

 [Paper 리뷰] TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
[Paper 리뷰] TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control
TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style ControlSinging style의 multifaceted nature로 인해 singing voice synthesis는 modeling, transfer, control 측면에서 한계가 있음- 특히 unseen singer에 대한 stylistic nuance가 포함된 singing voice를 합성하기 어려움TCSingerClustering style encoder를 통해 style information을 compact latent space로 condeseStyle and Duration Language Model을 통해 style infor..
 [결산] 2024년도 앨범 결산
[결산] 2024년도 앨범 결산
선정 기준 : 작성자 마음대로 뽑습니다.2024년도 앨범 결산1. 개인적인 추천 앨범MoritaSaki in the Pool - : 올해 일본 슈게이즈 씬이 다소 부진했던 가운데, MoritaSaki in the Pool만이 유일하게 교토의 저력을 보여줬습니다. 소음으로 가득 채워진 회색빛 공간 속에서 유리에 비쳐 산란하는 듯한 기타는 장르의 본질적 아름다움을 다시 돌아보게 만듭니다. MoritaSaki in the Pool - 'Mirror's Edge' 2. 올해의 국내 싱글이희상 - '항해': EVER 삼부작의 마지막은 어쩌면 당연하게도 영원, 로 향합니다. 그중에서도 타이틀 '항해'는 다소 뻔한 음악적 레퍼런스에도 불구하고, 트릴로지를 관통한 서사의 완성이라는 점에서 특별한 감정의 파도를 전달합니..
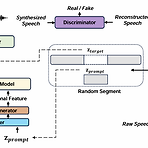 [Paper 리뷰] FlashSpeech: Efficient Zero-Shot Speech Synthesis
[Paper 리뷰] FlashSpeech: Efficient Zero-Shot Speech Synthesis
FlashSpeech: Efficient Zero-Shot Speech Synthesis최근의 large-scale zero-shot speech synthesis는 language model과 diffusion을 기반으로 구축되므로 computationally intensive 하고 generation process가 느림FlashSpeechLatent consistency model을 기반으로 adversarial consistency training을 도입Prosody generator module을 통해 prosody diversity를 향상논문 (MM 2024) : Paper Link1. IntroductionText-to-Speech (TTS)에서 zero-shot synthesis는 addi..
 [Paper 리뷰] PitchFlow: Adding Pitch Control to a Flow-Matching based TTS Model
[Paper 리뷰] PitchFlow: Adding Pitch Control to a Flow-Matching based TTS Model
PitchFlow: Adding Pitch Control to a Flow-Matching based TTS ModelFlow-matching Text-to-Speech model은 stability와 control 측면에서 한계가 있음PitchFlowSpeaker scoring과 pitch guidance를 도입하여 생성된 speech의 timbre와 pitch contour를 controlPrior에 대한 optimal choice를 통해 similarity를 개선하고 classifier guidance를 통해 fine-grained pitch contorl을 지원논문 (INTERSPEECH 2024) : Paper Link1. Introduction최근의 Text-to-Speech (TTS) mod..
 [Paper 리뷰] NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-Robust Expressive TTS
[Paper 리뷰] NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-Robust Expressive TTS
NoreSpeech: Knowledge Distillation based Conditional Diffusion Model for Noise-Robust Expressive TTSExpressive text-to-speech는 다음의 어려움이 존재함- Reference audio에 background noise가 포함된 경우 highly dynamic prosody information을 추출하기 어려움- Unseen speaking style에 대한 generalization이 가능해야 함NoreSpeechKnowledge distillation을 통해 teacher model에서 noise-agnostic speaking style을 학습하는 diffusion model에 기반한 DiffStyle m..
 [Paper 리뷰] GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech
[Paper 리뷰] GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-Speech
GenerTTS: Pronunciation Disentanglement for Timbre and Style Generalization in Cross-Lingual Text-to-SpeechCross-lingual text-to-speech는 다음의 어려움이 있음- Timbre, pronunciation은 서로 correlate 되어 있음- Speech style에는 language-agnostic, language-specific part가 포함되어 있음GenerTTSPronunciation/style과 timbre를 disentangle 하기 위해 HuBERT-based information bottleneck을 도입Language-specific information을 제거하기 위해 style, ..