
티스토리 뷰
Paper/TTS
[Paper 리뷰] Personalized Lightweight Text-to-Speech: Voice Cloning with Adaptive Structured Pruning
feVeRin 2024. 1. 10. 13:22반응형
Personalized Lightweight Text-to-Speech: Voice Cloning with Adpative Structured Pruning
- Personalized Text-to-Speech를 위해서는 많은 양의 recording과 큰 규모의 모델을 필요로 하므로 mobile device 배포에 적합하지 않음
- 이를 해결하기 위해 일반적으로 pre-train 된 Text-to-Speech 모델을 fine-tuning 하는 voice cloning을 활용함
- 여전히 pre-train된 대규모 모델에 기반을 두고 있어 한계가 있음 - Adaptive Structured Pruning
- Trainable structured pruning을 voice cloning에 적용
- Voice-cloning data로 structured pruning mask를 학습하여 각 target speaker에 대한 unique 한 pruned 모델을 얻음
- 논문 (ICASSP 2023) : Paper Link
1. Introduction
- End-to-End Text-to-Speech (TTS)는 꾸준히 연구되고 있지만, 그에 대한 customization은 충분한 연구가 부족함
- 특히 고품질의 single-speaker end-to-end TTS 시스템은 학습을 위해 많은 양의 data와 큰 규모의 모델을 필요로 함
- 몇 시간 이상의 음성 recording과 학습 시간을 요구하기 때문에 실용적이지 않음 - 따라서 personalized TTS는 mobile device에서의 활용을 궁극적인 목표로 함
- 제한된 학습 data, 빠른 학습 속도, 작은 모델 size의 3가지 측면을 모두 만족해야 함 - BUT, 제한된 학습 data를 활용해 scratch로 모델을 학습하는 것은 어려움
- 고품질 합성을 위해 transfer learning을 주로 활용
- 이렇게 unseen speaker에 대해 학습된 TTS 모델을 transfer 하는 것을 Voice Cloning이라고 함
- 특히 고품질의 single-speaker end-to-end TTS 시스템은 학습을 위해 많은 양의 data와 큰 규모의 모델을 필요로 함
- TTS 모델 학습 외에도 personalized TTS 작업은 계산 비용, 속도 측면에서 모델 size를 줄이는 것도 중요함
- LightSpeech의 경우, Neural Architecture Search를 활용하여 제한된 환경 내에서 최적의 모델 size를 결정
- Unstructured pruning method를 활용하여 모델 size를 줄일 수도 있음
- 이 경우 sparse matrix 계산이 까다롭다는 문제가 있음
-> 그래서 personalized TTS의 voice cloning 작업을 경량화하기 위해 learnable structured pruning method를 도입
- Adaptive Structured Pruning
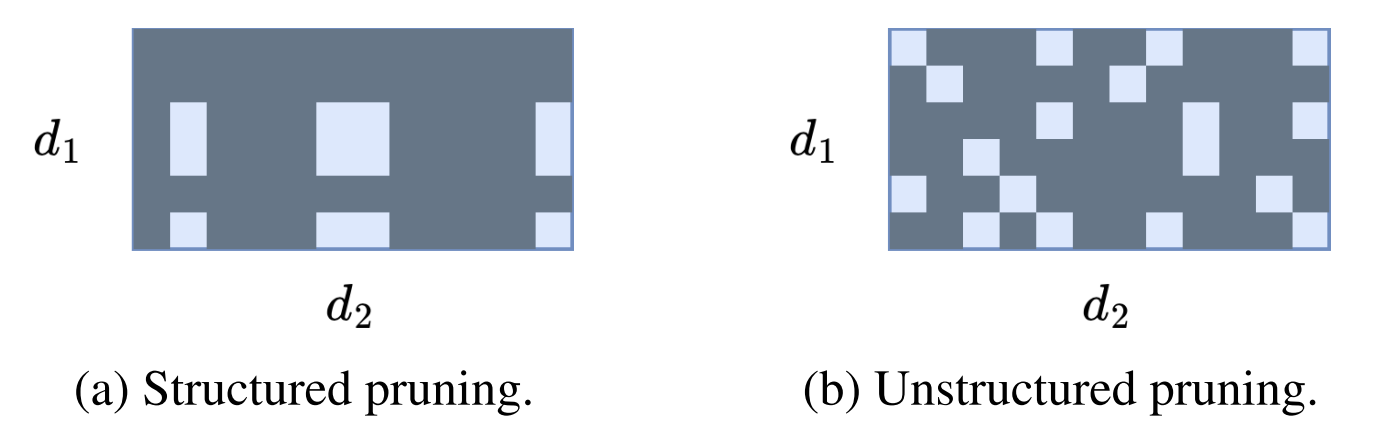
- Unstructured pruning과 달리 각 weight matrix의 channel을 제거하여 sparse matrix 보다 더 작은 weight matrix를 생성
- 아래 그림과 같이 structured pruning은 prune 되지 않은 파란색 부분을 더 작은 matrix로 연결할 수 있기 때문
- 결과적으로 matrix 계산을 가속화하고 계산 비용을 줄일 수 있음 - Pruning 작업은 weight magnitude와 같은 pruning parameter에 의존
- 적절한 channel pruning을 위한 learnable mask를 도입
- 각 target speaker에 대한 personalized pruning이 가능
- Unstructured pruning과 달리 각 weight matrix의 channel을 제거하여 sparse matrix 보다 더 작은 weight matrix를 생성
< Overall of This Paper >
- Voice cloning을 위해 structured pruning을 도입
- Few-shot data만 사용하여 learnable pruning mask를 학습
2. Background
- 본 논문은 pruning을 적용하는 TTS 모델로써 FastSpeech2를 활용
- Voice Cloning
- Voice cloning은 few-shot dataset을 통해 target speaker의 음성에 대한 TTS 모델을 생성함
- 이때, 제한된 data를 활용해 scratch로 학습하는 것은 overfitting 및 합성 품질을 저해함
- 결과적으로 pre-train 된 multi-speaker TTS 모델을 활용해 fine-tuning 하는 것이 선호됨
- Fine-tuning 가속화를 위해 meta-learning 등의 방법을 활용할 수 있음
- Transformer Block
- FastSpeech2는 encoder, decoder, variance adaptor 등으로 구성됨
- Encoder와 Decoder는 transformer block을 stack 하여 구성되고, variance adpator는 CNN layer를 활용함
- 각 transformer block은 Multi-Head Self-Attention (MHA) layer와 Feed-Forward (FFN) layer를 가짐 - 이때 input $X \in \mathcal{R}^{L \times d}$를 사용하여 self-attention layer를 공식화하면:
$SelfAtt(W_{Q}, W_{K}, W_{V}, X) = softmax ( \frac {X W_{Q} W_{K}^{T} X^{T} } {\sqrt{d_{k}}} ) X W_{V}$
- $L$ : input $X$의 length, $d$ : input $X$의 hidden dimension
- $d_{k}$ : self-attention layer의 hidden dimension
- $W_{Q}, W_{K}, W_{V} \in \mathcal{R}^{d \times d_{k}}$ : 각각 query, key, value matrix - Input $X$에 대해 $N_{h}$개의 head를 가진 MHA layer의 output은:
$MHA(X) = \sum_{i=1}^{N_{h}} SelfAtt (W_{Q}^{(i)}, W_{K}^{(i)}, W_{V}^{(i)}, X) W_{O}^{(i)}$
- $ W_{O} \in \mathcal{R}^{d_{k} \times d}$ : output matrix - Up-projection과 down-projection layer를 포함하는 FFN layer는:
$FFN(X) = ReLU(XW_{U})W_{D}$
- $W_{U} \in \mathcal{R}^{d \times d_{f}}, W_{D} \in \mathcal{R}^{d_{f} \times d}$ : 각각 up/down projection - 결과적으로 transformer block의 output은:
$X' = LN(MHA(X) + X)$
$TransformerBlock(X) = LN(FFN(X') + X')$
- $LN$ : layer norm
- Encoder와 Decoder는 transformer block을 stack 하여 구성되고, variance adpator는 CNN layer를 활용함
- Structured Pruning
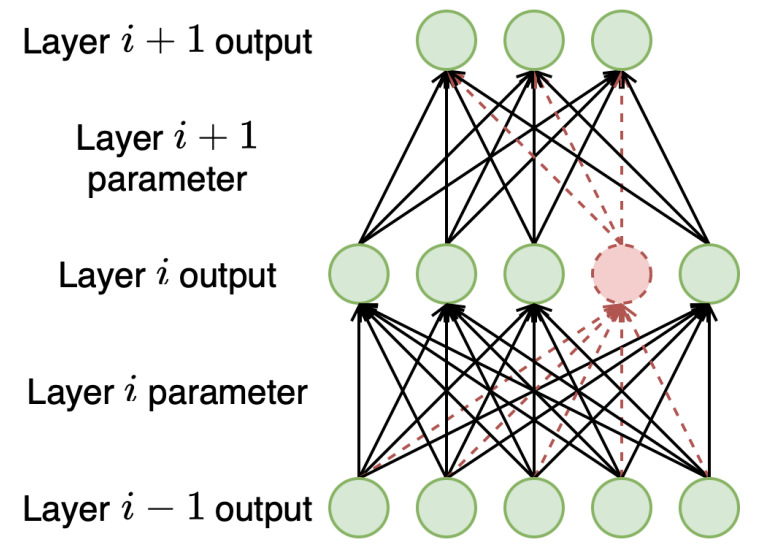
- Unstructured pruning은 weight matrix의 element와 같은 개별 model parameter를 선택하여 제거
- Structured pruning은 각 layer의 output에서 제거할 특정 neuron을 선정
- Pruning with $L_{0}$ Regularization
- 대부분의 pruning method는 parameter magnitude와 같은 criteria를 기반으로 binary pruning mask를 결정함
- BUT, 이러한 criteria는 target speaker에 대한 personalized pruning에 적합하지 않음
- 이를 위해 binary pruning mask에 $L_{0}$ norm을 추가
- Discrete binary mask는 non-differentiable 하기 때문에, hard-concrete 분포를 활용하여 continuous binary mask로 변환하고 trainable 하게 만듦
- 이때, regularization term은 모든 mask에 대한 $L_{1}$ norm과 같음 - 아래의 hard-concrete 분포에서 learnable mask $\mathbf{z}$를 sampling 하면:
(Eq.1)
$\mathbf{u} = U(0,1)$
$\mathbf{s} = Sigmoid \left ( \frac{ log \, \mathbf{u} - log \, (1-\mathbf{u}) + log \, \alpha} {\beta} \right)$
$\mathbf{z} = min(1, max(0, \gamma, + \mathbf{s} (\eta - \gamma)))$
- $\mathbf{u}$ : uniform 분포 $U(0,1)$에서 sampling 된 random variable
- $\gamma \leq 0, \eta \geq 1$ : sigmoid function의 output interval을 $(0,1)$에서 $(\gamma, \eta)$로 조정
- $\beta$ : function의 steepness를 조절 - 이때, 주요 learnable masking parameter는 Bernoulli 분포에서 sampling 되는 $\mathbf{z}$의 logit인 $\log \, \alpha$
- Weight matrix $W \in \mathcal{R}^{d_{1} \times d_{2}}$에 대해 weight pruning을 수행하기 위해서는,
- 연관된 learnable mask $\mathbf{z} \in \mathcal{R}^{d_{1} \times d_{2}}$를 생성해야 함
- Structured learning을 사용하기 위해, 해당 mask는 2개의 learnable masking parameter $\alpha_{1} \in \mathcal{R}^{d_{1}}$, $\alpha_{2} \in \mathcal{R}^{d_{2}}$가 필요
- 해당 parameter는 (Eq.1)을 사용하여 input dimension mask $\mathbf{z}_{1}$과 output dimension mask $\mathbf{z}_{2}$를 생성 - 이후 최종 maks $\mathbf{z} = \mathbf{z}_{1} \mathbf{z}_{2}^{T}$를 얻고,
- 이로부터 pruned weight matrix $W' = W \odot \mathbf{z}$를 얻음
- $\odot$ : element-wise dot product
- Structured learning을 사용하기 위해, 해당 mask는 2개의 learnable masking parameter $\alpha_{1} \in \mathcal{R}^{d_{1}}$, $\alpha_{2} \in \mathcal{R}^{d_{2}}$가 필요
- 연관된 learnable mask $\mathbf{z} \in \mathcal{R}^{d_{1} \times d_{2}}$를 생성해야 함
3. Method
- Structured Pruning FastSpeech2
- Data에 의해서 결정되는 input/output dimension을 제외한 FastSpeech2의 모든 dimension은 prunable 함
- Prunable dimension의 목록은:
- 모델 $d$에 영향을 주는 hidden dimension들
- Encoder/Decoder의 positional encoding
- 모든 embedding dimension
- MHA layer의 $W_{Q}^{(i)}, W_{K}^{(i)}, W_{V}^{(i)}, W_{O}^{(i)}$
- FFN layer의 $W_{U}, W_{D}$
- Layer noramlization의 scale, shift
- Variance adaptor, Output linear layer의 input channel - $W_{Q}^{(i)}, W_{K}^{(i)}, W_{V}^{(i)}, W_{O}^{(i)}$에 영향을 주는 MHA layer의 $N_{h}, d_{k}^{(i)}$
- $W_{U}, W_{D}$에 영향을 주는 FFN layer의 $d_{f}^{(i)}$
- Variance adaptor와 post-net의 hidden dimension
- 모델 $d$에 영향을 주는 hidden dimension들
- Pruning을 위해 위 목록들의 각 dimension에 대해 learnable masking parameter를 생성함
- 모델 dimension $d$는 $\alpha_{d}$로 masking
- MHA dimension $d_{k}^{(i)}$는 $\alpha_{k}^{(i)}$로 masking
- FFN dimension $d_{f}^{(i)}$는 $\alpha_{f}^{(i)}$로 masking
- MHA head $N_{h}$는 $\alpha_{h}$로 masking - 학습 시, input/output connection을 기반으로 각 TTS parameter에 대한 mask $\mathbf{z}$를 생성
- $d$는 residual connection으로 인해 많은 parameter에 영향을 주므로, masking parameter $\alpha_{d}$에 의해 생성된 $\mathbf{z}_{d}$를 기반으로 해당 parameter를 $\mathbf{z}$로 masking
- Prunable dimension의 목록은:
- Optimizing Adaptive Structured Pruning Mask
- FastSpeech2의 모든 parameter에 대해 pruning mask $\mathbf{z}$를 생성하기 위해, learnable masking paremeter $\alpha$를 도입
- 이후 모든 mask에 대한 $L_{1}$ norm을 계산하여 regularization term으로 사용:
$L_{reg} = \sum_{\mathbf{z}} ||\mathbf{z}||_{1}$ - 학습 시작 시, sampling 된 $\mathbf{z}$가 1에 가까워지도록 모든 $\alpha$값을 큰 값으로 초기화함
- 결과적으로 voice-cloning 모델 pruning에 대한 최종적인 loss는:
$L_{total} = L_{TTS} + \frac{1}{\lambda} L_{reg} = L_{TTS} + \frac{1}{\lambda} \sum_{\mathbf{z}} ||\mathbf{z}||_{1}$
- $\lambda$ : regularization에 대한 weighting factor
- 논문에서는 $\lambda$를 TTS parameter의 총 개수로 설정하여, regularization term을 모델의 density로 만듦
- 이후 모든 mask에 대한 $L_{1}$ norm을 계산하여 regularization term으로 사용:
- Inference
- 추론 시에는 (Eq.1)를 사용하여 continuous pruning maks $\mathbf{z}$를 생성하는 과정을 생략함
- 대신 각 $log \, \alpha$로부터 binary pruning mask를 직접 결정
- 여기서 $Sigmoid((log \, \alpha) / \beta)$는 Bernoulli 분포를 나타냄
- 이때, 경험적으로 대부분의 확률은 0 또는 1에 가까운 값을 가지고 전체의 2%만이 $(0.05, 0.95)$ 범위에 속함
-> 따라서, $Sigmoid((log \, \alpha) / \beta) = 0.5$를 threshold로 사용 - 결과적으로 $\mathbf{z}$의 각 element $z_{i}$와 corresponding element $\alpha_{i}$에 대해, 아래의 condition을 계산할 수 있음:
$z_{i} = \left \{ \begin{matrix} 0, \,\, Sigmoid((log \, \alpha_{i}) / \beta) < 0.5 \\ 1, \,\, Sigmoid((log \, \alpha_{i}) / \beta) \geq 0.5 \end{matrix} \right .$
- 대신 각 $log \, \alpha$로부터 binary pruning mask를 직접 결정
4. Experiments
- Settings
- Dataset : LibriTTS, VCTK
- Vocoder : MelGAN
- FastSpeech2를 기반으로 8-shot voice cloning을 목표로 하여 fine-tuning과 pruning을 적용
- Results
- GT : ground-truth, GT + Vocoder : ground-truth with Vocoder
- FT : fine-tuning, Prune : pruning with voice-cloning data, Prune' : pruning with pre-training data
- Pre-training data만 사용하여 pruning 된 Prune'의 경우 낮은 성능을 보임
- Voice cloning을 적용한 모델들은 높은 naturalness를 보임

- Speaker classifier를 통한 합성 sample에서의 speaker 식별 정확도를 비교해 보면,
- Fine-tuning 모델은 높은 speaker, accent accuracy를 보임
- 압축되지 않은 voice cloning 모델의 경우, 최고의 성능을 보이지 못함 - Pruning 이후 fine-tuning을 수행했을 때, 가장 높은 accuracy와 두 번째로 높은 압축률 (sparsity)를 달성
- 결과적으로 pruning 후 fine-tuning이 voice cloning을 위한 가장 안정적인 파이프라인
- Fine-tuning 모델은 높은 speaker, accent accuracy를 보임

- Other Pruning Advantages
- Pruned 모델은 추론 속도를 2배로 향상하고 GPU 사용량을 절반으로 줄일 수 있음
- Distillation과 비교했을 때, pruning은 scratch 학습이 필요하지 않으므로 학습 시간 단축이 가능
- 추가적으로 pruning은 pre-train 된 고품질 TTS 모델을 활용해 pruning process 전반에 걸쳐 품질 유지가 가능
반응형
'Paper > TTS' 카테고리의 다른 글
댓글