

 [Paper 리뷰] FreGrad: Lightweight and Fast Frequency-aware Diffusion Vocoder
[Paper 리뷰] FreGrad: Lightweight and Fast Frequency-aware Diffusion Vocoder
FreGrad: Lightweight and Fast Frequency-aware Diffusion Vocoder Lightweight, fast diffusion-based vocoder를 사용하여 사실적인 audio를 합성할 필요가 있음 FreGrad 복잡한 waveform을 sub-band wavelet으로 decompose 하는 discrete wavelet transform을 적용 Frequency awareness를 높이는 frequency-aware dilated convolution을 도입 합성 품질을 향상할 수 있는 추가적인 bag of tricks를 소개 논문 (ICASSP 2024) : Paper Link 1. Introduction Neural vocoder는 mel-spectrog..
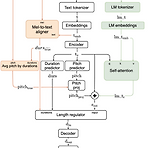 [Paper 리뷰] Mixer-TTS: Non-autoregressive, Fast and Compact Text-to-Speech Model Conditioned on Language Model Embeddings
[Paper 리뷰] Mixer-TTS: Non-autoregressive, Fast and Compact Text-to-Speech Model Conditioned on Language Model Embeddings
Mixer-TTS: Non-autoregressive, Fast and Compact Text-to-Speech Model Conditioned on Language Model Embeddings Mel-spectrogram generation에서는 non-autoregressive 모델이 유용함 Mixer-TTS MLP-Mixer architecture를 기반으로 pitch/duration predictor를 활용 Pre-trained language model의 token embedding을 추가적으로 도입하여 Mixer-TTS를 extend 논문 (ICASSP 2022) : Paper Link 1. Introduction Text-to-Speech (TTS)에서는 속도 향상을 위해서는 non-aut..
 [결산] 1994년도 앨범 결산
[결산] 1994년도 앨범 결산
선정 기준 : 작성자 마음대로 뽑습니다. 1994년도 앨범 결산 1. 개인적인 추천 앨범 Sunny Day Real Estate - : 이모(Emo)라는 장르에 대한 완벽한 요약이자 불변의 랜드마크와도 같은 앨범입니다. 칙칙하고 불안한 기타와 점점 고조되어 가는 드럼은 공격적인 코러스와의 결합을 통해 비관의 시너지를 폭발시킵니다. Sunny Day Real Estate - 'Seven' 2. 올해의 국내 싱글 유앤미블루 - '세상 저편에 선 너' : 후에 2집에도 재수록되는 유앤미블루의 대표적인 싱글입니다. 다만 곡에서 느껴지는 것처럼, 한국적 색채보다는 영미권 록의 향기가 짙은 탓에 1994년 당시의 국내 록씬에서는 아이러니하게도 외면받은 곡이기도 합니다. 유앤미블루 - '세상 저편에 선 너' 3. 올..
 [결산] 1993년도 앨범 결산
[결산] 1993년도 앨범 결산
선정 기준 : 작성자 마음대로 뽑습니다. 1993년도 앨범 결산 1. 개인적인 추천 앨범 Afghan Whigs - : 그런지가 맹위를 떨치던 당시 미국 얼터너티브 씬에서 Afghan Whigs는 그런지에 소울을 결합하며 가장 추악하고 노골적인 컨셉 앨범을 만들어냈습니다. 분노, 마약, 욕망 등으로 가득 찬 가사는 날카로운 보컬, 감정적인 기타와 결합되며 비신사적인 구렁텅이 속으로 리스너를 끌어내립니다. Afghan Whigs - 'Debonair' 2. 올해의 국내 싱글 부활 - '사랑할수록' : 절절한 김재기의 보컬과 그 색을 극대화하는 김태원의 작곡 능력이 최적으로 어우러진 곡입니다. 안타깝게도 보컬 김재기의 요절로 인해 '사랑할수록'은 정식 녹음되지 못한채 앨범에 실렸지만, 그 데모 버전만으로도 ..
 [Paper 리뷰] MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
[Paper 리뷰] MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis
MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis Generative Adversarial Network (GAN)를 사용하여 안정적이고 고품질의 waveform을 합성할 수 있음 MelGAN Mel-spectrogram inversion을 위해 GAN에 대한 architecture 수정과 간단한 training technique을 도입 더 적은 parameter 수와 빠른 추론 속도를 가지는 non-autoregressive 하고 fully convolutional 한 neural vocoder Conditional sequence 합성을 위한 general purpose discriminator 설계로 확장 가능 논문..
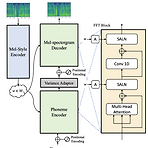 [Paper 리뷰] Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation
[Paper 리뷰] Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation
Meta-StyleSpeech: Multi-Speaker Adaptive Text-to-Speech Generation Text-to-Speech 모델은 주어진 speaker에서 나온 few audio sample 만을 사용하여 고품질 음성을 합성할 수 있어야 함 StyleSpeech 고품질 합성이 가능하고 새로운 speaker에 대해 효과적으로 adaptaion 하는 TTS 모델 Reference에서 추출된 style에 따라 text input의 gain과 bias를 align 하는 Style-Adaptive Layer Normalization을 도입 Meta-StyleSpeech 새로운 speaker에 대한 StyleSpeech의 adaptation을 향상하기 위해 style prototype으로 학..