

 [Paper 리뷰] P-Flow: A Fast and Data-Efficient Zero-Shot TTS through Speech Prompting
[Paper 리뷰] P-Flow: A Fast and Data-Efficient Zero-Shot TTS through Speech Prompting
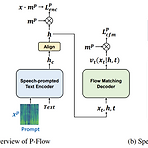
P-Flow: A Fast and Data-Efficient Zero-Shot TTS through Speech PromptingNeural codec language model은 대규모의 data를 학습하여 zero-shot text-to-speech 성능을 크게 향상함- BUT, robustness가 부족하고, sampling 속도가 매우 느리고, pre-trained neural codec representation에 의존적임P-FlowSpeaker adaptation을 위해 speech prompt를 사용하는 빠르고 data-efficient 한 zero-shot text-to-speech 모델Speech-prompted text encoder와 flow matching generative dec..
 [Paper 리뷰] SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis
[Paper 리뷰] SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis
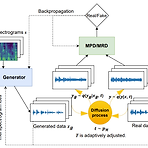
SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis Generative Adversarial Network는 빠른 합성을 보장하면서 고품질의 음성을 생성할 수 있음 SpecDiff-GAN Discriminator 이전에 Gaussian noise를 real/fake sample 모두에 inject 하는 forward diffusion process를 통해 training stability를 향상 Discriminator task를 더 어렵게 만드는 spectrally-shaped noise 분포를 도입 논문 (ICASSP 2024) : Paper Link 1. Introduction Audio 합성은 주어..
 [결산] 1999년도 앨범 결산
[결산] 1999년도 앨범 결산
선정 기준 : 작성자 마음대로 뽑습니다. 1999년도 앨범 결산 1. 개인적인 추천 앨범 Jimmy Eat World - : Jimmy Eat World의 세번째 앨범, 는 청소년기의 유약한 감성을 그대로 담은 세기말의 이모(Emo) 걸작 중 하나입니다. 특히 앨범에 담겨진 미드웨스트 이모 (Midwest Emo)의 인디적 예술성과 팝적 대중성 간의 결합은, 장르의 궤도를 새로운 차원으로 끌어올렸습니다. Jimmy Eat World - 'Lucky Denver Mint' 2. 올해의 국내 싱글 롤러코스터 - '습관' : 롤러코스터의 대표곡이자 특유의 재즈에 기반한 팝적 감수성이 잘 드러나는 싱글입니다. 깔끔한 홈레코딩과 조원선의 보컬 덕분에 곡은 대중적으로 크게 각인될 수 있었지만, 재밌는 사실은 1집의..
 [Paper 리뷰] TriniTTS: Pitch-Controllable End-to-End TTS without External Aligner
[Paper 리뷰] TriniTTS: Pitch-Controllable End-to-End TTS without External Aligner
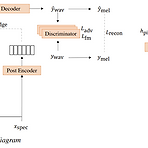
TriniTTS: Pitch-Controllable End-to-End TTS without External Aligner End-to-End architecture, prosody control, on-the-fly duration alignment를 모두 만족하는 text-to-speech 모델이 필요함 - 대부분 two-stage pipeline에 의존적이고 controllability가 부족하기 때문 TriniTTS External aligner 없이 pitch control이 가능한 end-to-end text-to-speech 모델 Alignment search, pitch estimation, waveform generation을 동시에 수행하여 음성의 data 분포를 나타내는 latent ..
 [Paper 리뷰] LightVoc: An Upsampling-Free GAN Vocoder based on Conformer and Inverse Short-Time Fourier Transform
[Paper 리뷰] LightVoc: An Upsampling-Free GAN Vocoder based on Conformer and Inverse Short-Time Fourier Transform
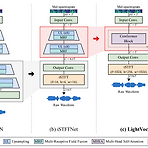
LightVoc: An Upsampling-Free GAN Vocoder based on Conformer and Inverse Short-Time Fourier Transform Generative Adversarial Network (GAN) 기반의 기존 vocoder는 mel-spectrogram으로부터 audio를 생성하기 위해 iterative upsampling을 필요로 함 - Iterative upsampling은 network 복잡도를 증가시키므로 vocoder의 추론 속도를 저하시키는 주요 원인 LightVoc Upsampling block을 Conformer block으로 대체하는 GAN-based vocoder 새로운 discriminator 조합을 도입하여 full-band에 걸쳐 ..
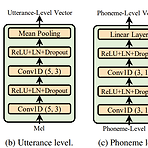 [Paper 리뷰] AdaSpeech: Adaptive Text to Speech for Custom Voice
[Paper 리뷰] AdaSpeech: Adaptive Text to Speech for Custom Voice
AdaSpeech: Adaptive Text to Speech for Custom Voice TTS adaptation에서 custom voice를 활용하기 위해서는 2가지 과제가 있음 - Adaptation 모델은 source speech data와 상당히 다른 다양한 acoustic condition을 처리할 수 있어야 함 - 음성 품질을 유지하면서 적은 memory 사용량을 가지도록 각 target speaker에 대한 adaptation parameter가 작아야 함 AdaSpeech 고품질 합성과 효율적인 voice customization을 지원하는 adaptive TTS 모델 다양한 acoustic condition을 처리하기 위해 utterance, phoneme level 모두에서 aco..