

티스토리 뷰
Paper/TTS
[Paper 리뷰] DMOSpeech2: Reinforcement Learning for Duration Prediction in Metric-Optimized Speech Synthesis
feVeRin 2026. 4. 3. 13:27반응형
DMOSpeech2: Reinforcement Learning for Duration Prediction in Metric-Optimized Speech Synthesis
- Diffusion-based Text-to-Speech의 component를 perceptual metric에 optimize 하는 것은 어려움
- DMOSpeech2
- Speaker similarity와 Word Error Rate를 reward로 사용하는 Group Relative Preference Optimization을 적용
- 추가적으로 teacher-guided sampling을 통해 output diversity를 향상
- 논문 (AAAI 2026) : Paper Link
1. Introduction
- NaturalSpeech, StyleTTS2와 같은 zero-shot Text-to-Speech (TTS) model은 speaker-specific training 없이 short audio sample 만으로 unseen speaker의 speech를 생성함
- BUT, zero-shot TTS는 여전히 perceptual quality metric에 대한 end-to-end optimization이 어려움
- 이를 해결하기 위해 Koel-TTS와 같은 Reinforcement Learning (RL)을 고려할 수 있음
-> 그래서 diffusion TTS에 대한 end-to-end perceptual metric optimization을 지원하는 DMOSpeech2를 제안
- DMOSpeech2
- Duration predictor를 Group Relative Policy Optimization (GRPO)를 통해 probabilistic policy로 modeling 하고 speaker similarity와 Word Error Rate의 reward signal을 반영
- 추가적으로 기존 DMOSpeech의 distribution matching distillation으로 인한 output diversity 문제를 해결하기 위해 teacher-guided sampling을 도입
< Overall of DMOSpeech2 >
- GRPO와 teacher-guided sampling을 활용한 perceptually optimized zero-shot TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- DMOSpeech with Flow Matching
- DMOSpeech는 distribution matching distillation과 direct metric optimization을 combine 하여 구성됨
- DMOSpeech2는 해당 DMOSpeech framework를 기반으로 F5-TTS를 teacher model로 사용함
- 특히 audio AutoEncoder의 latent representation을 활용하는 DMOSpeech와 달리 DMOSpeech2는 mel-spectrogram을 directly generate 하고 pre-trained Vocos를 통해 waveform을 생성함 - 구조적으로는 3-training component로 구성됨:
- Student generator $G_{\theta}$는 pre-trained teacher model에 대해 distribution을 match 하기 위해 distribution matching distillation (DMD2)를 통해 training 됨
- 이를 통해 student model은 few sampling step 만으로도 high-quality synthesis가 가능함 - Discriminator를 활용한 multi-modal adversarial training을 통해 perceptual quality를 향상함
- Direct metric optimization은 pre-trained Automatic Speech Recognition (ASR), Speaker Verification (SV) model을 활용하여 Word Error Rate와 speaker similarity metric에 대한 optimization을 지원함
- Student generator $G_{\theta}$는 pre-trained teacher model에 대해 distribution을 match 하기 위해 distribution matching distillation (DMD2)를 통해 training 됨
- 추론 시에는 input text, speaker prompt, target speech duration을 condition으로 하여 denoising step을 통해 speech를 directly generate 함
- 먼저 separate duration predictor의 pre-defined duration $L$에서 Gaussian noise $\mathbf{z}\sim\mathcal{N}(0,I)$를 sampling 함
- 이후 student generator $G_{\theta}$는 sway sampling schedule을 따라 해당 noise를 여러 step에 걸쳐 mel-spectrogram으로 transform 함
- 이때 noise level $t\in\{0.0000, 0.0761, 0.2929, 0.6173\}$에서 coefficient $u=-1$을 가짐 - Final spectrogram은 vocoder를 통해 waveform으로 convert 됨
- DMOSpeech2는 해당 DMOSpeech framework를 기반으로 F5-TTS를 teacher model로 사용함

- Speech Length Predictor with RL
- 기존 DMOSpeech는 duration predictor가 optimization loop 바깥에 위치하므로 end-to-end optimization을 방해하므로 DMOSpeech2에서는 speech length predictor에 대한 reinforcement learning approach를 도입함
- Duration Predictor Architecture
- 논문은 speech length predictor를 위해 DiTTo-TTS와 encoder-decoder Transformer architecture를 채택함
- 이때 기존과 달리 phoneme-level duration을 predict 하지 않고 total remaining legnth를 predict 함 - Input text sequence $\mathbf{x}$, $t$ frame까지의 speech prompt $\mathbf{p}_{t}$에 대해
- Parameter $\phi$를 가지는 length predictor $\mathcal{P}_{\phi}$는 utterance complete에 필요한 remaining frame 수 $L_{t}$의 probability distribution을 modeling 함:
(Eq. 1) $ P(L_{t}=l|\mathbf{x},\mathbf{p}_{t})=\left[\mathcal{P}_{\phi}(\mathbf{x},\mathbf{p}_{t})\right]_{l}$
- $[\cdot]_{l}$ : 남은 $l$ frame에 대한 model prediction - (Eq. 1)은 speech prompt가 extend 됨에 따라 decrease 하는 predicted remaining length에 대한 autoregressive structure를 구성함
- Parameter $\phi$를 가지는 length predictor $\mathcal{P}_{\phi}$는 utterance complete에 필요한 remaining frame 수 $L_{t}$의 probability distribution을 modeling 함:
- 구조적으로는 input text에 대한 comprehensive contextual information을 capture 하는 bidirectional text encoder를 활용함
- Decoder는 future lookahead를 방지하기 위해 causal masking을 사용하고 speech prompt의 mel-spectrogram을 input으로 사용함
- Cross-attention mechanism은 encoder의 text feature를 integrate 하고 final layer는 Softmax activation을 통해 pre-defined maximum length 내에서 possible remaining length의 distribution을 predict 함
- Decoder는 future lookahead를 방지하기 위해 causal masking을 사용하고 speech prompt의 mel-spectrogram을 input으로 사용함
- Training 시에는 remaining audio length에 대한 ground-truth label이 각 time step마다 하나씩 decrease 함
- Batch size $B$의 mel-spectrogram length에 대한 batch sequence $\{L_{1},L_{2},...,L_{B}\}$에서, 각 training example $L_{i}$에 대한 target remaining length는 decreasing sequence $(L_{i}-1,L_{i}-2,...,1,0)$과 같음 - 결과적으로 predictor는 predicted distribution과 ground-truth remaining length 간의 Cross-Entropy loss로 initially training 됨
- 논문은 speech length predictor를 위해 DiTTo-TTS와 encoder-decoder Transformer architecture를 채택함
- GRPO-based Duration Optimization
- Perceptual metric에 대한 direct optimization을 위해 speech length predictor를 reinforcement learning framework에서 stochastic policy로 formulate 하고 Group-Relative Policy Optimization (GRPO)를 적용함
- 각 input text $\mathbf{x}$, prompt $\mathbf{p}$에 대해 total speech length $L$을 choice 하는 policy를 probabilistic duration predictor $\pi_{\phi}(L|\mathbf{x},\mathbf{p}):=\mathcal{P}_{\phi}(\mathbf{x},\mathbf{p})$로 modeling 함
- Training 시에는 각 input에 대해 $K$개의 서로 다른 duration을 sampling 함:
(Eq. 2) $ L_{k}\sim\pi_{\phi}(L|\mathbf{x},\mathbf{p}),\,\,\,k=1,2,...,K$
- $K$ : group size - 각 sampled duration에 대해 4-step student model을 사용하여 speech를 생성함:
(Eq. 3) $\mathbf{y}_{k}=G_{\theta}(\mathbf{z},\mathbf{x},\mathbf{p},L_{k}),\,\,\,\mathbf{z}\sim\mathcal{N}(0,I)$
- $G_{\theta}$ : student generator, $\mathbf{z}$ : noise - 이후 speaker similarity, speech recognition metric을 사용하여 각 sample에 대한 reward를 얻음:
(Eq. 4) $r_{k}=\log P_{CTC}\left(\mathbf{x}|C(\mathbf{y}_{k})\right)+\lambda_{SIM}\cdot \frac{\mathbf{e}_{p}\cdot\mathbf{e}_{y_{k}}}{||\mathbf{e}_{p} ||\,|| \mathbf{e}_{y_{k}}||}$
- $C(\cdot)$ : pre-trained CTC-based ASR model, $\mathbf{e}_{p}=S(\mathbf{p}), \mathbf{e}_{y_{k}}=S(\mathbf{y}_{k})$ : prompt/student-generated speech, $\lambda_{SIM}=3$ : weighting factor - 다음으로 advantage를 compute 하기 위해 reward를 normalize 함:
(Eq. 5) $A_{k}=\frac{r_{k}-\mu_{r}}{\sigma_{r}}$
- $\mu_{r}, \sigma_{r}$ : group 내 reward에 대한 mean/standard deviation
- Training 시에는 각 input에 대해 $K$개의 서로 다른 duration을 sampling 함:
- GRPO에서는 3가지의 distinct policy를 maintain 함
- Current policy $\pi_{\phi}$는 actively trained speech length predictor에 해당함
- Old policy $\pi_{old}$는 current sample batch를 생성하는 previous step의 policy
- Reference policy $\pi_{ref}$는 training beginning에서 생성된 initially supervised model의 frozen copy
- 이를 기반으로 논문은 ratio $R_{k}$를 다음과 같이 정의함:
(Eq. 6) $R_{k}=\frac{\pi_{\phi}(L_{k}|\mathbf{x},\mathbf{p})}{\pi_{old}(L_{k}|\mathbf{x},\mathbf{p})}$ - 그러면 single sample에 대한 GRPO loss는:
(Eq. 7) $\mathcal{L}_{k}=\min\left(A_{k}\cdot R_{k},A_{k}\cdot \text{clip}(R_{k},1\pm \epsilon)\right)-\beta\cdot \text{KL}$
- $\epsilon=0.2$ : policy update magnitude에 대한 clipping parameter, $\beta=0.04$ : KL regularization strength, $\text{KL}=\mathbb{D}_{KL}[\pi_{\phi}||\pi_{ref}]$ : current/reference policy 간의 KL divergence - 결과적으로 full GRPO loss는:
(Eq. 8) $\mathcal{L}_{GRPO}=-\mathbb{E}_{\mathbf{x},\mathbf{p}}\left[\frac{1}{K}\sum_{k=1}^{K} \mathcal{L}_{k}\right]$
- 이때 다양한 length prediction을 위해 temperature-based sampling을 수행하고, reward diversity가 insufficient 한 batch ($\max(r)-\min(r)<0.01$)를 skip 하는 quality control을 적용함
- Teacher-Guided Sampling
- Mode Shrinkage in Distribution Matching Distillation
- DMOSpeech의 distribution matching distillation은 mode shrinkage로 인한 sample diversity의 한계가 존재함
- Student가 teacher 보다 더 적은 step에서 speech를 생성하도록 training 되는 경우, student는 data distribution의 high-probability region에 focus 하기 때문
- 특히 student model은 sound quality에서는 teacher와 유사한 mode coverage를 보이지만 intonation pattern, rhythm variation, speech cadence와 같은 prosodic feature에서는 diversity가 저하됨
- 즉, diversity reduction은 spectral characteristic 보다 temporal/structural dimension에서 주로 나타남
- Diffusion process 측면에서 high noise level의 model은 prosodic element, phoneme duration, pause, pitch contour, text-speech alignment와 같은 utterance의 semantic, structural framework를 구성함
- 반대로 low noise level에서는 voice quality, speaker identity와 같은 acoustic detail을 refine 함 - 이때 student가 few step으로 constrain 되는 경우, 해당 hierarchical generation process를 compress 하게 됨
- 따라서 early denoising step의 prosodic, structural element에 영향을 줌
- DMOSpeech의 distribution matching distillation은 mode shrinkage로 인한 sample diversity의 한계가 존재함
- Hybrid Sampling Strategy
- 논문은 mode shrinkage를 해결하기 위해 Teacher-Guided Sampling을 도입함
- 이를 위해 diffusion process의 natural division을 기반으로, early denoising step에서는 prosodic structure를 위한 teacher model을 사용하고 later step에서는 acoustic refinement를 위한 student model을 사용함
- 먼저 teacher model을 사용하여 pre-defined noise level $t_{switch}$까지 initial denoising step을 수행해 diverse prosodic pattern과 text-speech duration alignment를 구성함
- 다음으로 student model로 remaining denoising process를 $t_{switch}$에서 $1$까지 수행함
- 구체적으로 teacher-guided sampling procedure는 random Gaussian noise $\mathbf{z}$에서 여러 step sequence에 걸쳐 progressive denoising을 수행함
- First $K$ step에서 teacher는 sway sampling schedule을 따라 flow matching을 수행함
- 여기서 sway schedule은 semantic structure를 형성하는 early step에 더 많은 sample을 allocate 함 - Noise level이 $t_{switch}$가 되면 student로 transition 되어 remaining denoising을 $M$ step 동안 수행함
- 결과적으로 teacher-guided sampling은 teacher에 prosodic structure를 구성하는 labor-intensive task를, student에 acoustic detail refinement를 delegating 하여 efficiency-diversity trade-off를 달성함
- First $K$ step에서 teacher는 sway sampling schedule을 따라 flow matching을 수행함

3. Experiments
- Settings
- Results
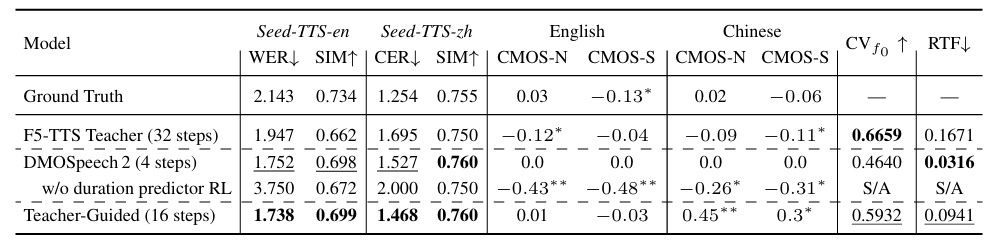
- 전체적으로 DMOSpeech2의 성능이 가장 우수함

- Ablation Study
- 각 component 모두 성능 향상에 유효함
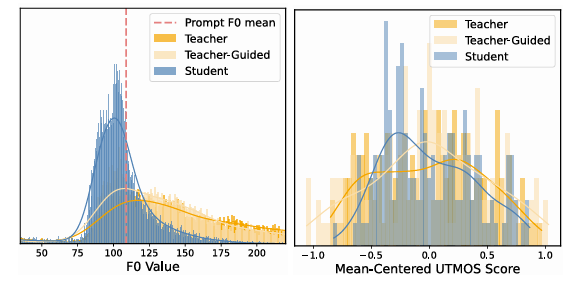
- Teacher-guided sampling을 활용하면 mode shrinkage를 방지하고 output diversity를 확보할 수 있음
반응형
'Paper > TTS' 카테고리의 다른 글
댓글