

티스토리 뷰
Paper/TTS
[Paper 리뷰] DETS: End-to-End Single-Stage Text-to-Speech via Hierarchical Diffusion GAN Models
feVeRin 2024. 5. 16. 10:02반응형
DETS: End-to-End Single-Stage Text-to-Speech via Hierarchical Diffusion GAN Models
- End-to-End text-to-speech는 여전히 naturalness와 prosody diversity 측면에서 한계가 있음
- DETS
- Hierarchical denoising diffusion GAN을 도입한 end-to-end framework
- Denoising distribution을 모델링하기 위해 non-Gaussian multi-modal function을 채택하여 다양한 pitch와 rhythm을 반영할 수 있는 one-to-many relationship을 학습
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 주어진 text를 speech로 변환하는 것을 목표로 함
- 이때 autoregressive model은 word repetition, skipping 등의 robustness 문제와 상당히 느린 추론 속도를 가지므로, non-autoregressive end-to-end 방식을 주로 활용함
- 대표적으로 VITS는 normalizing flow와 adversarial training을 통해 ground-truth 수준의 MOS를 달성했음 - BUT, 여전히 end-to-end TTS 모델은 naturalness와 prosody diversity 측면에서 개선의 여지가 남아있음
- 특히 Denoising Diffusion Probabilistic Model (DDPM)은 image 뿐만 아니라 audio 합성에서도 좋은 성능을 보이고 있으므로, TTS의 diversity 향상을 위해 고려할만함
- 이때 autoregressive model은 word repetition, skipping 등의 robustness 문제와 상당히 느린 추론 속도를 가지므로, non-autoregressive end-to-end 방식을 주로 활용함
-> 그래서 end-to-end TTS를 위해 hierarchical denoising diffusion GAN을 채택한 DETS를 제안
- DETS
- 생성된 음성의 naturalness와 diversity를 개선하기 위해, conditional GAN은 denoising distribution을 모델링하는 non-Gaussian multi-modal function을 활용하여 diffusion duration predictor와 speech decoder를 구성
- 이를 통해 1 denoising step 만으로도 high-fidelity의 음성을 합성하도록 함
< Overall of DETS >
- Naturalness와 diversity가 개선된 TTS를 위한 hierarchical architecture를 채택
- 다양한 pitch, rhythm을 반영할 수 있는 one-to-many relationship을 express 하는 diffusion duration predictor와 speech decoder를 도입
- 결과적으로 기존 TTS 모델보다 뛰어난 성능을 달성
2. Method
- DETS는 adverasrial learning을 적용한 diffusion generator decoder와 diffusion duration predictor를 활용함
- Diffusion Duration Predictor
- VITS는 flow-based stochastic duration predictor를 사용해 naturalness를 향상했지만, flow-based method는 다른 duration에 대한 exploration이 제한적임
- 즉, stochastic sample에만 의존하면 real speech의 intonation을 전달하기 어려움
- 따라서 DETS는 더 높은 naturalness와 diversity를 위해 adversarial training이 적용된 diffusion duration predictor를 도입함
- 먼저 $x_{0}$를 Monotonic Alignment Search (MAS)를 통해 얻은 duration $d$, $x'_{0}$를 duration predictor에서 예측된 duration $\hat{d}$라고 하자
- 그러면 diffusion duration predictor training은:
(Eq. 1) $x_{t}=\sqrt{\bar{\alpha}_{t}}x_{0}+\sqrt{1-\bar{\alpha}_{t}}e, \,\, x'_{0}=G_{\theta_{1}}(Z,x_{t},t)$
- $\bar{\alpha}_{t}=\prod_{i=1}^{T}\alpha_{i}$, $\alpha_{i}$ : $e$의 constant parameter ($e\sim\mathcal{N}(0,I)$)
- $Z$ : posteriror encoder hidden state, $G_{\theta_{1}}$ : generator - 여기서 discriminator는:
(Eq. 2) $D_{\phi_{1}}(x_{t-1},x'_{t-1})=\text{real}/\text{fake}$
- Discriminator $D_{\phi_{1}}$은 puerly convolution network와 learnable parameter $\phi_{1}$을 가지는 $D_{\phi_{1}}(x_{t-1},x'_{t-1})$과 같이 표현됨
- 결과적으로 DETS는 denoising step이 큰 discrete-time diffusion model에 중점을 두고, conditional GAN을 사용하여 denoising distribution을 모델링함
- 즉, denoising function은 다음과 같이 모델링 됨:
(Eq. 3) $p_{\theta_{1}}(x_{t-1}|x_{t},Z)=\int p(Z)q(x_{t-1}|x_{t},x_{0}=G_{\theta_{1}}(Z,x_{t},t))dZ$
- $x_{0}$는 $\theta_{1}$로 parameterize 된 denoising diffusion GAN function $G_{\theta_{1}}(Z,x_{t},t)$를 통해 diffused sample $x_{t}$로부터 예측됨 - Training 중에 $x'_{t-1}$은 posterior distribution $q(x'_{t-1}|x'_{0},x_{t})$를 통해 sampling 됨
- $x'_{0}$ : $x_{0}$의 reconstructed version - 이후 예측된 tuple $(x'_{t-1},x_{t-1})$은 discriminator $D_{\phi_{1}}$에 전달되어 해당하는 bonafide counterpart $(x'_{t-1},x_{t})$에 대한 divergence $D_{adv}$를 계산함
- 즉, denoising function은 다음과 같이 모델링 됨:

- Diffusion Acoustic Decoder
- Diffusion acoustic decoder는 prior/posterior encoder에서 얻은 latent variable hidden state $Z$를 input으로 사용하여 audio waveform $y_{0}$를 생성함
- 앞선 duration predictor와 마찬가지로, acoustic decoder denoising function은 다음과 같이 모델링 됨:
(Eq. 4) $p_{\theta_{2}}(y_{t-1}|y_{t},Z)=\int p(Z)q(y_{t-1}|y_{t},y_{0}=G_{\theta_{2}}(Z,y_{t},t))dZ$ - 이때 가장 작은 $T$를 가진다는 가정하에서 ($T=1$) denoising diffusion GAN을 구성함
- 즉, DETS는 conditional GAN-based acoustic generator decoder $p_{\theta_{2}}(y_{t-1}|y_{t})$와 conditional GAN-based duration predictor $p_{\theta_{1}}$를 training 해야 함
- 여기서 denoising step 당 divergence $D_{adv}$를 최소화하는 adversarial loss를 사용하여 true audio와 duartion distribution $q(x_{t-1}|x_{t}), q(y_{t-1}|y_{t})$를 근사:
(Eq. 5) $\displaystyle{}\min_{\theta}\sum_{t\geq 1}\mathbb{E}_{q(x_{t})}\left[D_{adv}\left(q(x_{t-1}|x_{t}) || p_{\theta}(x_{t-1}|x_{t})\right)\right]+\min_{\theta}\sum_{t\geq 1}\mathbb{E}_{q(y_{t})}\left[D_{adv}\left( q(y_{t-1}|y_{t})||p_{\theta_{2}}(y_{t-1}|y_{t})\right)\right]$
- $D_{adv}$ : Kullback-Leibler Divergence
- 결과적으로 training procedure는 conditional GAN generator와 $p_{\theta}(\cdot), q_{\theta}(\cdot)$ operation을 수행하는 ability 간의 alignment로 볼 수 있음
- 해당 objective는 각 denoising iteration 동안 divergence $D_{adv}$를 최소화하는 adversarial loss를 통해 얻어짐
- 이때 denoising diffusion acoustic generator decoder를 implicit denoising model로 parameterize 함
- 앞선 duration predictor와 마찬가지로, acoustic decoder denoising function은 다음과 같이 모델링 됨:
- Training Loss
- DETS는 adversarial training을 위해,
- 다음의 2가지 discriminator를 활용함:
- $(x'_{t-1},x_{t-1})$ 또는 $(y'_{t-1},y_{t-1})$을 distinguish 하기 위한 JCU discriminator $D_{\phi_{1}}, D_{\phi_{2}}$
- Decoder $G_{\theta_{2}}$에 의해 생성된 output $y'_{0}$와 ground-truth waveform $y_{0}$를 distinguish 하는 multi-period discriminator $D_{\phi_{3}}$
- Discriminator는 다음의 loss를 최소화하도록 training 됨:
(Eq. 6) $\mathcal{L}_{D}=\sum_{t\geq 1}\left( \mathbb{E}_{q(x_{t})q(x_{t-1}|x_{t})}\left[(D_{\phi_{1}}(x_{t-1},x_{t},t)-1)^{2}\right]+\mathbb{E}_{p_{\theta_{1}}(x_{t-1}|x_{t})}\left[(D_{\phi_{1}}(x_{t-1},x_{t},t))^{2}\right] \right)$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,+\sum_{t\geq 1}\left( \mathbb{E}_{q(y_{t})q(y_{t-1}|y_{t})}\left[ (D_{\phi_{2}}(y_{t-1},y_{t},t)-1)^{2}\right] +\mathbb{E}_{p_{\theta_{2}}(y_{t-1}|y_{t})}\left[(D_{\phi_{2}}(y_{t-1},y_{t},t))^{2}\right] \right)$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,+\mathbb{E}_{(y_{0},Z)}\left[\left( D_{\phi_{3}}(y_{0})-1\right)^{2}+\left(D_{\phi_{3}}(G_{\theta_{3}}(Z))\right)^{2} \right]$ - Acoustic decoder reconstruction loss는 다음과 같이 acoustic generator를 training 하는 additional loss로도 사용됨:
(Eq. 7) $\mathcal{L}_{recon}=||y_{0}-y'_{0}||_{1}$
- 다음의 2가지 discriminator를 활용함:
3. Experiments
- Settings
- Dataset : LJSpeech
- Comparisons : Tacotron2, FastSpeech2, DiffGAN-TTS, VITS
- Results
- 전반적인 합성 품질 측면에서 제안된 DETS가 가장 우수한 성능을 보임
- Ablation study 측면에서 multi-period discriminator $D_{\phi_{3}}$와 diffusion duration predictor $G_{\theta_{1}}$을 제거하는 경우, 성능 저하가 발생함

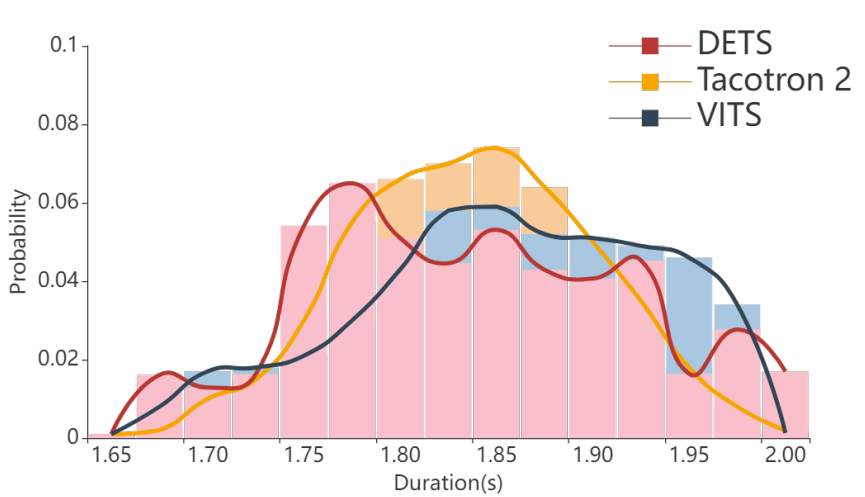
- 각 모델에서 생성된 utterance length를 비교해 보면, DiffGAN-TTS는 deterministic duration predictor로 인해 fixed-length utterance를 생성함
- 반면 DETS는 Tacotron2와 유사한 length distribution을 따르므로 더 다양한 length distribution을 가질 수 있음
반응형
'Paper > TTS' 카테고리의 다른 글
댓글