

 [Paper 리뷰] QHM-GAN: Neural Vocoder based on Quasi-Harmonic Modeling
[Paper 리뷰] QHM-GAN: Neural Vocoder based on Quasi-Harmonic Modeling
QHM-GAN: Neural Vocoder based on Quasi-Harmonic Modeling기존 end-to-end neural vocoder는 black-box nature로 인해 speech의 intrinsic structure를 revealing 하지 못하므로 고품질 합성의 한계가 있음QHM-GANQuasi-Harmonic Model을 기반으로 network architecture를 개선Speech signal을 quasi-harmonic component로 parameterize 하여 고품질 합성을 지원하고, time consumption과 network size를 절감논문 (INTERSPEECH 2024) : Paper Link1. IntroductionVocoder는 acoustic ..
 [Paper 리뷰] Diff-HierVC: Diffusion-based Hierarchical Voice Conversion with Robust Pitch Generation and Masked Prior for Zero-Shot Speaker Adaptation
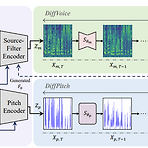
[Paper 리뷰] Diff-HierVC: Diffusion-based Hierarchical Voice Conversion with Robust Pitch Generation and Masked Prior for Zero-Shot Speaker Adaptation
Diff-HierVC: Diffusion-based Hierarchical Voice Conversion with Robust Pitch Generation and Masked Prior for Zero-Shot Speaker AdaptationVoice Conversion은 여전히 inaccurate pitch와 low speaker adaptation 문제를 가지고 있음Diff-HierVC2가지 diffusion model을 기반으로 하는 hierarchical voice conversion model- Target voice style로 $F_{0}$를 효과적으로 생성할 수 있는 DiffPitch를 도입하고,- 이후 생성된 $F_{0}$를 DiffVoice에 전달하여 target voice styl..
 [Paper 리뷰] MultiVerse: Efficient and Expressive Zero-Shot Multi-Task Text-to-Speech
[Paper 리뷰] MultiVerse: Efficient and Expressive Zero-Shot Multi-Task Text-to-Speech
MultiVerse: Efficient and Expressive Zero-Shot Multi-Task Text-to-SpeechZero-Shot Text-to-Speech를 위해서는 많은 training data가 필요하고 기존보다 cost 증가함MultiVerse기존의 data-driven method 보다 더 적은 training data를 사용하면서 zero-shot 환경에서 Text-to-Speech, Style transfer를 수행하는 multi-task modelSource-filter theory-based disentanglement를 활용하고 filter-related/source-related representation을 모델링하기 위한 prompt를 도입Prosody similar..
 [Paper 리뷰] StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion
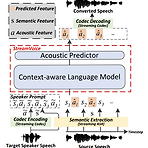
[Paper 리뷰] StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion
StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice ConversionLanguage Model을 활용하여 zero-shot voice conversion 성능을 향상할 수 있음- BUT, 기존 방식은 offline conversion으로 인해 complete source speech 만을 요구하므로 real-time application에서 활용하기 어려움StreamVoiceStreaming capability를 위해 temporal independent acoustic predictor를 포함한 fully causal context-aware Language Model을 도입- 이를 통해 comple..
 [Paper 리뷰] PL-TTS: A Generalizable Prompt-based Diffusion TTS Augmented by Large Language Model
[Paper 리뷰] PL-TTS: A Generalizable Prompt-based Diffusion TTS Augmented by Large Language Model
PL-TTS: A Generalizable Prompt-based Diffusion TTS Augmented by Large Language ModelStyle-controlled Text-to-Speech를 위해 text style description을 사용할 수 있음PL-TTSLarge Language Model로 embed 된 prompt와 diffusion-based Text-to-Speech model을 결합추가적으로 합성 품질과 style controllability를 향상하기 위해 Large Language Model과 diffusion framework를 fine-tuning논문 (INTERSPEECH 2024) : Paper Link1. IntroductionControllable ex..
 [Paper 리뷰] ClariTTS: Feature-ratio Normalization and Duration Stabilization for Code-Mixed Multi-Speaker Speech Synthesis
[Paper 리뷰] ClariTTS: Feature-ratio Normalization and Duration Stabilization for Code-Mixed Multi-Speaker Speech Synthesis
ClariTTS: Feature-ratio Normalization and Duration Stabilization for Code-Mixed Multi-Speaker Speech SynthesisText-to-Speech model에서 code-mixed text는 speaker-related feature에 source language에 대한 linguistic feature가 포함될 수 있으므로 unnatural accent를 생성할 수 있음ClariTTSFlow-based text-to-speech model에 Feature-ratio Normalized Affine Coupling Layer를 적용- Speaker와 linguistic feature를 disentangle 하여 target sp..