Mel-spectrogram Decoder
- Length-regulated phoneme hidden sequence를 mel-spectrogram sequence로 변환하는 역할
- Phoneme Encoder
- 구조적으로 phoneme encoder와 mel-spectrogram decoder는 모두 Feed-Forward Transformer (FFT) block으로 구성됨
- BUT, FastSpeech2 기반의 generator는 다양한 speaker에 대한 음성을 생성하지 못하므로, multi-speaker를 위한 새로운 component가 필요
- Style-Adaptive Layer Normalization
- 일반적으로 style vector는 단순한 encoder output이나 decoder input과의 concatentation / summation을 통해 generator에 제공됨
- 논문에서 제시하는 Style-Adapative Layer Normalization (SALN)은 이와 대조적인 방식을 사용 - SALN은 style vector $w$를 receive하여 input feature vector의 gain과 bias를 예측함
- $H$가 vector의 dimensionality인 feature vector $h = (h_{1},h_{2},...,h_{H})$가 주어지면, normalized vector $y=(y_{1}, y_{2}, ..., y_{H})$는 다음과 같이 유도됨:
(Eq. 1) $y=\frac{h-\mu}{\sigma}$
- $\mu=\frac{1}{H}\sum_{i=1}^{H}h_{i}, \,\,\,\,\, \sigma = \sqrt{\frac{1}{H}\sum_{i=1}^{H}(h_{i}-\mu)^{2}} $ - 이후 style vector $w$에 대한 gain과 bias를 계산:
(Eq. 2) $SALN(h,w) = g(w)\cdot y +b(w)$
- $H$가 vector의 dimensionality인 feature vector $h = (h_{1},h_{2},...,h_{H})$가 주어지면, normalized vector $y=(y_{1}, y_{2}, ..., y_{H})$는 다음과 같이 유도됨:
- LayerNorm의 fixed gain, bias와 달리 $g(w),b(w)$는 style vector를 기반으로 normalize 된 input feature의 scaling과 shifting을 adaptive 하게 수행할 수 있음
- 따라서 StyleSpeech는 phoneme encoder와 mel-spectrogram decoder에서, FFT block의 LayerNorm을 SALN으로 대체
- 이때 style vector를 bias와 gain으로 변환하는 affine layer는 fully-connected layer를 사용 - 결과적으로 SALN을 사용함으로써 generator는 phoneme input 외에 reference audio sample이 주어지면, multiple speaker에 대한 다양한 style을 합성할 수 있음
- 일반적으로 style vector는 단순한 encoder output이나 decoder input과의 concatentation / summation을 통해 generator에 제공됨
- Training
- Training process에서,
- Generator로 합성된 mel-spectrogram과 ground-truth mel-spectrogram 사이의 reconstruction loss를 최소화하여 generator와 mel-style encoder가 최적화됨
- 따라서 다음의 $L_{1}$ distance를 loss로 사용:
(Eq. 3) $\tilde{X}=G(t,w) \,\,\, w= Enc_{s}(X)$
(Eq. 4) $\mathcal{L}_{recon} = \mathbb{E}\left[ || \tilde{X} - X ||_{1} \right]$
- $\tilde{X}$ : phoneme input $t$와 ground-truth mel-spectrogram $X$에서 추출된 style vector $w$로 생성되는 mel-spectrogram

3. Meta-StyleSpeech
- StyleSpeech는 SLAN을 활용하여 새로운 speaker의 음성에 adapt 할 수 있지만, 분포가 shift 된 unseen speaker에 대해서는 generalize 되지 않을 수 있음
- 특히 length가 짧은 audio sample의 경우 unseen speaker를 따르는 음성을 합성하기 더욱 어려움
- 따라서 unseen speaker에 대한 adaptation 성능을 향상하기 위해 meta-learning을 활용한 Meta-StyleSpeech를 구성 - Episodic training을 활용하여 새로운 speaker에 대한 one-shot learning을 simulation
- 각 episode에서 target speaker $i$로부터 하나의 support (speech, text) sample $(X_{s}, t_{s})$와 하나의 query text $t_{q}$를 random sampling 함
- 이를 통해 query text $t_{q}$와 support speech $X_{s}$에서 추출된 style vector $w_{s}$로부터 query speech $\tilde{X}_{q}$를 생성하는 것을 목표로 함
- 이때 ground-truth mel-spectrogram을 사용할 수 없기 때문에, $\tilde{X}_{q}$에 reconstruction loss를 사용할 수 없음
- 이를 해결하기 위해 2개의 discriminator (style / phoneme)으로 구성된 additional adversarial network를 도입
- 특히 length가 짧은 audio sample의 경우 unseen speaker를 따르는 음성을 합성하기 더욱 어려움
- Discriminators
- Style discriminator $D_{s}$는 음성이 target speaker의 음성을 따르는지 여부를 예측함
- Discriminator는 style prototype set $S =\{s_{i}\}^{K}_{i=1}$을 포함한다는 것을 제외하면, mel-style encoder와 유사한 architecture를 가짐
- $s_{i} \in \mathbb{R}^{N}$ : $i$-th speaker의 style prototype
- $K$ : training set의 speaker 수 - Style vector $w_{s} \in \mathbb{R}^{N}$이 input으로 주어지면,
- style prototype $s_{i}$는 다음의 classification loss로 학습됨:
(Eq. 5) $\mathcal{L}_{cls}=-\log \frac{\exp(w^{T}_{s}s_{i})}{\sum_{i'}\exp(w_{s}^{T}s_{i'})}$ - 구체적으로는, style vector와 모든 style prototype 사이의 dot product를 계산하여 style logit을 생성하고, style prototype이 target speaker의 common style을 represent 하도록 하는 cross-entropy loss를 따름
- style prototype $s_{i}$는 다음의 classification loss로 학습됨:
- 이후 style discriminator는 생성된 음성 $\tilde{X}_{q}$를 $M$-dimensional vector $h(\tilde{X}_{q})\in \mathbb{R}^{N}$에 mapping 하고, style prototype을 사용하여 single scalar를 계산
- 이때 생성된 음성을 각 speaker의 style prototype 주변에 gathering 되도록 enforce 함
- 이를 통해 generator는 single short reference sample에서 target speaker의 common style을 학습할 수 있음 - Style discriminator의 output은 다음과 같이 계산됨:
(Eq. 6) $D_{s}(\tilde{X}_{q},s_{i})=w_{0}s_{i}^{T}Vh(\tilde{X}_{q})+b_{0}$
- $V \in \mathbb{R}^{N \times M}$ : linear layer, $w_{0}, b_{0}$ : learnable parameter - 여기서 $D_{s}$의 discriminator loss는:
(Eq. 7) $\mathcal{L}_{D_{s}}=\mathbb{E}_{t,w,s_{i}\sim S}\left[ (D_{s}(X_{s},s_{i})-1)^{2}+D_{s}(\tilde{X}_{q},s_{i})^{2}\right]$
- 기존 GAN의 binary cross-entropy term을 least square loss로 대체하는 LS-GAN loss를 따름
- 이때 생성된 음성을 각 speaker의 style prototype 주변에 gathering 되도록 enforce 함
- Discriminator는 style prototype set $S =\{s_{i}\}^{K}_{i=1}$을 포함한다는 것을 제외하면, mel-style encoder와 유사한 architecture를 가짐
- Phoneme discriminator $D_{t}$는 $\tilde{X}_{q}$와 $t_{q}$를 input으로 하고, phoneme sequence $t_{q}$를 condition으로 하여 생성된 음성과 ground-truth 음성을 distinguish 함
- Phoneme discriminator는 fully-connected layer로 구성되고 frame-level에서 적용됨
- 각 phoneme duration을 알고 있으므로, mel-spectrogram의 각 frame을 해당 phoneme과 concatenate 가능
- 이후 discriminator는 각 frame에 대한 scalar를 계산하고, 평균하여 single scalar를 얻음 - 따라서 $D_{t}$에 대한 final discriminator loss는:
(Eq. 8) $\mathcal{L}_{D_{t}}=\mathbb{E}_{t,w}\left[ (D_{t}(X_{s},t_{s})-1)^{2}+D_{t}(\tilde{X}_{q},t_{q})^{2}\right]$
- Phoneme discriminator는 fully-connected layer로 구성되고 frame-level에서 적용됨
- Query speech에 대한 generator loss는,
- 각 discriminator의 adversarial loss 합으로 정의됨:
(Eq. 9) $\mathcal{L}_{adv}=\mathbb{E}_{t,w,s_{i}\sim S}\left[ (D_{s}(G(t_{q},w_{s}),s_{i})-1)^{2}\right]+\mathbb{E}_{t,w}\left[ (D_{t}(G(t_{q},w_{s}),t_{q})-1)^{2}\right]$ - 추가적으로 support speech에 대해 reconstruction loss를 적용하여 생성된 mel-spectrogram의 품질을 향상:
(Eq. 10) $\mathcal{L}_{recon}=\mathbb{E}\left[ ||G(t_{s},w_{s})-X_{s}||_{1}\right]$
- 각 discriminator의 adversarial loss 합으로 정의됨:
- Episodic Meta-Learning
- Meta-StyleSpeech의 meta-learning을 위해,
- $\mathcal{L}_{recon}, \mathcal{L}_{adv}$ loss를 최소화하는 generator / mel-style encoder와 $\mathcal{L}_{D_{s}}, \mathcal{L}_{D_{t}}, \mathcal{L}_{cls}$ loss를 최소화하는 discriminator 업데이트를 번갈아서 수행
- 따라서 최종적인 meta-learning loss는:
(Eq. 11) $\mathcal{L}_{G} =\alpha \mathcal{L}_{recon}+\mathcal{L}_{adv}$
(Eq. 12) $\mathcal{L}_{D} = \mathcal{L}_{D_{s}}+\mathcal{L}_{D_{t}}+\mathcal{L}_{cls}$
- $\alpha =10$으로 설정

4. Experiments
- Settings
- Dataset : LibriTTS, VCTK
- Comparisons : DeepVoice3, GMVAE, FastSpeech2 (multi-speaker)
- Evaluation on Trained Speakers
- LibriTTS dataset을 통해 seen speaker에 대한 합성 품질을 비교해 보면, 제안된 StyleSpeech와 Meta-StyleSpeech가 가장 우수한 합성 품질을 보임

- Seen speaker와 reference speech에 대한 similarity를 비교해 보면, 마찬가지로 StyleSpeech, Meta-StyleSpeech가 가장 높은 similarity를 보임

- Unseen Speaker Adaptation
- VCTK dataset을 통해 unseen speaker에 대한 합성 품질을 비교해 보면, Meta-StyleSpeech가 가장 우수한 것으로 나타남

- Unseen speaker에 대한 similarity를 비교해 보면, Meta-StyleSpeech는 어떤 length의 reference에 대해서도 가장 뛰어난 합성 성능을 보임
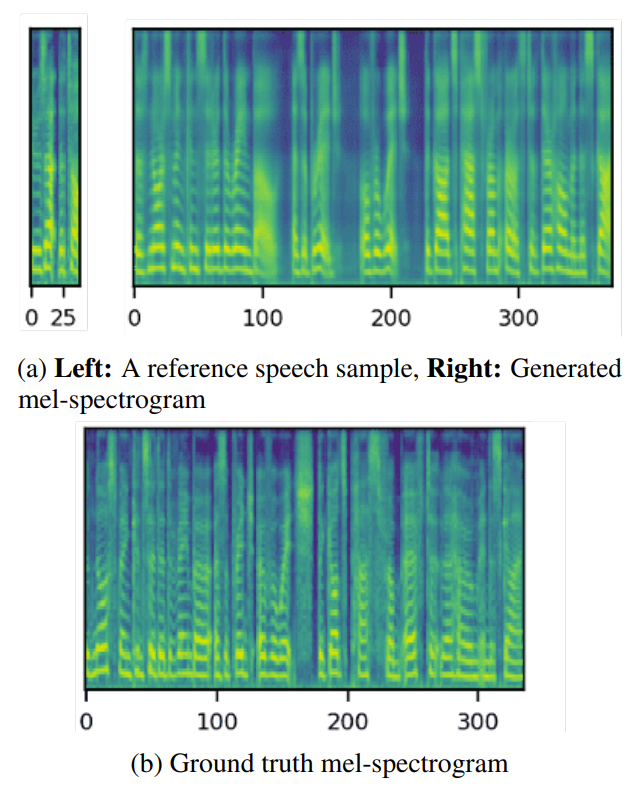
- 특히 Meta-StyleSpeech는 1초 미만의 reference speech로도 뛰어난 adaptation 성능을 보임

- 실제로 1초 미만의 reference로 생성된 음성의 mel-spectrogram을 확인해 보면,
- Meta-StyleSpeech는 sharp harmonics와 well-resolved formant를 가지는 mel-spectrogram을 생성할 수 있음
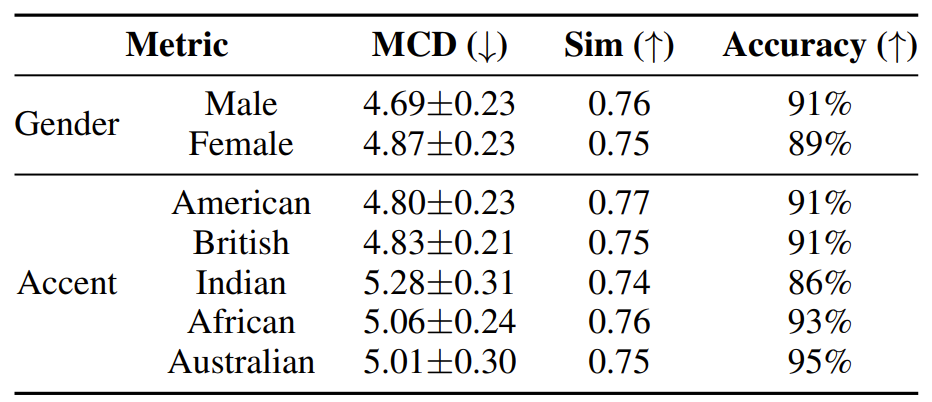
- Gender, accent 등 다양한 style에 대한 adaptation 성능을 확인해 보면,
- Meta-StyleSpeech는 gender에 관계없이 균형적인 결과를 달성함
- 모든 accent에 대해서도 높은 adaptation 성능을 보임
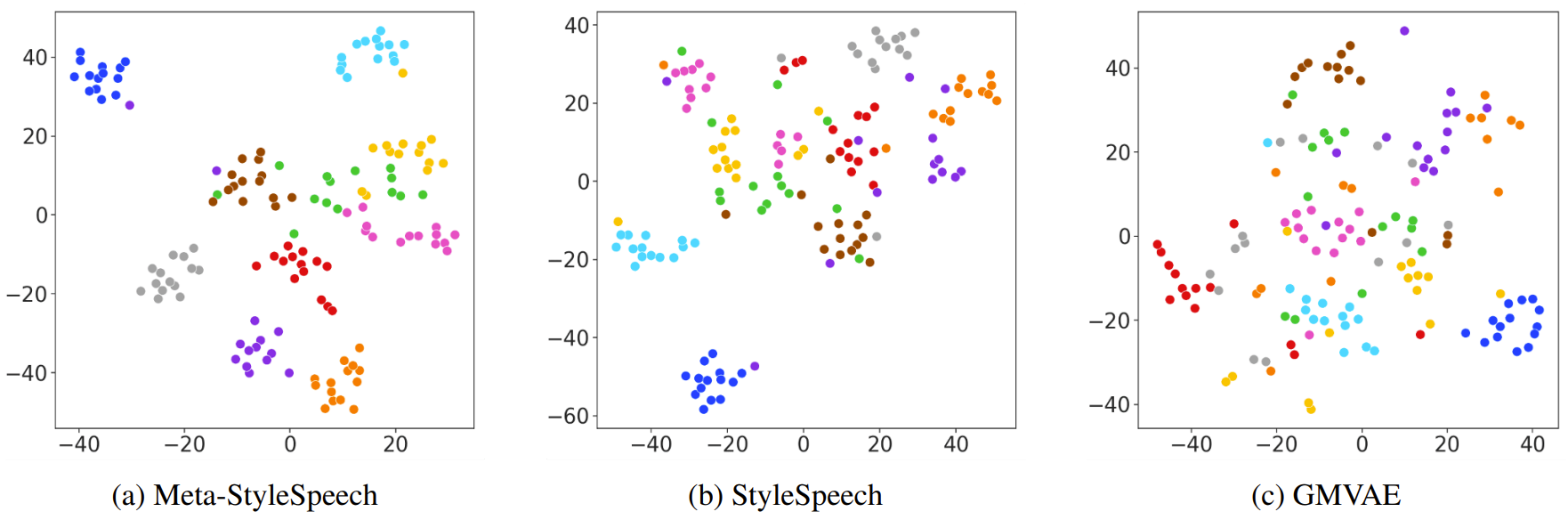
- Meta-learning의 효과를 확인하기 위해 style vector를 시각화
- 이를 위해 unseen speaker의 style vector에 대해 t-SNE projection을 수행
- 결과적으로 StyleSpeech는 GMVAE와 비교하여 style vector를 더 명확하게 separate 할 수 있음
- 나아가 Meta-StyleSpeech는 더 나은 clustered style vector를 얻을 수 있음
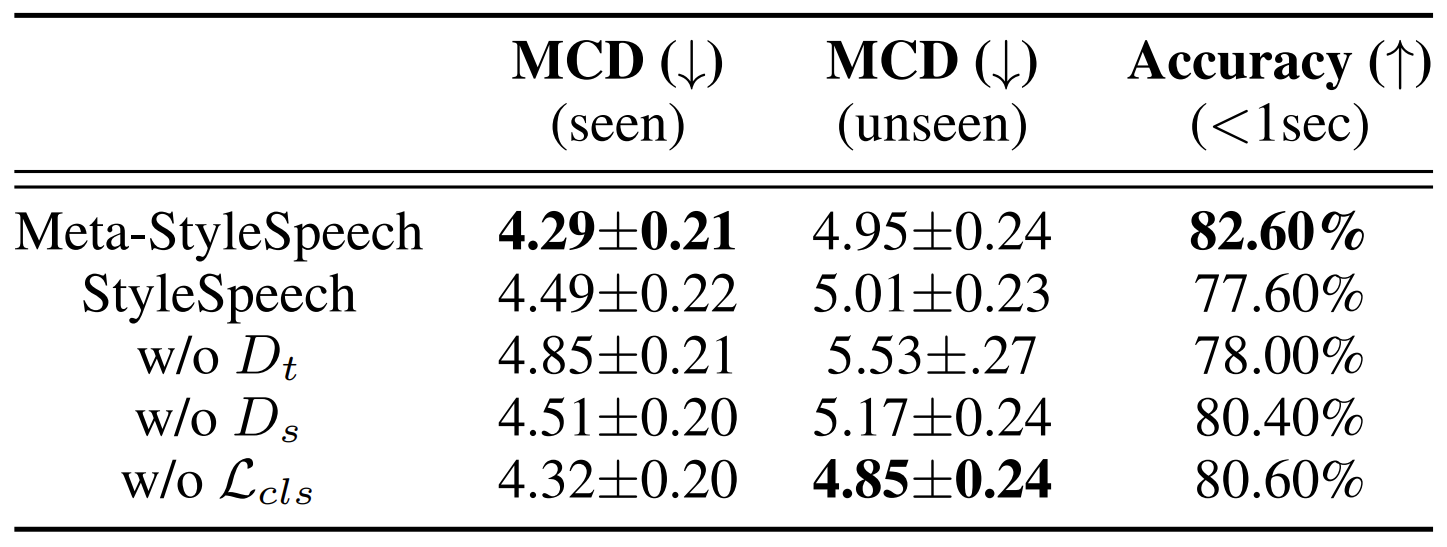
- Ablation Study
- Ablation study 결과를 확인해 보면,
- Text discriminator를 제거한 경우, 품질과 adaptation ability가 모두 저하됨
- Style discriminator와 Style prototype을 제거한 경우, unseen speaker adaptation에 대한 성능이 저하됨
반응형
'Paper > TTS' 카테고리의 다른 글
댓글