
티스토리 뷰
Paper/TTS
[Paper 리뷰] CrossSpeech: Speaker-Independent Acoustic Representation for Cross-Lingual Speech Synthesis
feVeRin 2024. 5. 27. 10:14반응형
CrossSpeech: Speaker-Independent Acoustic Representation for Cross-Lingual Speech Synthesis
- Cross-lingual Text-to-Speech 성능은 여전히 intra-lingual 성능보다 떨어짐
- CrossSpeech
- Speaker와 language information의 disentangling을 acoustic feature space level에서 효과적으로 disentangling 하여 cross-lingual text-to-speech 성능을 향상
- 이를 위해 Speaker-Independent Generator와 Speaker-Dependent Generator를 도입하고 각 information을 개별적으로 처리함으로써 disentangled speaker, language representation을 얻음
- Speaker-Independent Generator는 specific speaker distribution에 bias 되지 않는 speaker-independent acoustic representation을 생성
- Speaker-Dependent Generator는 speaker attribute를 characterize 하는 speaker-dependent variation을 모델링
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 일반적으로 intra-lingual application에 적합하도록 설계됨
- 즉, 다른 language를 사용하는 source speaker로부터 natural language를 생성하는 cross-lingual TTS의 품질은 여전히 intra-lingual TTS 보다 떨어짐
- 특히, cross-lingual TTS에서 발생하는 합성 품질 저하는 speaker-language entanglement로 인해 발생함
- 실제로 training set의 한 source speaker는 하나의 source language만을 speak하므로 speaker identity는 linguistic information에 의존적임
- 따라서 source language representation을 target lanugage representation으로 대체하는 경우, speaker identity를 preserve 하기 어려움
- 실제로 training set의 한 source speaker는 하나의 source language만을 speak하므로 speaker identity는 linguistic information에 의존적임
- 이러한 speaker-language entanglement 문제를 완화하고 cross-lingual TTS 성능을 향상하기 위해, 크게 2가지 방법을 고려할 수 있음
- Multiple language에서 share할 수 있는 language-agnostic text representation을 활용하는 방법
- Disentangled speaker/language information을 학습하는 방법
- BUT, 해당 방식에서 사용된 speaker/linguistic information decomposing은 input token level로 제한적임
- 즉, input token space에서는 각 representation이 분리되어 있지만, decoder의 input level에서 다시 결합되어 acoustic representation을 생성하므로 speaker-language entanglement가 다시 발생함
-> 그래서 decoder output frame level에서 speaker와 language information을 disentangle 하는 CrossSpeech를 제안
- CrossSpeech
- Cross-lingual TTS 성능 향상을 위해 Speaker-Independent Generator (SIG)와 Speaker-Dependent Generator (SDG)를 도입
- SIG는 mix-dynamic speaker layer normalization, speaker generalization loss, speaker-independent pitch predictor를 기반으로 speaker-independent acoustic representation을 생성
- SDG는 dynamic speaker layer normalization, speaker-dependent pitch predictor를 통해 speaker-dependent acoustic representation을 모델링
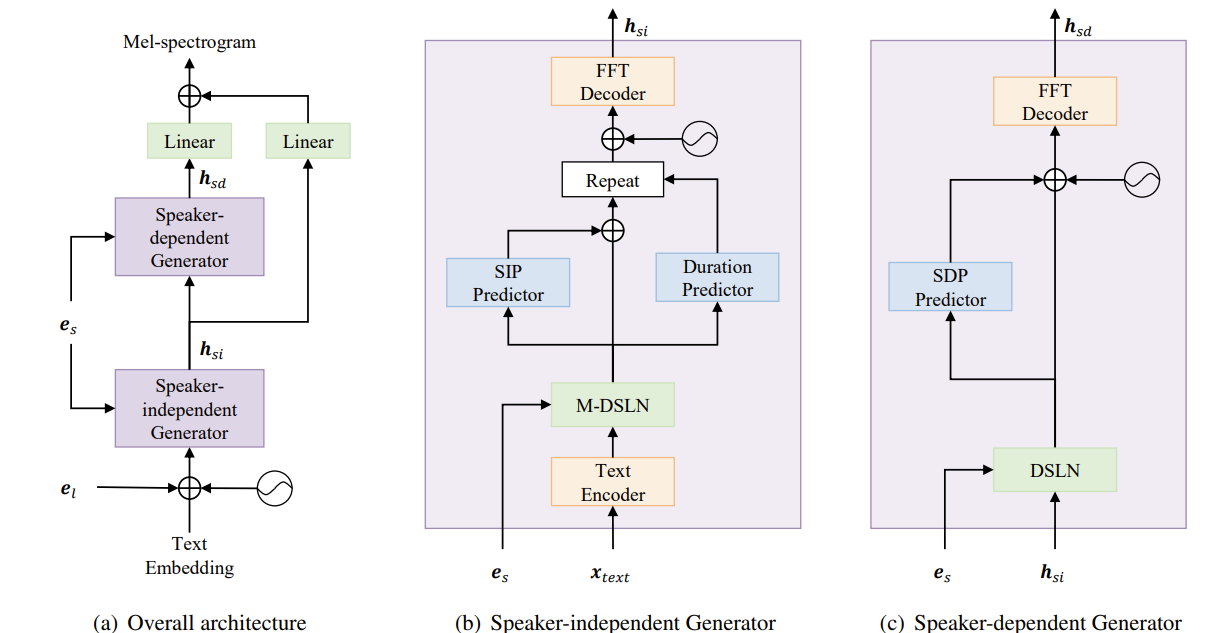
< Overall of CrossSpeech >
- Cross-lingual TTS에서 speaker와 language information의 disentangling을 위해, SIG와 SDG를 도입
- 결과적으로 speaker similarity 측면에서 뛰어난 성능을 달성하고 cross-lingual TTS의 품질을 향상
2. Model Architecture
- CrossSpeech는 online aligner를 채택한 FastPitch를 기반으로 설계됨
- Online aligner는 효율적인 training을 지원하고 각 language에 대해 pre-calculated aligner의 dependency를 제거하므로 cross-lingual TTS에서 language를 extending 하는데 유용함
- 한편으로 cross-lingual TTS에서 speaker-language entanglement를 회피하기 위해, generation pipeline을 speaker-independent module과 speaker-dependent module로 나눌 수 있음
- 따라서 CrossSpeech는 이를 기반으로 speaker-independent representation과 speaker-dependent representation을 각각 모델링하는 SIG와 SDG를 도입함
- SIG는 mix-dynamic speaker layer normalization (M-DSLN), speaker-independent pitch (SIP) predictor, speaker generalization loss ($\mathcal{L}_{sgr}$)을 사용함
- 이를 통해 특정 speaker distribution에 bias 되지 않은 speaker-independent acoustic representation $\mathbf{h}_{si}$를 생성 - SDG는 dynamic speaker layer normalization (DSLN)과 speaker-dependent pitch (SDP) predictor를 통해 speaker-dependent representation $\mathbf{h}_{sd}$를 모델링
- SIG는 mix-dynamic speaker layer normalization (M-DSLN), speaker-independent pitch (SIP) predictor, speaker generalization loss ($\mathcal{L}_{sgr}$)을 사용함
- 추가적으로 CrossSpeech는 single projection layer를 통해 예측된 mel-spectrogram에 $\mathbf{h}_{si}$를 제공함
3. Speaker-Independent Generator
- 논문은 generalizable speaker-independent representation을 생성하기 위해 M-DSLN과 speaker generalization loss를 포함하는 SIG를 도입함
- 추가적으로 speaker-independent prosodic variation을 학습하기 위해, 합성된 cross-lingual speech의 naturalness와 pitch accuracy를 향상하는 SIP predictor를 구성
- Speaker Generation
- DSLN은 단순한 summation이나 concatenation을 대신, speaker embedding을 기반으로 hidden feature를 adaptively modulate 하는 방법
- 먼저, hidden representation $\mathbf{h}$와 speaker embedding $\mathbf{e}_{s}$가 주어지면 speaker-conditioned representation은:
(Eq. 1) $\mathrm{DSLN}(\mathbf{h},\mathbf{e}_{s})=\mathbf{W}(\mathbf{e}_{s})\otimes \mathrm{LN}(\mathbf{h})+\mathbf{b}(\mathbf{e}_{s})$
- $\otimes$ : 1D convolution, $\mathrm{LN}$ : layer normalization
- Filter weight $\mathbf{W}(\mathbf{e}_{s})$와 bias $\mathbf{b}(\mathbf{e}_{s})$는 $\mathbf{e}_{s}$를 input으로 하는 single linear layer에 의해 예측됨 - 다음으로 GenerSpeech와 같이 DSLN을 mix-DSLN (M-DSLN)으로 확장함
- 해당 M-DSLN을 통해 text encoding이 specific speaker attribute로 bias 되는 것을 방지하고 generalization capability를 보장할 수 있음
- 이를 위해 fitler weight와 bias를 다음과 같이 mix 함:
(Eq. 2) $\mathbf{W}_{mix}(\mathbf{e}_{s})=\gamma\mathbf{W}(\mathbf{e}_{s})+(1-\gamma)\mathbf{W}(\tilde{\mathbf{e}}_{s})$
(Eq. 3) $\mathbf{b}_{mix}(\mathbf{e}_{s})=\gamma\mathbf{b}(\mathbf{e}_{s})+(1-\gamma)\mathbf{b}(\tilde{\mathbf{e}}_{s})$
- $\tilde{\mathbf{e}}_{s}$ : batch dimension을 따라 $\mathbf{e}_{s}$를 randomly shuffling 하여 얻어짐
- $\gamma$ : Beta distribution $\gamma\sim \mathrm{Beta}(\alpha,\alpha)$에서 sampling 됨 (논문에서는 $\alpha=2$로 설정) - 해당 mixed speaker information을 기반으로 M-DSLN은:
(Eq. 4) $\text{M-DSLN}(\mathbf{h}_{t},\mathbf{e}_{s})=\mathbf{W}_{mix}(\mathbf{e}_{s})\otimes\mathrm{LN}(\mathbf{h}_{t})+\mathbf{b}_{mix}(\mathbf{e}_{s})$
- $\mathbf{h}_{t}$ : text encoder로 예측된 hidden text representation
- 한편으로 generalization 성능을 더욱 향상하기 위해 Kullback-Leibler (KL) divergence에 기반한 speaker generalization loss $\mathcal{L}_{sgr}$을 도입함
- 해당 loss는 mixed speaker information으로 conditioning 된 text encoding과 original speaker information 간의 consistency를 보장함:
(Eq. 5) $\mathcal{L}_{sgr}^{o2m}=\mathrm{KL}(\mathrm{DSLN}(\mathbf{h}_{t},\mathbf{e}_{s})|| \text{M-DSLN}(\mathbf{h}_{t},\mathbf{e}_{s}))$
(Eq. 6) $\mathcal{L}_{sgr}^{m2o}=\mathrm{KL}(\text{M-DSLN}(\mathbf{h}_{t},\mathbf{e}_{s})|| \text{DSLN}(\mathbf{h}_{t},\mathbf{e}_{s}))$ - 결과적으로 $\mathcal{L}_{sgr} = \mathcal{L}_{sgr}^{o2m}+\mathcal{L}_{sgr}^{m2o}$
- 해당 loss는 mixed speaker information으로 conditioning 된 text encoding과 original speaker information 간의 consistency를 보장함:
- 이러한 M-DSLN과 speaker generalization loss를 채택함으로써, CrossSpeech는 lingustic representation에서 speaker-dependent information을 detach 할 수 있음
- 추가적으로 다음의 SIP와 duration predictor를 사용하여 speaker-independent variation을 예측함
- 먼저, hidden representation $\mathbf{h}$와 speaker embedding $\mathbf{e}_{s}$가 주어지면 speaker-conditioned representation은:
- Speaker-Independent Pitch Predictor
- Cross-lingual TTS는 training 중에 unseen 한 speaker-language combination으로 인해 speech variation을 예측하기 어려움
- 이를 해결하기 위해, CrossSpeech는 SIP predictor를 도입하여 multiple speaker에 대한 common attribute인 text-related pitch variation을 예측함
- 즉, M-DSLN의 output을 input으로 하여 SIP predictor는 pitch value의 rise/fall을 imply 하는 binary pitch contour sequence를 예측 - 먼저 SIP predictor를 training 하기 위해 모든 frame에 대한 ground-truth pitch value를 추출함
- 여기서 ground-truth pitch는 speaker-dependent value이므로, ground-truth pitch sequence를 speaker-dependent pitch sequence $\mathbf{p}^{(d)}$로 나타냄
- 다음으로 SIP predictor는 input token level에서 pitch value를 처리하므로 ground-truth duration을 사용하여 모든 input token에 대해 $\mathbf{p}^{(d)}$를 평균함
- 최종적으로, 평균된 $\mathbf{p}^{(d)}$를 다음의 binary sequence로 변환하여 speaker-independent target pitch sequence $\mathbf{p}^{(i)}$를 얻음:
(Eq. 7) $p_{n}^{(i)}=\left\{\begin{matrix} 1, & \bar{p}_{n-1}^{(d)}<\bar{p}_{n}^{(d)} \\ 0, & \text{otherwise} \\ \end{matrix}\right.$
- $\bar{p}_{n}^{(d)}$ : 평균된 $\mathbf{p}^{(d)}$의 $n$-th value, $p_{n}^{(i)}$ : $\mathbf{p}^{(i)}$의 $n$-th value
- $n\in\{1,2,3,...,N\}$이고, $N$은 input token length - 이때 해당 SIP predictor를 최적화하기 위해 binary cross-entropy를 사용:
(Eq. 8) $\mathcal{L}_{sip}=-\sum_{n}^{N}[p_{n}^{(i)}\log \hat{p}_{n}^{(i)}+(1-p_{n}^{(i)})\log(1-\hat{p}_{n}^{(i)})]$
- $\hat{p}_{n}^{(i)}$ : 예측된 speaker-independent pitch의 $n$-th value
- Speaker-independent pitch sequence는 1D convolution layer를 통과한 다음, hidden sequence에 추가됨
- Resulting sum은 token duration을 기준으로 upsample 된 다음, upsampled hidden sequence를 speaker-independent acoustic representation $\mathbf{h}_{si}$로 변환하는 Feed-Forward Transformer decoder로 전달됨
- 이때 CrossSpeech의 duration predictor는 speaker-generalized representation을 input으로 사용하므로 general duration information을 학습할 수 있음
- 따라서, 이를 통해 speaker identity와 independent 한 token duration을 예측하고 cross-lingual TTS에서 duration prediction을 stabilize 할 수 있음
- 이를 해결하기 위해, CrossSpeech는 SIP predictor를 도입하여 multiple speaker에 대한 common attribute인 text-related pitch variation을 예측함
4. Speaker-Dependent Generator
- Speaker-dependent attribute를 모델링하기 위해 DSLN과 SDP predictor로 구성된 SDG를 설계함
- 먼저 DSLN은 speaker embedding $\mathbf{e}_{s}$와 speaker-independent acoustic representation $\mathbf{h}_{si}$를 input으로 하여 speaker-adapted hidden feature를 생성함
- 이후, 해당 speaker-adapted hidden feature를 활용하여 SDP predictor는 frame-level에서 speaker-dependent pitch embedding을 생성함 - 이를 위해 speaker-dependent target pitch sequence $\mathbf{p}^{(d)}$를 추출하고, MSE loss를 통해 SDP predictor를 최적화함:
(Eq. 9) $\mathcal{L}_{sdp}=||\mathbf{p}^{(d)}-\hat{\mathbf{p}}^{(d)}||_{2}$
- $\hat{\mathbf{p}}^{(d)}$ : 예측된 speaker-dependent pitch sequence
- 여기서 speaker-dependent pitch sequence는 1D convolution layer를 통과한 다음, hidden sequence로 sum 되고, FFT decoder는 adapted hidden sequence로부터 speaker-dependent acoustic representation $\mathbf{h}_{sd}$를 생성함 - 결과적으로 overall training objective $\mathcal{L}_{tot}$는:
(Eq. 10) $\mathcal{L}_{tot}=\mathcal{L}_{rec}+\mathcal{L}_{align}+\lambda_{dur}\mathcal{L}_{dur}+\lambda_{sgr}\mathcal{L}_{sgr}+\lambda_{sip}\mathcal{L}_{sip}+\lambda_{sdp}\mathcal{L}_{sdp}$
- $\mathcal{L}_{rec}$ : target과 예측된 mel-spectrogram 간의 MSE loss
- $\mathcal{L}_{align}$ : online aligner의 alignment loss
- $\mathcal{L}_{dur}$ : target과 예측된 duration 간의 MSE loss
- 논문에서는 $\lambda_{dur}=\lambda_{sgr}=\lambda_{sip}=\lambda_{sdp}=0.1$로 설정
- 먼저 DSLN은 speaker embedding $\mathbf{e}_{s}$와 speaker-independent acoustic representation $\mathbf{h}_{si}$를 input으로 하여 speaker-adapted hidden feature를 생성함
5. Experiments
- Settings
- Dataset : LJSpeech, English/Chinese/Korean dataset (internal)
- Comparisons : FastPitch, SANE-TTS, Cross-Lingual TTS, Multi-Lingual TTS
- Results
- Quality Comparison
- CrossSpeech는 cross-lingual setting에서 가장 우수한 성능을 달성함
- Intra-lingual 측면에서도 CrossSpeech는 큰 성능 저하 없이 기존 모델과 비슷한 수준의 합성 품질을 보임
- CrossSpeech는 cross-lingual setting에서 가장 우수한 성능을 달성함

- Ablation Study
- Ablation study 측면에서 CrossSpeech의 각 component를 제거하면 성능 저하가 발생함
- 즉, 제안된 component들은 CrossSpeech 성능 향상에 유효함

- Acoustic Feature Space
- Speaker generalization capability를 알아보기 위해, (a) pojected speaker-independent acoustic representation과 (b) final mel-spectrogram에 대한 $t$-SNE 결과를 확인해 보면
- (a)에서 embedding은 speaker에 의해 cluster 되지 않고 random 하게 spread 되어 있음
- 이는 speaker-independent representation이 speaker-related information에 bias 되지 않고 text-related variation만 포함하는 것을 의미함 - (b)의 경우, embedding은 speaker에 따라 well-cluster 되는 것으로 나타남
- 이는 CrossSpeech가 SDG를 통해 speaker-dependent attribute를 효과적으로 학습할 수 있다는 것을 의미함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글