

 [Paper 리뷰] CM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency Models
[Paper 리뷰] CM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency Models
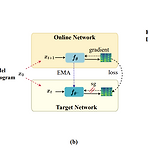
CM-TTS: Enhancing Real Time Text-to-Speech Synthesis Efficiency through Weighted Samplers and Consistency ModelsText-to-Speech에서 diffusion model을 사용하면 high-fidelity의 음성을 합성할 수 있지만 multi-step sampling으로 인해 real-time synthesis에는 한계가 있음한편으로 GAN과 diffusion model을 결합하여 denoising distribution을 근사하는 방식으로 추론 속도를 개선할 수 있지만, adversarial training으로 인해 모델 수렴의 어려움이 있음CM-TTSConsistency Model (CM)을 기반으로 advers..
 [Paper 리뷰] DurIAN-E2: Duration Informed Attention Network with Adaptive Variational Autoencoder and Adversarial Learning for Expressive Text-to-Speech Synthesis
[Paper 리뷰] DurIAN-E2: Duration Informed Attention Network with Adaptive Variational Autoencoder and Adversarial Learning for Expressive Text-to-Speech Synthesis
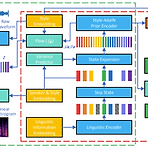
DurIAN-E2: Duration Informed Attention Network with Adaptive Variational Autoencoder and Adversarial Learning for Expressive Text-to-Speech SynthesisExpressive, high-fidelity text-to-speech를 위해 duration informed attention model을 고려할 수 있음DurIAN-E2Multiple stacked SwishRNN-based Transformer block을 linguistic encoder로 채택하고 Style-Adaptive Instance Normalization layer를 frame-level encoder에 추가하여 expre..
 [Paper 리뷰] DETS: End-to-End Single-Stage Text-to-Speech via Hierarchical Diffusion GAN Models
[Paper 리뷰] DETS: End-to-End Single-Stage Text-to-Speech via Hierarchical Diffusion GAN Models
DETS: End-to-End Single-Stage Text-to-Speech via Hierarchical Diffusion GAN ModelsEnd-to-End text-to-speech는 여전히 naturalness와 prosody diversity 측면에서 한계가 있음DETSHierarchical denoising diffusion GAN을 도입한 end-to-end frameworkDenoising distribution을 모델링하기 위해 non-Gaussian multi-modal function을 채택하여 다양한 pitch와 rhythm을 반영할 수 있는 one-to-many relationship을 학습논문 (ICASSP 2024) : Paper Link1. IntroductionText..
 [Paper 리뷰] StyleSpeech: Self-Supervised Style Enhancing with VQ-VAE-based Pre-training for Expressive Audiobook Speech Synthesis
[Paper 리뷰] StyleSpeech: Self-Supervised Style Enhancing with VQ-VAE-based Pre-training for Expressive Audiobook Speech Synthesis
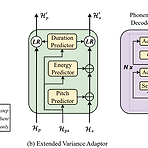
StyleSpeech: Self-Supervised Style Enhancing with VQ-VAE-based Pre-training for Expressive Audiobook Speech SynthesisAudiobook을 위한 음성 합성은 generalized architecture와 training data의 unbalanced style distribution으로 인해 한계가 있음StyleSpeechExpressive audiobook synthesis를 위해 VQ-VAE-based pre-training을 통한 self-supervised style enhancing method를 적용Text style encoder는 large-scale unlabeled text-only data로 p..
 [Paper 리뷰] ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
[Paper 리뷰] ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
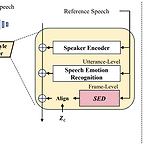
ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis기존의 emotional speech synthesis는 reference audio에서 추출된 utterance-level style embedding을 활용하기 때문에 speech prosody의 multi-scale property를 neglecting 하는 경우가 많음ED-TTSSpeech Emotion Diarization (SED)과 Speech Emotion Recognition (SER)을 활용하여 multi-scale에서 emotion을 모델링SER에서 추출한 utterance-level emotion..
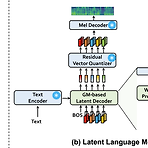 [Paper 리뷰] CLaM-TTS: Improving Neural Codec Language Modeling for Zero-Shot Text-to-Speech
[Paper 리뷰] CLaM-TTS: Improving Neural Codec Language Modeling for Zero-Shot Text-to-Speech
CLaM-TTS: Improving Neural Codec Language Modeling for Zero-Shot Text-to-SpeechZero-shot Text-to-Speech를 위해 audio의 discrete token에 대한 multiple stream을 encode 하는 neural audio codec을 활용할 수 있음이때 audio tokenization은 long sequence legnth와 multiple sequence modeling의 complexity로 인해 scalability의 한계가 있음CLaM-TTSToken length에 대한 뛰어난 compression을 달성하고, Language model이 한 번에 multiple token을 생성할 수 있도록 하는 prob..