

 [Algorithm] 스택
[Algorithm] 스택
* Python을 기준으로 합니다 스택 (Stack) - 개념 스택 : LIFO (Last In First Out) 형태의 자료구조 처음 실행했던 위치로 돌아가기 위해 이전 실행들을 쌓아서 관리하는 용도 삽입과 삭제를 핵심 연산으로 가짐 스택의 주요 연산 `push()` : 새로운 데이터를 스택의 맨 위에 추가 `pop()` : 스택의 맨 위에 위치한 데이터를 꺼내서 반환 `isEmpty()` : 스택이 비어있으면 `True`, 아니면 `False` `peek()` : 스택 맨 위에 위치한 데이터를 확인 Python에서의 스택 활용 일반적으로 리스트를 스택처럼 활용함 Python 리스트의 `append(), pop()`은 각각 `push(), pop()`에 대응 `isEmpty()`의 경우 리스트의 le..
 [Paper 리뷰] FastFit: Towards Real-Time Iterative Neural Vocoder by Replacing U-Net Encoder with Multiple STFTs
[Paper 리뷰] FastFit: Towards Real-Time Iterative Neural Vocoder by Replacing U-Net Encoder with Multiple STFTs
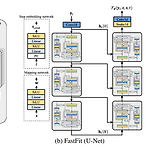
FastFit: Towards Real-Time Iterative Neural Vocoder by Replacing U-Net Encoder with Multiple STFTsU-Net encoder를 multiple Short-Time Fourier Transform (STFT)로 대체하여 sample 품질을 유지하면서 더 빠른 합성 속도를 얻을 수 있음FastFit각 encoder block을 STFT로 대체하고 decoder block의 temporal resolution과 동일한 parameter를 사용해 skip connection으로 연결이를 통해 high-fidelity의 sample을 유지하면서 parameter 수와 생성 속도를 절반으로 줄임논문 (INTERSP..
 [Algorithm] 연결 리스트
[Algorithm] 연결 리스트
* Python을 기준으로 합니다 연결 리스트 (Linked List) - 개념 연결 리스트 : 각 데이터들이 순서대로 링크를 통해 연결된 구조 연결 리스트에서 하나의 노드(Node)는 데이터와 링크(Link)를 가짐 링크는 다른 노드의 주소를 가리키는 역할 연결 리스트의 주요 연산 `insert()` : 특정 위치에 새로운 데이터를 삽입 `delete()` : 특정 위치의 데이터를 삭제 `isEmpty()` : 리스트가 비어있으면 `True` 아니면 `False` `size()` : 리스트의 크기 (들어있는 데이터 수) 반환 배열과 연결 리스트의 비교 리스트 요소 접근 배열은 모든 데이터가 크기가 같고 연속적인 메모리 공간에 위치함 - $k$번째 데이터의 위치는 데이터 크기와 $k$를 곱한 다음, 시작..
 [Algorithm] 배열
[Algorithm] 배열
* Python을 기준으로 합니다 배열 (Array) - 개념 배열 : 값 또는 변수들의 집합으로 구성된 구조, index와 값을 일대일 대응해 관리 `list()`, `[ ]`로 선언되고, 크기 지정 없이 자동으로 resizing 되는 동적 구조 배열 내의 값을 자주 조회하는 경우 효율적이지만, 메모리 크기가 제한되거나 삽입이 많은 경우 비효율적 - 일반적으로 배열의 값 조회와 `append()`를 통한 배열 끝 삽입은 $O(1)$을 소모함 - 배열의 첫 번째나 중간 위치 삽입은, 해당 위치로부터 모든 기존 값들을 뒤로 shift 하므로 $O(n)$이 소모됨 배열의 차원 - 1차원 배열 : 기본적인 배열 형태 - 2차원 배열 : 1차원 배열의 확장, `arr = [[1,2],[3,4]]`와 같이 선언 ..
 [Algorithm] 문자열
[Algorithm] 문자열
* Python을 기준으로 합니다 문자열 (String) - 개념 문자열 : 문자들의 집합으로, emutable 객체 배열처럼 사용할 수 있지만, 한번 선언된 문자열은 상수 취급을 하기 때문에 값을 임의로 변경할 수 없음 대표적으로 `+` 연산은 문자열을 결합하는데, 이는 내부적으로 상수끼리의 합으로 취급됨 - 결과적으로 새로운 상수를 생성하여 할당하는 방식으로 수행되므로 비효율적임 주요 유형 : Palindrome/Anagram, 진법 변환, 문자열 조작(변환, 탐색, 정렬), 정규표현식 - 구현 1. 문자열 초기화 `' '`나 `" "` 사용 hello1 = 'Hello World!' hello2 = "Hello World!" 2. 문자열 결합 `+` 나 `''.join()` 사용 여기서 `+`는 각..
 [Paper 리뷰] StyleTTS2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
[Paper 리뷰] StyleTTS2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
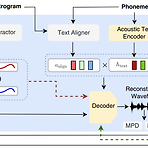
StyleTTS2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language ModelsHuman-level text-to-speech를 위해 large speech language model (SLM)을 활용할 수 있음StyleTTS2Diffusion model을 통해 style을 latent random variable로 모델링하여 reference speech 없이 text에 적합한 style을 생성End-to-End training을 위해 differentiable duration modeling이 가능한 discriminator를 도입하고 large pre..