

티스토리 뷰
Paper/TTS
[Paper 리뷰] Multi-SpectroGAN: High-Diversity and High-Fidelity Spectrogram Generation with Adversarial Style Combination for Speech Synthesis
feVeRin 2024. 7. 28. 11:12반응형
Multi-SpectroGAN: High-Diversity and High-Fidelity Spectrogram Generation with Adversarial Style Combination for Speech Synthesis
- 일반적으로 text-to-speech에서 adversarial feedback 만으로는 generator를 training 하는데 충분하지 않으므로 추가적인 reconstruction loss가 요구됨
- Multi-SpectroGAN
- Generator의 self-supervised hidden representation을 conditional discriminator로 conditioning 하여 adversarial feedback만으로 model을 training 함
- 추가적으로 unseen style에 대한 generalization을 위해 Adversarial Style Combination (ASC)를 도입해 multiple mel-spectrogram에서 combined style embedding을 학습
- 논문 (AAAI 2021) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 대량의 high-quality text-audio data가 없는 경우 style control/transfer가 어려움
- 이를 위해 FastSpeech와 같이 knowledge distillation을 활용할 수도 있지만, training pipeline이 복잡하다는 한계가 있음
- 한편으로 Generative Adversarial Network (GAN)-based TTS의 경우 adversarial feedback을 통해 음성 품질을 크게 향상할 수 있음
- 대표적으로 EATS는 input phoneme에서 raw waveform을 생성하여 adversarial feedback과 prediction loss를 통해 end-to-end training 됨 - BUT, adverasrial training을 위해서는 TTS model에서 추가적인 prediction loss를 계산해야 한다는 단점이 있음
-> 그래서 adversarial loss 만으로 training 되는 Mel-SpectroGAN을 제안
- Multi-SpectroGAN
- Prediction loss에 대한 의존성을 제거하기 위해 end-to-end learned frame-level condition과 conditional discriminator를 도입
- Discriminator는 frame-level condition을 사용하여 mel-spectrogram으로 변환되는 feature를 distinguish 하도록 학습되어 generator가 high-fidelity의 mel-spectrogram을 생성하도록 함 - Mixed speaker embedding으로 합성된 mel-spectrogram의 latent representation을 학습할 수 있는 Adversarial Style Combination을 적용
- Mixed-style mel-spectrogram의 adversarial feedback을 통해 Multi-SpectroGAN은 multiple style을 interpolate 하고, unseen speaker에 대한 natural audio를 합성 가능
- Prediction loss에 대한 의존성을 제거하기 위해 end-to-end learned frame-level condition과 conditional discriminator를 도입
< Overall of Multi-SpectroGAN >
- End-to-End learned frame-level condition과 conditional discriminator를 통해 prediction loss 없이 mel-spectrogram을 합성
- Adversarial Style Combination을 통해 mel-spectrogram의 mixed style을 학습
- 결과적으로 기존보다 뛰어난 합성 품질을 달성
2. Method
- Multi-SpectroGAN은 speaking style을 mixing, controlling 하여 high-diversity mel-spectrogram을 합성할 수 있는 generator를 구축하는 것을 목표로 함
- 이를 위해 multiple mel-spectrogram에서 combined speaker embedding의 latent representation을 학습할 수 있는 Adversarial Style Combination을 도입
- Ground-truth가 없는 randomly mixed style을 학습하기 위해 end-to-end learned frame-level conditional discriminator를 활용
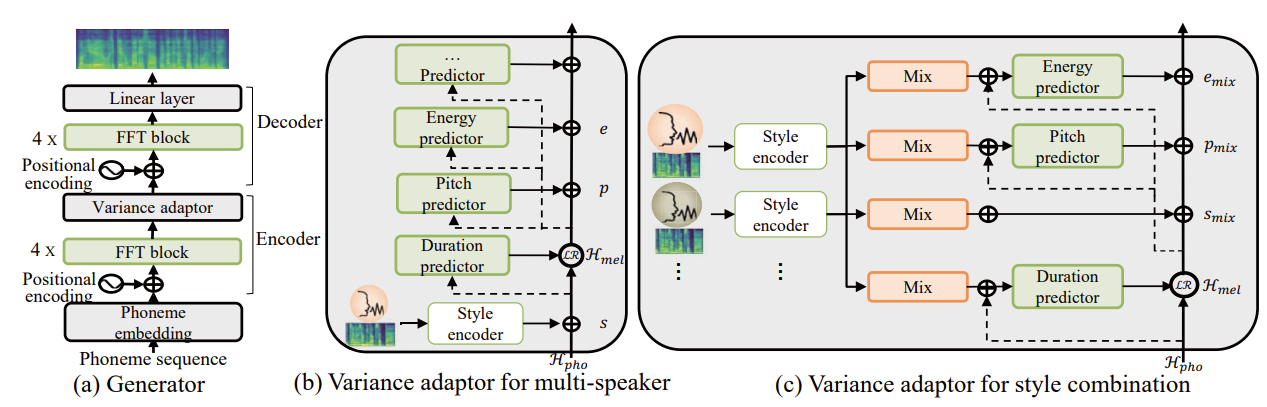
- Generator
- Multi-SpectroGAN은 FastSpeech2를 기반으로 variance adaptor $f(\cdot,\cdot)$, decoder $g(\cdot)$을 사용함
- 구조적으로는 4개의 Feed-Forward Transformer (FFT) block으로 구성된 phoneme encoder와 decoder를 활용
- 이후 multi-speaker model로 확장하여 mel-spectrogram에서 fixed-dimensional style vector를 생성하는 style encoder를 구축
- Style Encoder
- Style encoder는 $3\times 1$ filter와 $2\times 2$ stride, dropout, ReLU activation, Layer Normalization을 가지는 2D convolution network로 구성됨
- 추가적으로 Gated Recurrent Unit layer를 사용해 final output을 single style vector로 compress 함 - Length regulator, variance adaptor의 conditioning 이전에 output은 style information을 추가하기 위해, phoneme encoder와 동일한 dimension으로 project 되고 tanh activation을 추가함
- 그러면 style encoder를 $E_{s}(\cdot)$이라고 했을 때, 얻어지는 style embedding은:
(Eq. 1) $\mathbf{s}=E_{s}(\mathbf{y})$
- $\mathbf{s}$ : style encoder $E_{s}$를 통해 mel-spectrogram $\mathbf{y}$로부터 추출된 style embedding
- Style encoder는 $3\times 1$ filter와 $2\times 2$ stride, dropout, ReLU activation, Layer Normalization을 가지는 2D convolution network로 구성됨
- Style-Conditioned Variance Adaptor
- Multi-SpectroGAN은 FastSpeech2의 variance adaptor를 사용하여 variance information을 추가함
- Mel-spectrogram에서 예측된 style embedding을 phoneme hidden sequence $\mathcal{H}_{pho}$에 추가하여 variance adaptor는 각 speaker의 unique style로 variance information을 예측할 수 있음
- 먼저 phoneme-side FFT network를 phoneme hidden representation을 생성하는 phoneme encoder $E_{p}(\cdot)$이라고 하면:
(Eq. 2) $\mathcal{H}_{pho}=E_{p}(\mathbf{x}+\text{PE}(\cdot))$
- $\mathbf{x}$ : phoneme embedding sequence, $\text{PE}(\cdot)$ : triangle positional embedding - 여기서 Tacotron2에서 target duration sequence $\mathcal{D}$를 추출하여 phoneme hidden sequence의 length를 mel-spectrogram의 length에 mapping 하면:
(Eq. 3) $\mathcal{H}_{mel}=\mathcal{LR}(\mathcal{H}_{pho},\mathcal{D})$ - Duration predictor는 Mean-Square Error (MSE)를 통해 log-scale의 length를 예측함:
(Eq. 4) $\mathcal{L}_{duration}=\mathbb{E}[|| \log (\mathcal{D}+1)-\hat{\mathcal{D}}||_{2}]$
(Eq. 5) $\hat{\mathcal{D}}=\text{DurationPredictor}(\mathcal{H}_{pho},\mathbf{s})$
- 먼저 phoneme-side FFT network를 phoneme hidden representation을 생성하는 phoneme encoder $E_{p}(\cdot)$이라고 하면:
- 추가적으로 각 mel-spectrogram frame에 대해 target pitch sequence $\mathcal{P}$와 target energy sequence $\mathcal{E}$를 사용함
- 이때 각 information의 outlier를 제거하고 normalized value를 사용
- 이후 256 value로 divide 되는 quantized $F0$와 energy sequence embedding $\mathbf{p},\mathbf{e}$을 추가함:
(Eq. 6) $\mathbf{p}=\text{PitchEmbedding}(\mathcal{P}),\,\, \mathbf{e}=\text{EnergyEmbedding}(\mathcal{E})$ - Pitch/energy predictor는 normalized $F0$/energy value를 예측하고, ground-truth $\mathcal{P},\mathcal{E}$와 예측된 $\hat{\mathcal{P}},\hat{\mathcal{E}}$간의 MSE로 학습됨:
(Eq. 7) $\mathcal{L}_{pitch}=\mathbb{E}[|| \mathcal{P}-\hat{\mathcal{P}}||_{2}], \,\, \mathcal{L}_{energy}=\mathbb{E}[|| \mathcal{E}-\hat{\mathcal{E}}||_{2}]$
(Eq. 8) $\hat{\mathcal{P}}=\text{PitchPredictor}(\mathcal{H}_{mel},\mathbf{s}),\,\, \hat{\mathcal{E}}=\text{EnergyPredictor}(\mathcal{H}_{mel},\mathbf{s})$
- Encoder $f(\cdot, \cdot)$은 phoneme encoder와 style-conditional variance adpator로 구성되고, variance prediction loss로 training 됨:
(Eq. 9) $\min_{f}\mathcal{L}_{var}=\mathcal{L}_{duration}+\mathcal{L}_{pitch}+\mathcal{L}_{energy}$ - Training 중에 논문은 각 information의 ground-truth value 뿐만 아니라 다양한 mel-spectrogram을 학습하기 위해 adversarial style combination을 통해 얻어진 각 information의 predicted value도 활용함
- 이때 각 informational hidden sequence의 합 $\mathcal{H}_{total}$은 mel-spectrogram을 생성하기 위해 generator $g(\cdot)$을 통해 decoder로 전달됨:
(Eq. 10) $\mathcal{H}_{total}=\mathcal{H}_{mel}+\mathbf{s}+\mathbf{p}+\mathbf{e}+\text{PE}(\cdot)$
(Eq. 11) $\hat{\mathbf{y}}=g(\mathcal{H}_{total})$
- $\hat{\mathbf{y}}$ : predicted mel-spectrogram - 한편으로 baseline model은 Mean-Absolute Error (MAE)가 포함된 다음의 reconstruction loss를 활용:
(Eq. 12) $\mathcal{L}_{rec}=\mathbb{E}[|| \mathbf{y}-\hat{\mathbf{y}}||_{1}]$
- $\mathbf{y}$ : ground-truth mel-spectrogram
- 이때 각 informational hidden sequence의 합 $\mathcal{H}_{total}$은 mel-spectrogram을 생성하기 위해 generator $g(\cdot)$을 통해 decoder로 전달됨:
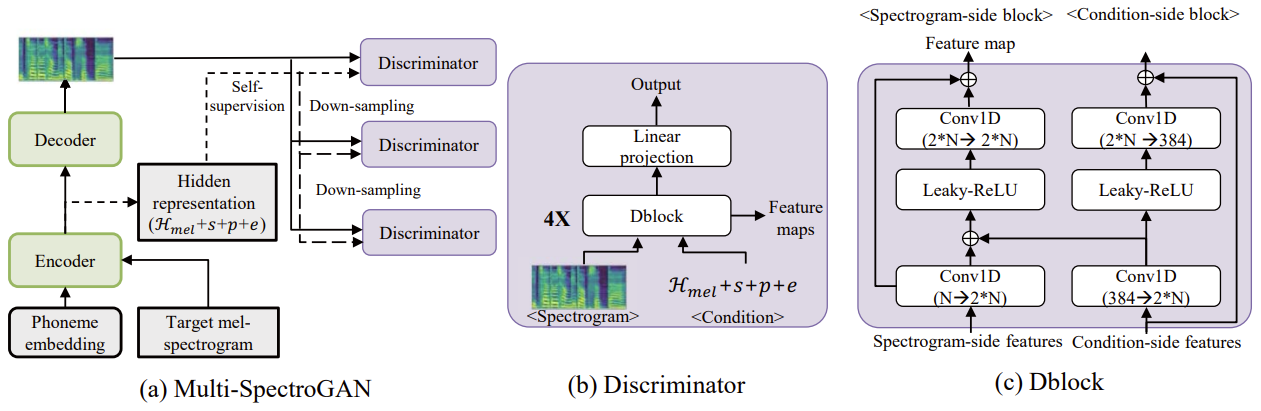
- Discriminator
- 기존의 GAN-based TTS와 달리 Multi-SpectroGAN은 ground-truth spectrogram에서 직접 loss를 계산하지 않고 text sequence에서 mel-spectrogram을 합성하도록 학습됨
- 이때 $\mathcal{L}_{rec}$ 없이 Multi-SpectroGAN을 training 하기 위해, 논문은 end-to-end learned frame-level condition과 frame-level conditional discriminator를 활용 - End-to-End Learned Frame Level Condition
- Frame-level real/generated mel-spectrogram을 distinguish 하기 위해 discriminator는 training 중에 generator에서 학습된 encoder output을 frame-level condition으로 사용함
- 이때 $\mathbf{c}$는 generator에서 학습된 linguistic, style, pitch, energy information의 합:
(Eq. 13) $ \mathbf{c}=\underset{\text{linguistic}}{\underbrace{\mathcal{H}_{mel}}} + \underset{\text{style}}{\underbrace{\mathbf{s}}}+\underset{\text{pitch}}{\underbrace{\mathbf{p}}}+\underset{\text{energy}}{\underbrace{\mathbf{e}}}$
- Frame-Level Conditional Discriminator
- 구조적으로 논문은 MelGAN과 유사한 multi-scale discriminator를 채택
- 이때 다양한 range의 linguistic, pitch, energy information에 대한 feature를 학습하는 것을 목표로 함 - 각 discriminator는 mel-spectrogram side bloock과 condition side block이 있는 4개의 Dblock으로 구성됨
- 각 block은 Leaky ReLU activation과 2-layer non-strided 1D convolutional network를 사용하여 adjacent frame information을 추출함
- 이후 condition-side block의 hidden representation이 mel-spectrogram side hidden representation에 추가되고, residual connection과 layer normalization이 각 block output에 적용됨
- Multi-SpectroGAN의 training은 Least-Sqaures GAN의 formulation을 따름
- 즉, discriminator $D_{k}$는 real spectrogram $\mathbf{y}$와 $\mathbf{x},\mathbf{y}$에서 reconstruct 된 spectrogram을 distinguish 함
- 결과적으로 encoder $f(\cdot, \cdot)$, decoder $g(\cdot)$, discriminator $D$는 다음의 loss를 통해 최적화됨:
(Eq. 14) $\min_{D_{k}}\mathbb{E}\left[|| D_{k}(\mathbf{y},\mathbf{c})-1||_{2}+|| D_{k}(\hat{\mathbf{y}},\mathbf{c})||_{2}\right],\,\,\, \forall k=1,2,3$
(Eq. 15) $\mathcal{L}_{adv}=\mathbb{E}\left[\sum_{k=1}^{3}||D_{k}(\hat{\mathbf{y}},\mathbf{c})-1 ||_{2}\right]$
- 구조적으로 논문은 MelGAN과 유사한 multi-scale discriminator를 채택
- Feature Matching
- Discriminator가 학습한 representation을 개선하기 위해 추가적으로 feature matching objective를 도입함
- Real/generated audio의 discriminator feature map 간의 MAE를 최소화하는 MelGAN과 달리, 논문에서는 각 spectrogram-side block의 feature map 간 MAE를 최소화함:
(Eq. 16) $ \mathcal{L}_{fm}=\mathbb{E}\left[\sum_{i=1}^{4}\frac{1}{N_{i}}|| D_{k}^{(i)}(\mathbf{y},\mathbf{c})-D_{k}^{(i)}(\hat{\mathbf{y}},\mathbf{c}) ||_{1}\right]$
- $D_{k}^{(i)}$ : $k$-th discriminator의 $i$-th spectorgram-side block output
- $N_{i}$ : 각 block output의 unit 수 - 그러면 generator는 다음의 objective로 training 됨:
(Eq. 17) $\min_{f,g}\mathcal{L}_{msg}=\mathcal{L}_{adv}+\lambda\mathcal{L}_{fm}+\mu\mathcal{L}_{val}$
- Adversarial Style Combination
- 논문은 unseen style로 다양한 audio signal을 생성하기 위해, multiple source speaker의 mixed style로 mel-spectrogram을 realistic 하게 만드는 Adversarial Style Combination (ASC)를 도입
- 먼저 2가지의 mixing으로써 style embedding 간의 binary selection과 서로 다른 speaker의 style embedding의 linear combination에 대한 manifold mixup을 사용:
(Eq. 18) $\mathbf {s}_{mix}=\alpha \mathbf{s}_{i}+(1-\alpha)\mathbf{s}_{j}$
- $\alpha\in\{0,1\}$ : Binary selection의 Bernoulli distribution에서 sample 됨
- $\alpha\in[0,1]$ : Manifold mixup의 $\text{Uniform}(0,1)$ distributuion에서 sample 됨 - Variance adpator는 mixed style embedding을 통해 각 information을 예측함
- Pitch/energy와는 달리 duration predictor는 early training step에서 wrong duration을 예측할 수 있으므로 randomly selected ground-truth $\mathcal{D}$를 사용
- 각 variance information은 mixed style embedding의 다양한 ratio로 예측되어 style combination을 구성함 - 이때 final mixed hidden representation은 서로 다른 mixed style의 각 variance information을 combination 하여 얻어짐:
(Eq. 19) $\mathcal{H}_{mix}=\underset{\mathbf{c}_{mix}}{\underbrace{\mathcal{H}_{mel} +\mathbf{s}_{mix}+\mathbf{p}_{mix}+\mathbf{e}_{mix}}}+\text{PE}(\cdot)$
(Eq. 20) $\hat{\mathbf{y}}_{mix}=g(\mathcal{H}_{mix})$
- $\mathbf{p}_{mix},\mathbf{e}_{mix}$ : mixed style에서 예측된 pitch/energy embedding
- $\mathbf{c}_{mix}$ : style combination으로 생성된 mel-spectrogram $\hat{\mathbf{y}}_{mix}$에 대한 frame-level condition
- Pitch/energy와는 달리 duration predictor는 early training step에서 wrong duration을 예측할 수 있으므로 randomly selected ground-truth $\mathcal{D}$를 사용
- 그러면 discriminator는 다음의 objective로 training 됨:
(Eq. 21) $\min_{D_{k}}\mathbb{E}\left[|| D_{k}(\mathbf{y},\mathbf{c})-1||_{2}+ || D_{k}(\hat{\mathbf{y}},\mathbf{c})||_{2}+ || D_{k}(\hat{\mathbf{y}}_{mix},\mathbf{c}_{mix})||_{2}\right],\,\,\, \forall k=1,2,3$ - 최종적으로 generator의 training loss는:
(Eq. 22) $\min_{f,g}\mathcal{L}_{asc}=\mathcal{L}_{adv}+\lambda \mathcal{L}_{fm}+\mu\mathcal{L}_{var}+\nu\mathcal{L}_{mix}$
(Eq. 23) $\mathcal{L}_{mix}=\mathbb{E}\left[ \sum_{k=1}^{3}|| D_{k}(\hat{\mathbf{y}}_{mix},\mathbf{c}_{mix})-1||_{2}\right]$
- 먼저 2가지의 mixing으로써 style embedding 간의 binary selection과 서로 다른 speaker의 style embedding의 linear combination에 대한 manifold mixup을 사용:
3. Experiments
- Settings
- Dataset : LJSpeech, VCTK
- Comparisons : TransformerTTS, FastSpeech, FastSpeech2
- Results
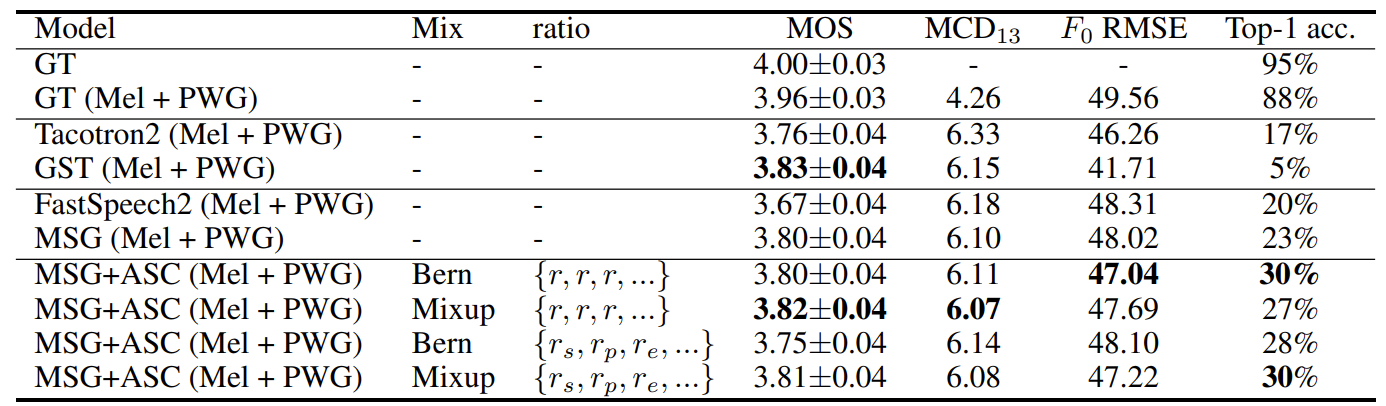
- Single-Speaker Speech Synthesis
- Single-speaker dataset에 대해 Multi-SpectroGAN (MSG)가 가장 우수한 성능을 달성함

- Downsampling size $\tau$가 작을수록 MSG는 낮은 CMOS를 보이지만, 수렴 속도는 빨라짐

- Loss function 측면에서 MSG는 reconstruction loss $\mathcal{L}_{rec}$ 없이 가장 우수한 MOS를 달성함

- Multi-Speaker Speech Synthesis
- Seen speaker의 경우, MSG+ASC 방식이 가장 우수한 성능을 달성함

- Unseen Speaker의 경우에도 논문의 MSG+ASC의 성능이 가장 뛰어남
- Ablation Study
- Discriminator의 condition에 따른 성능을 비교해 보면
- $\mathcal{H}_{mel}$이 없는 모델의 경우 전혀 training 되지 않고, pitch $\mathbf{p}$와 energy $\mathbf{e}$ 역시 naturalness에 큰 영향을 줌

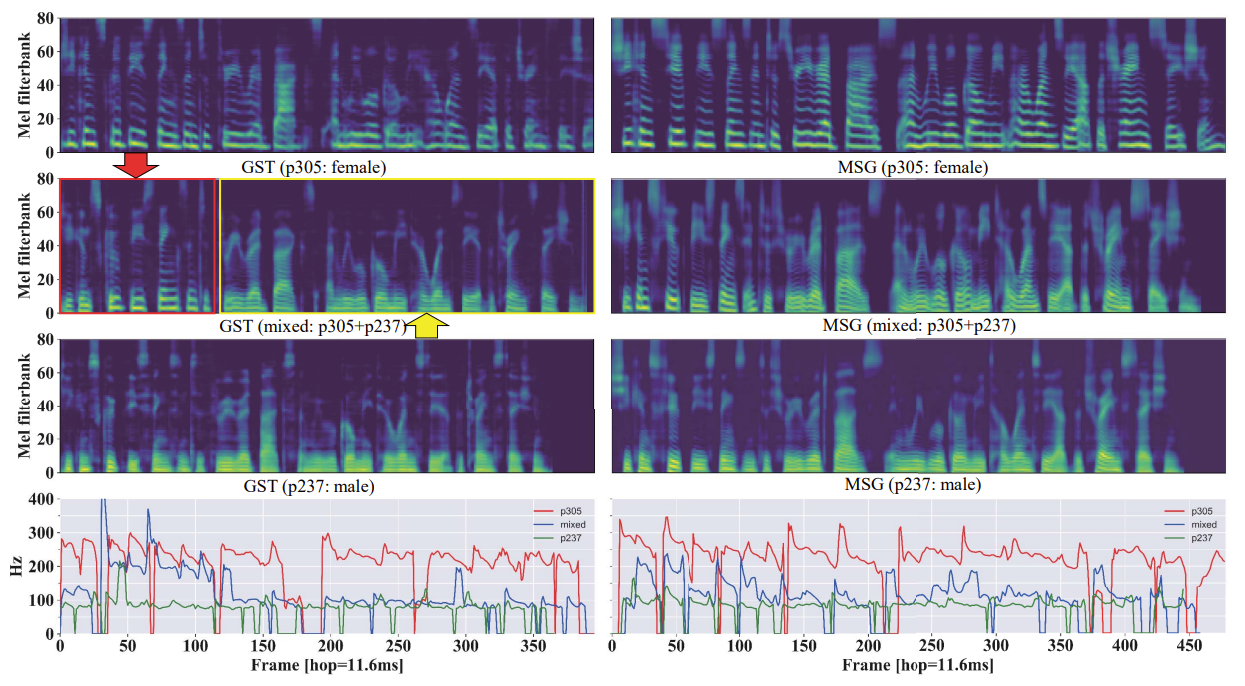
- Style Combination
- Interpolated style embedding으로 합성된 mel-spectrogram을 비교해 보면
- Attention-based autoregressive model과는 달리 MSG는 mel-spectrogram을 mixed-style embedding으로 robust 하게 합성할 수 있음
반응형
'Paper > TTS' 카테고리의 다른 글
댓글