

 [결산] 2004년도 앨범 결산
[결산] 2004년도 앨범 결산
선정 기준 : 작성자 마음대로 뽑습니다. 2004년도 앨범 결산 1. 개인적인 추천 앨범 The Killers - : 80년대 뉴웨이브와 2000년대 포스트-펑크 리바이벌의 새로운 교차점을 제시한 The Killers의 매력적인 데뷔 앨범입니다. 변화무쌍한 신스가 이끌어낸 화려한 트랙들과 밤거리를 닮은 어스름한 이면들 간의 조화는, 이 앨범을 고평가 할 수밖에 없도록 만듭니다. The Killers - 'Mr.Brightside' 2. 올해의 국내 싱글 못 - '카페인' : 각성제의 대표주자인 '카페인'이라는 제목과는 완전히 대비되는 성질을 전달하는 못의 아이러니한 싱글입니다. 앨범을 지배하는 빛바랜 신스와 차오르는 회색빛 기타는, 지독한 음울감으로 리스너를 서서히 침전시킵니다. 못 - '카페인' 3. ..
 [Paper 리뷰] InferGrad: Improving Diffusion Models for Vocoder by Considering Inference in Training
[Paper 리뷰] InferGrad: Improving Diffusion Models for Vocoder by Considering Inference in Training
InferGrad: Improving Diffusion Models for Vocoder by Considering Inference in Training Denoising diffusion probabilistic model은 추론 과정에서 많은 반복이 필요하므로 추론 속도가 느림 추론 속도 향상을 위해 추론 schedule을 최적화하는 것이 필요 - However, 일반적으로 추론과 학습 process는 개별적으로 최적화됨 InferGrad 추론 process를 학습에 통합한 vocoder용 diffusion model 학습 중 추론 schedule에 따라 reverse process를 통해 random noise로부터 data를 생성하여, 생성된 data와 실제의 차이를 최소화 논문 (ICASSP ..
 [Paper 리뷰] Personalized Lightweight Text-to-Speech: Voice Cloning with Adaptive Structured Pruning
[Paper 리뷰] Personalized Lightweight Text-to-Speech: Voice Cloning with Adaptive Structured Pruning
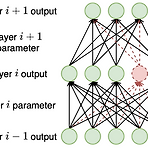
Personalized Lightweight Text-to-Speech: Voice Cloning with Adpative Structured Pruning Personalized Text-to-Speech를 위해서는 많은 양의 recording과 큰 규모의 모델을 필요로 하므로 mobile device 배포에 적합하지 않음 이를 해결하기 위해 일반적으로 pre-train 된 Text-to-Speech 모델을 fine-tuning 하는 voice cloning을 활용함 - 여전히 pre-train된 대규모 모델에 기반을 두고 있어 한계가 있음 Adaptive Structured Pruning Trainable structured pruning을 voice cloning에 적용 Voice-cloning d..
 [Paper 리뷰] LiteSing: Towards Fast, Lightweight and Expressive Singing Voice Synthesis
[Paper 리뷰] LiteSing: Towards Fast, Lightweight and Expressive Singing Voice Synthesis
LiteSing: Towards Fast, Lightweight and Expressive Singing Voice Synthesis 경량화된 고품질의 Singing Voice Synthesis 시스템이 필요함 LiteSing Generative Adversarial Network architecture 하에서 악보의 full condition을 예측하고, 해당 condition에서 acoustic feature를 생성 Dynamic spectrogram energy, Voiced/Unvoiced decision, Dynamic pitch curve를 구성해 expressiveness를 향상 Pitch와 timbre를 개별적으로 예측하여 두 feature의 interdependence를 회피 논문 (IC..
 [결산] 2003년도 앨범 결산
[결산] 2003년도 앨범 결산
선정 기준 : 작성자 마음대로 뽑습니다. 2003년도 앨범 결산 1. 개인적인 추천 앨범 Longwave - : 뉴욕의 모두가 포스트-펑크 리바이벌의 열기에 한창 빠져있을 때, Longwave는 불친절한 슈게이즈의 세계로 빠져들어갔습니다. 그 결과 Longwave는 에서 분위기 있는 멜로디 라인과 윙윙거리는 기타 피드백을 조합하며 새로운 감성의 앨범을 만들어 냈습니다. Longwave -'Tidal Wave' 2. 올해의 국내 싱글 YB - '잊을게' : 시원한 윤도현의 보컬과 깔끔한 기타 라인이 인상적인 이 곡은, YB가 한참 정체성과 대중성의 경계에서 혼란을 겪던 시기에 발매되었습니다. 하지만 그 고민이 무색하게도 곡은 상업적으로 시원하게 성공해 버리며 나름의 방향성을 제시해 주었습니다. YB - '..
 [Paper 리뷰] LiteTTS: A Lightweight Mel-spectrogram-free Text-to-wave Synthesizer Based on Generative Adversarial Networks
[Paper 리뷰] LiteTTS: A Lightweight Mel-spectrogram-free Text-to-wave Synthesizer Based on Generative Adversarial Networks
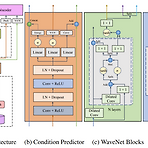
LiteTTS: A Lightweight Mel-spectrogram-free Text-to-wave Synthesizer Based on Generative Adversarial Networks 빠른 속도로 고품질의 음성을 합성할 수 있는 lightweight end-to-end text-to-speech 모델이 필요 LiteTTS Feature prediction module과 waveform generation module을 결합한 single framework Feature prediction module은 input text 및 prosodic information에 대한 latent space embedding을 추정 Waveform generation module은 추정된 latent emb..