

 [Paper 리뷰] CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
[Paper 리뷰] CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model
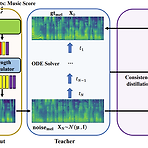
CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency ModelDenoising Diffusion Probabilistic Model은 음성 합성에서 우수한 성능을 보이고 있지만, 고품질의 sample을 얻기 위해서는 많은 iterative step이 필요함- 결과적으로 추론 속도 저하로 이어짐CoMoSpeechSingle diffusion sampling step만으로 고품질의 합성을 수행하는 Consistency model-based 음성 합성 모델Consistency constraint는 diffusion-based teacher model에서 consistency model을 distill 하기 위해 사용됨논문 (MM 20..
 [Paper 리뷰] Matcha-TTS: A Fast TTS Architecture with Conditional Flow Matching
[Paper 리뷰] Matcha-TTS: A Fast TTS Architecture with Conditional Flow Matching
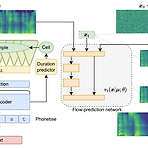
Matcha-TTS: A Fast TTS Architecture with Conditional Flow MatchingOptimal-transport conditional flow matching을 사용하여 text-to-speech에서의 acoustic modeling 속도를 향상할 수 있음Matcha-TTS Optimal-transport conditional flow matching을 기반으로 기존의 score matching 방식보다 더 적은 step으로 고품질의 output을 제공하는 ODE-based decoder를 얻음Probabilistic, non-autregressive 하게 동작하고 external alignment 없이 scratch로 학습 가능논문 (ICASSP 2024) : Pa..
 [Paper 리뷰] Mels-TTS: Multi-Emotion Multi-Lingual Multi-Speaker Text-to-Speech System via Disentangled Style Tokens
[Paper 리뷰] Mels-TTS: Multi-Emotion Multi-Lingual Multi-Speaker Text-to-Speech System via Disentangled Style Tokens
Mels-TTS: Multi-Emotion Multi-Lingual Multi-Speaker Text-to-Speech System via Disentangled Style Tokens효과적인 emotion transfer를 위해 disentangled style token을 활용할 수 있음Mels-TTSGlobal style token에서 영감을 받아 emotion, language, speaker, residual information을 disentangle 하는 개별적인 style token을 활용Attention mechanism을 적용하여 각 style token에서 target speech에 대한 speech attribute를 학습논문 (ICASSP 2024) : ..
 [Paper 리뷰] MM-TTS: Multi-Modal Prompt Based Style Transfer for Expressive Text-to-Speech Synthesis
[Paper 리뷰] MM-TTS: Multi-Modal Prompt Based Style Transfer for Expressive Text-to-Speech Synthesis
MM-TTS: Multi-Modal Prompt Based Style Transfer for Expressive Text-to-Speech SynthesisText-to-Speech에서 style transfer는 style information을 text context에 반영하여 특정 style을 가진 음성을 생성하는 것을 목표로 함BUT, 기존의 style transfer 방식들은 fixed emotional label이나 reference clip에 의존하므로 flexible 한 style transfer의 한계가 있음MM-TTS생성되는 음성의 style을 control 하기 위해 reference speech, emotional facial image, text description 등을 포함하는..
 [Paper 리뷰] DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation
[Paper 리뷰] DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation
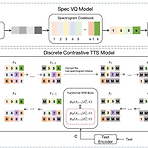
DCTTS: Discrete Diffusion Model with Contrastive Learning for Text-to-Speech Generation Text-to-Speech에서 latent diffusion model을 우수한 성능을 보이고 있지만, resource consumption이 크고 추론 속도가 느림 DCTTS Discrete diffusion model과 contrastive learning을 결합한 text-to-speech 모델 간단한 text encoder와 VQ model을 사용하여 raw data를 discrete space로 compress 한 다음, discrete space에서 diffusion model을 training 함 이때 diffusion step 수를 줄..
 [Paper 리뷰] VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching
[Paper 리뷰] VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching
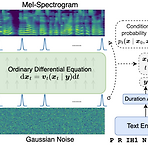
VoiceFlow: Efficient Text-to-Speech with Rectified Flow Matching Text-to-Speech에서 diffusion model은 우수한 성능을 보이고 있지만 sampling complexity로 인해 비효율적임 VoiceFlow 제한된 sampling step으로도 고품질의 합성을 수행할 수 있는 rectified flow matching을 활용 Text input을 condition으로 하여 mel-spectrogram을 ordinary differential equation을 통해 추정 Rectified flow는 효율적인 합성을 위해 sampling trajectory를 straighten 함 논문 (ICASSP 2024) : Paper Link 1...