

 [Paper 리뷰] InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt
[Paper 리뷰] InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt
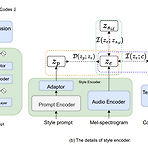
InstructTTS: Modelling Expressive TTS in Discrete Latent Space with Natural Language Style Prompt Expressive Text-to-Speech는 다양한 speech pattern을 반영하는 것을 목표로 하고, 이때 style을 control 하는 style prompt로 natural language를 활용할 수 있음 InstructTTS Self-supervised learning과 cross-modal metric learning을 활용하고 robust sentence embedding model을 얻기 위해 3-stage training을 제시 일반적인 mel-spectrogram 대신 vector-quantized ac..
 [Paper 리뷰] PromptStyle: Controllable Style Transfer for Text-to-Speech with Natural Language Descriptions
[Paper 리뷰] PromptStyle: Controllable Style Transfer for Text-to-Speech with Natural Language Descriptions
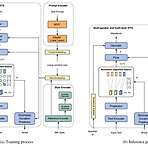
PromptStyle: Controllable Style Transfer for Text-to-Speech with Natural Language Descriptions Text-to-Speech에서 style control을 위해서는 개별적인 style category가 있는 expressive speech recording이 필요함 BUT, 실적용에서는 target style에 대한 referecne speech 없이 desired style에 대한 text description을 활용하는 것이 더 적합하다고 볼 수 있음 PromptStyle Text prompt-guided cross-speaker style transfer를 목표로 VITS와 cross-modal style encoder를 활용 ..
 [Paper 리뷰] PromptTTS++: Controlling Speaker Identity in Prompt-based Text-to-Speech using Natural Language Descriptions
[Paper 리뷰] PromptTTS++: Controlling Speaker Identity in Prompt-based Text-to-Speech using Natural Language Descriptions
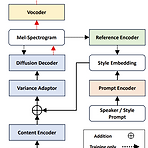
PromptTTS++: Controlling Speaker Identity in Prompt-based Text-to-Speech using Natural Language Descriptions Natural language description을 사용하여 speaker identity를 control 하는 prompt-based text-to-speech를 수행할 수 있음 PromptTTS++ Speaker identity를 control 하기 위해, speaking style과 independent 하도록 설계된 voice characteristic을 설명하는 speaker prompt를 도입 Diffusion-based acoustic model을 사용하여 다양한 speaker factor를 모델링..
 [Paper 리뷰] PromptTTS: Controllable Text-to-Speech with Text Descriptions
[Paper 리뷰] PromptTTS: Controllable Text-to-Speech with Text Descriptions
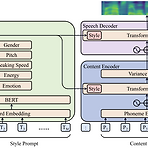
PromptTTS: Controllable Text-to-Speech with Text Descriptions Text description을 generation task를 guide 하는 데 사용할 수 있음 PromptTTS 음성 합성을 위해 style, content description이 포함된 prompt를 input으로 사용하는 text-to-speech 모델 Prompt에서 해당 representation을 추출하는 style encoder, content encoder를 활용하고, 추출된 style, content representation에 따라 음성을 합성하는 speech decoder로 구성됨 추가적으로 prompt가 포함된 dataset이 없으므로, 이에 해당하는 새로운 dataset..
 [Paper 리뷰] UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding
[Paper 리뷰] UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding
UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and VocodingSemantic token과 acoustic token으로 나누어진 discrete speech token을 활용하면 text-to-speech의 성능을 향상 가능대표적으로 VALL-E와 SPEAR-TTS는 짧은 speech prompt에서 추출된 acoustic token에 대한 autoregressive continuation으로 zero-shot speaker adaptation이 가능함- BUT, 해당 autoregressive 모델은 순차적으로 수행되므로 speaker editing에는 적합하지 않고, audio code..
 [Paper 리뷰] Period VITS: Variational Inference with Explicit Pitch Modeling for End-to-End Emotional Speech Synthesis
[Paper 리뷰] Period VITS: Variational Inference with Explicit Pitch Modeling for End-to-End Emotional Speech Synthesis
Period VITS: Variational Inference with Explicit Pitch Modeling for End-to-End Emotional Speech Synthesis End-to-End 방식은 acoustic model과 vocoder를 개별적으로 training 하는 cascade 방식보다 더 우수한 text-to-speech 성능을 달성할 수 있음 - BUT, dataset에 다양한 prosody나 emotional attribute가 포함되어 있는 경우 audible artifact와 unstable pitch를 생성하는 경우가 많음 Period VITS Unstable pitch 문제를 해결하기 위해 explicit periodicity generator를 사용하는 end-..