

 [결산] 1998년도 앨범 결산
[결산] 1998년도 앨범 결산
선정 기준 : 작성자 마음대로 뽑습니다. 1998년도 앨범 결산 1. 개인적인 추천 앨범 Broder Daniel - : 강렬하고 밀도 높은 스웨덴산 얼터너티브 록 앨범입니다. 시끄러운 소음 위에서 멜로디컬한 기타를 타고 퍼져나가는 포스트-펑크의 고딕적인 감성은 왜 리스너들이 북유럽의 보석들을 찾아 헤매는지에 대한 이유를 여실히 말해줍니다. Broder Daniel - 'I'll Be Gone' 2. 올해의 국내 싱글 허클베리핀 - '보도블럭' : 후에 3호선 버터플라이로 옮겨가는 남상아의 폭발적인 보컬을 필두로 한 파괴적인 그런지 사운드가 돋보이는 싱글입니다. 세기말을 향해 달려가던 당시의 혼란스러운 세태를 반영하는 듯한 음울함 역시 빼놓을 수 없는 매력 요소입니다. 허클베리핀 - '보도블럭' 3. 올..
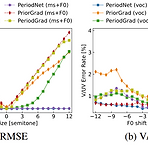 [Paper 리뷰] PeriodGrad: Towards Pitch-Controllable Neural Vocoder based on a Diffusion Probabilistic Model
[Paper 리뷰] PeriodGrad: Towards Pitch-Controllable Neural Vocoder based on a Diffusion Probabilistic Model
PeriodGrad: Towards Pitch-Controllable Neural Vocoder based on a Diffusion Probabilistic Model Diffuision-based vocoder는 고품질의 합성이 가능하고 간단한 time-domain loss로 학습할 수 있지만 pitch control이 어려움 PeriodGrad Explicit periodic signal을 auxiliary conditioning signal로써 Denoising Diffusion Probabilistic Model에 통합 Waveform의 periodic structure를 정확하게 capture 하여 pitch controllability를 향상 논문 (ICASSP 2024) : Paper Li..
 [Paper 리뷰] AudioLM: A Language Modeling Approach to Audio Generation
[Paper 리뷰] AudioLM: A Language Modeling Approach to Audio Generation
AudioLM: A Language Modeling Approach to Audio Generation 고품질 audio 생성을 위해 long-term consistency를 갖춘 language model을 활용할 수 있음 AudioLM Input audio를 discrete token sequence에 mapping 하고 해당 representation space에서 audio 생성을 language modeling으로 cast 함 Audio에 pre-train 된 masked language model의 discretized activation을 사용하여 neural audio codec의 long-term structure와 discrete code를 capture 논문 (TASLP 2023) :..
 [결산] 1997년도 앨범 결산
[결산] 1997년도 앨범 결산
선정 기준 : 작성자 마음대로 뽑습니다. 1997년도 앨범 결산 1. 개인적인 추천 앨범 The Promise Ring - : 캐치함과 불안한 이모(Emo)적 감수성이 공존하는 달콤씁쓸한 90년대 이모 팝 보석입니다. 미드웨스트 이모에 기반을 둔 센티멘탈한 기타 아르페지오는 오래전 여름날의 햇빛처럼 밝게 타오르며 아련한 향수를 불러일으킵니다. The Promise Ring - 'Red & Blue Jeans' 2. 올해의 국내 싱글 델리스파이스 - '챠우챠우' : 델리스파이스의 대표곡이자 어쩌면 전국민의 뇌리에 각인되어 있을 기막힌 도입부를 품고 있는 싱글입니다. 종종 The Cure의 'Disintegration'과 닮았다는 논란이 있기도 하지만, 분명한 것은 '챠우챠우'가 없었다면 지금의 한국 인디록..
 [Paper 리뷰] MusicLM: Generating Music From Text
[Paper 리뷰] MusicLM: Generating Music From Text
MusicLM: Generating Music From Text 주어진 text description으로부터 high-fidelity의 음악을 생성하는 Language Model을 구성할 수 있음 MusicLM Conditional music generation process를 hierarchical sequence-to-sequence modeling으로 cast 추가적으로 music-text pair를 가진 MusicCaps dataset을 공개 논문 (Google Research 2023) : Paper Link 1. Introduction Conditional neural audio generation은 text-to-speech와 lyrics-conditioned music generation,..
 [Paper 리뷰] nnSpeech: Speaker-Guided Conditional Variational Autoencoder for Zero-Shot Multi-Speaker Text-to-Speech
[Paper 리뷰] nnSpeech: Speaker-Guided Conditional Variational Autoencoder for Zero-Shot Multi-Speaker Text-to-Speech
nnSpeech: Speaker-Guided Conditional Variational Autoencoder for Zero-Shot Multi-Speaker Text-to-Speech Multi-speaker text-to-speech를 활용하기 위해서는 어려움이 많음 nnSpeech Fine-tuning 없이 하나의 adpatation utterance만을 사용하여 새로운 speaker voice를 합성할 수 있는 zero-shot multi-speaker 모델 Speaker-guided conditional vairational autoencoder를 활용하여 speaker, content information을 모두 포함하는 variable $Z$를 생성 Latent variable $Z$의 분포..