

티스토리 뷰
Paper/TTS
[Paper 리뷰] MambaVoiceCloning: Efficient and Expressive Text-to-Speech via State-Space Modeling and Diffusion Control
feVeRin 2026. 4. 16. 13:07반응형
MambaVoiceCloning: Efficient and Expressive Text-to-Speech via State-Space Modeling and Diffusion Control
- Diffusion-based Text-to-Speech에 State-Space Model을 도입할 수 있음
- MamabaVoiceCloning
- Gated bidirectional Mamba text encoder, temporal Bi-Mamba, expressive Mamba를 combine 하여 linear-time $\mathcal{O}(T)$ conditioning을 제공
- 추론 시에는 fixed mel-diffusion-vocoder backbone하에서 attention-based duration, style module을 제거
- 논문 (ICLR 2026) : Paper Link
1. Introduction
- Text-to-Speech (TTS) system에서 conditioning stack은 Transformer attention이나 recurrent module에 의존함
- BUT, attention은 quadratic complexity, recurrent module은 long-range drift의 문제가 있음
- 이때 Grad-TTS, ProDiff의 diffusion decoder를 사용하면 encoder efficiency를 향상할 수 있음 - 추가적으로 Mamba와 같은 State-Space Model (SSM)은 bounded activation, linear-time sequence scan, state-persistent streaming을 지원하므로 memory pressure, long-range drift 문제를 reduce 할 수 있음
- BUT, attention은 quadratic complexity, recurrent module은 long-range drift의 문제가 있음
-> 그래서 diffusion-based TTS에 Mamba를 접목한 MambaVoiceCloning (MVC)을 제안
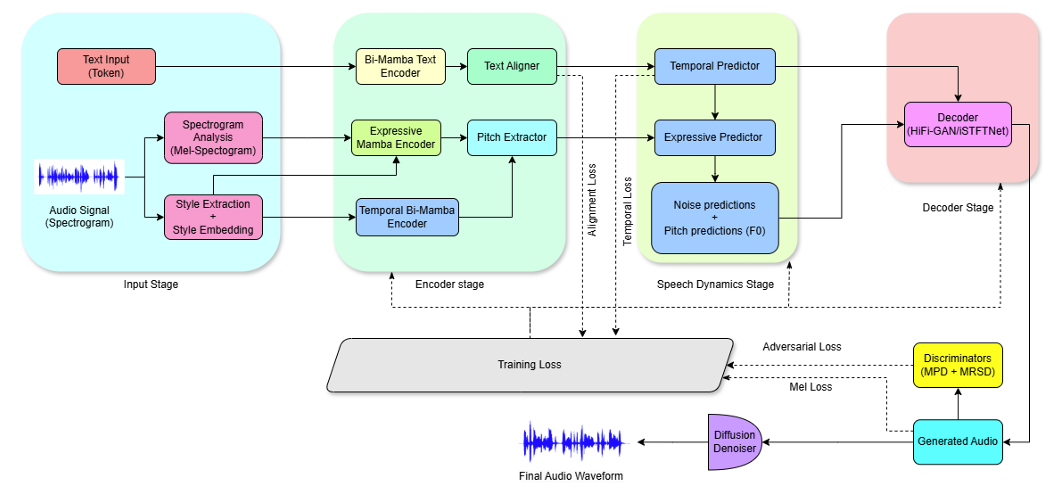
- MambaVoiceCloning (MVC)
- Diffusion-based TTS의 mel-diffusion-vocoder pipeline과 match되는 Mamba 기반의 fully SSM-only conditioning stack을 구성
- 특히 gated bidirectional Mamba text encoder, temporal Bi-Mamba encoder, expressive Mamba encoder의 3가지 conditioning stream을 활용
< Overall of MambaVoiceCloning >
- Diffusion-based TTS를 기반으로 fully SSM-only conditioning path를 구축한 efficient, expressive TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- MVC는 text, rhythm/duration, prosody에 대해 selective State-Space Model (SSM)을 활용하여 inference-time attention과 recurrence를 replace 함
- Lightweight attention-based aligner는 training 시 phoneme-frame supervision을 제공하고 추론 시에는 discard 되어 linear-time scan과 bounded activation을 가지는 SSM-only conditioning stack을 생성함
- 구조적으로 MVC는 gated bidirectional Mamba text encoder, temporal Bi-Mamba, AdaLN conditioning을 포함한 expressive Mamba로 구성됨
- 각 Mamba는 96 state dimension, kernel size 5의 depthwise convolution, gating temperature $\tau=1.0$을 사용함 - 이를 기반으로 MVC는 text, reference audio로부터 3개의 conditioning stream을 구성함:
- 이때 gated Bi-Mamba text encoder는 text, temporal Bi-Mamba는 rhythm/duration, expressive Mamba는 mel-spectrogram에서 동작함
- 이후 stream은 speech-dynamics stage에서 fuse 되어 fixed StyleTTS2 decoder-vocoder로 전달됨 - Training 시에는 aligner가 soft phoneme-frame weight를 제공하고, 추론 시에는 discard 되어 모든 encoder module은 attention map 없이 $\mathcal{O}(T)$로 실행됨
- Streaming 시에는 bidirectional text encoder를 look-ahead $L$을 가지는 causal Uni-Mamba로 replace 하여 explicit latency-context trade-off를 제공함
- 이때 gated Bi-Mamba text encoder는 text, temporal Bi-Mamba는 rhythm/duration, expressive Mamba는 mel-spectrogram에서 동작함
- Notation
- $T_{x},T_{m}$을 각각 text token 수, mel-frame 수, $d$를 text embedding dimension, $d_{h}$를 SSM hidden dimension, $d_{s}$를 style-embedding dimension이라 하자
- 그러면 token embedding을 $\mathbf{x}\in\mathbb{R}^{T_{x}\times d}$, log mel-spectrogram을 $\mathbf{M}\in\mathbb{R}^{F\times T_{m}}$, global style vector를 $\mathbf{e}\in\mathbb{R}^{d_{s}}$와 같이 나타낼 수 있음
- Input Processing
- 24kHz waveform $\mathbf{s}_{wav}\in\mathbb{R}^{T}$에 대해 Hann-window STFT, mel-filterbank projection, $\epsilon=10^{-5}$의 log compression을 사용하여 80-bin log mel-spectrogram $\mathbf{M}\in\mathbb{R}^{F\times T_{m}}$을 얻음
- Text는 $\texttt{Phonemizer}$를 통해 normalize, phonemize 되어 token $[w_{1},...,w_{T_{x}}]$를 생성함
- 그러면 token embedding과 global stlye embedding은:
(Eq. 1) $ \mathbf{x}=\text{Embed}\left(\left[w_{1},...,w_{T_{x}}\right]\right)\in \mathbb{R}^{T_{x}\times d}, \,\,\, \mathbf{e}=\frac{1}{T_{m}}\sum_{t=1}^{T_{m}}f_{\theta}(\mathbf{M}_{:,t})\in\mathbb{R}^{d_{s}}$
- $f_{\theta}$ : shallow conv/GRU module - 해당 embedding은 coarse timbre, expressiveness를 capture 하여 long-form stability, zero-shot, cross-lingual TTS를 위한 shared conditioning signal를 제공함
- Bi-Mamba Text Encoder
- 논문은 self-attention을 bidirectional Mamba block으로 replace 하여 bounded activation을 가지는 linear-time text encoder를 구성함
- 먼저 $\mathbf{x}\in\mathbb{R}^{T_{x}\times d}$가 주어지면, 이를 $d_{h}$로 project 한 다음, forward/backward Uni-Mamba scan을 적용함:
(Eq. 2) $\mathbf{h}_{f}=\text{Mamba}_{f}(\mathbf{x}),\,\,\,\mathbf{h}_{b}=\text{Mamba}_{b}(\mathbf{x})$ - 이때 각 block은 selctive state-space update를 따르고, $\mathcal{O}(T_{x})$ complexity를 가짐
- 해당 linear-time scan과 bounded activation update를 통해 attention-based duration/prosody predictor의 attention-fragmentation과 activation drift를 방지함
- 결과적으로 MVC는 multi-sentence, multi-minute segment에서도 consistent state magnitude를 preserve 하여 time에 따른 degradation 없이 prosodic cue의 predictable accumulation을 제공할 수 있음
- 특히 simple concatenation을 사용하는 기존 Bi-Mamba encoder와 달리 MVC는 gated fusion을 활용함:
(Eq. 3) $\mathbf{h}_{T}=\left(\sigma\left(W_{g}\left[\mathbf{h}_{f}; \mathbf{h}_{b}\right]\right)\odot \left[\mathbf{h}_{f};\mathbf{h}_{b}\right]\right)W_{o}$
- $W_{g}\in\mathbb{R}^{2d_{h}\times 2d_{h}}$, $W_{o}\in\mathbb{R}^{2d_{h}\times d_{h}}$
- Gating module은 local syntatic cue를 기반으로 forward/backward context를 modulate 하여 temporal coherence를 maintain 하고 drift를 reduce 해 long-range prosody를 향상함 - 추가적으로 speaker/style information을 반영하기 위해 embedding $\mathbf{e}$에 AdaLN을 적용함:
(Eq. 4) $\mathbf{h}_{T,s}=\text{AdaLN}(\mathbf{h}_{T},\mathbf{e})$
- $\text{AdaLN}(\mathbf{z},\mathbf{e})=\gamma(\mathbf{e})\odot \text{LN}(\mathbf{z})+\beta(\mathbf{e})$
- 먼저 $\mathbf{x}\in\mathbb{R}^{T_{x}\times d}$가 주어지면, 이를 $d_{h}$로 project 한 다음, forward/backward Uni-Mamba scan을 적용함:
- Expressive Mamba Encoder
- Expressive Mamba encoder는 linear time으로 speaker-specific prosody를 acoustic representation에 inject 함
- Mel feature $\mathbf{M}$과 style embedding $\mathbf{e}$가 주어지면 Mamba block에 AdaLN conditioning을 포함한 gated transformation을 적용함:
(Eq. 5) $\mathbf{h}_{E}=\text{Mamba}(\mathbf{h}_{M,s})\in \mathbb{R}^{T_{m}\times d_{h}}$
- $\mathbf{h}_{M,s}$ : style-conditioned input - 해당 module은 attention이 없는 fully SSM-based block으로써, long input의 slow prosodic dynamic을 capture 함
- Mel feature $\mathbf{M}$과 style embedding $\mathbf{e}$가 주어지면 Mamba block에 AdaLN conditioning을 포함한 gated transformation을 적용함:
- Temporal Bi-Mamba Encoder
- Temporal Bi-Mamba encoder는 rhythmic structure와 phonem-duration alignment를 modeling 함
- Style embedding $\mathbf{e}$는 frame에 대해 broadcast 되고 shallow gated transform을 통해 modulate 되어 $\mathbf{h}_{S}\in\mathbb{R}^{T_{m}\times d_{h}}$를 생성함
- Forward/backward Mamba block과 local Conv1D는 context-dependent timing pattern을 capture 하고 output은 linearly fuse 됨:
(Eq. 6) $\mathbf{h}_{B}=[\mathbf{h}_{f};\mathbf{h}_{b}]\mathbf{W}_{f}$
- Alignment and Pitch Modeling
- Training-Time Aligner
- Training-time aligner는 4 attention head와 256 hidden dimension을 가지는 2-layer Transformer로써 monotonic alignment loss로 training 됨
- Aligner는 token embedding $\mathbf{h}_{T,s}$를 frame-level weight $\alpha\in\mathbb{R}^{T_{m}\times T_{x}}$로 mapping 함
- $\mathbf{M}, \mathbf{h}_{T,s}$에 대해, aligned encoding은 다음과 같이 compute 됨:
(Eq. 7) $\mathbf{h}_{A}=\alpha\mathbf{h}_{T,s}$ - Training 시 aligner는 token-level embedding $\mathbf{h}_{T,s}$를 frame-synchronous representation으로 mapping 하는 teacher로 사용되고, 추론 시에는 completely discard 됨
- $\mathbf{M}, \mathbf{h}_{T,s}$에 대해, aligned encoding은 다음과 같이 compute 됨:
- Pitch Modeling
- Pitch modeling 시에는 expressive, temporal encoding을 모두 사용함
- 즉, $\mathbf{h}_{E}, \mathbf{h}_{B}$를 gated block을 통해 fuse 하여 $\mathbf{h}_{P}\in\mathbb{R}^{T_{m}\times d_{h}}$를 얻고, final $F_{0}$ contour를 다음과 같이 predict 함:
(Eq. 8) $F_{0}=\mathbf{h}_{P}\mathbf{W}_{F}+b_{F}$
- Speech Dynamics and Decoder Conditioning
- Speech-dynamics stage에서는 phonetic, prosodic representation을 decoder-ready feature로 refine 함
- $\mathbf{h}_{A},\mathbf{h}_{P}$에 대해 temporal predictor가 rhythm-aware representation을 생성하고, gated block을 통해 $\mathbf{h}_{P}$와 fuse 한 다음, fundamental-frequency trajectory $\hat{F}_{0}$와 residual noise vector $\mathbf{n}$으로 project 됨
- 이후 final conditioning sequence $\mathbf{h}_{D}$는 diffusion decoder로 전달됨:
(Eq. 9) $ \mathbf{h}_{D}=\left[\hat{F}_{0};\mathbf{n}\right]\in \mathbb{R}^{T_{m}\times (1+d_{h})}$
- Decoder Stage and Losses
- Decoder는 StyleTTS2의 vocoder를 사용하고 MVC는 conditioning path만 modify 함
- $\mathbf{h}_{D}$가 주어지면 decoder는 $\hat{\mathbf{M}}=\text{DiffusionDecoder}\left(\mathbf{h}_{D};\{\alpha_{t}\}\right)$를 predict 하고 vocoder는 waveform $\hat{\mathbf{s}}=\text{Vocoder}(\hat{\mathbf{M}})$으로 convert 함
- 한편으로 MVC의 total loss는 mel loss, adversarial loss, alignment loss를 combine 하여 얻어짐:
(Eq. 10) $\mathcal{L}_{total}=\lambda_{mel}\mathcal{L}_{mel}+\lambda_{adv}\mathcal{L}_{adv}+\lambda_{align}\mathcal{L}_{align}$
- 해당 $\mathcal{L}_{total}$을 기반으로 MVC는 $(\mathbf{x},\mathbf{M},\mathbf{s}_{wav})$의 triplet으로 training 됨

3. Experiments
- Settings
- Results
- 전체적으로 MVC의 성능이 가장 뛰어남

- Objective evaluation 측면에서도 최고의 성능을 달성함

- Generalization to OOD Texts and Long-Form Inputs
- OOD text에 대해서도 우수한 generalization 성능을 보임

- Short-/Long-form generation에서도 MVC가 가장 뛰어난 성능을 보임

- Streaming with Finite Look-Ahead
- Look-ahead $L$이 짧아질수록 성능도 저하됨

- Ablation Study
- 각 component는 성능 향상에 유효함

- 6 Mamba layer를 사용했을 때 최적의 성능을 달성할 수 있음
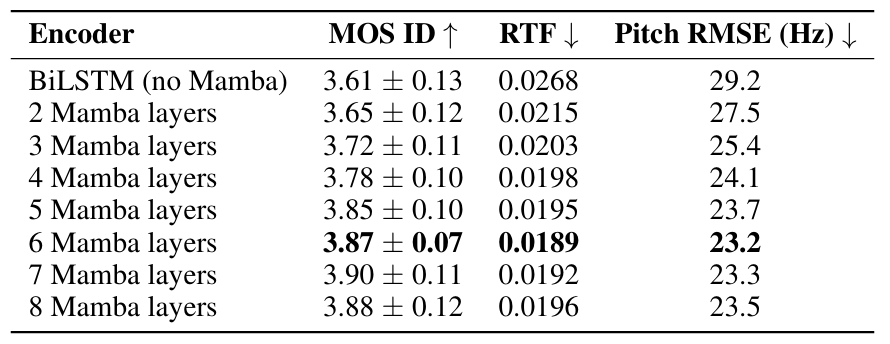
- Gated bidirectional fusion과 AdaLN을 모두 사용했을 때 최고의 성능을 달성함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글