


 [Paper 리뷰] UniSyn: An End-to-End Unified Model for Text-to-Speech and Singing Voice Synthesis
[Paper 리뷰] UniSyn: An End-to-End Unified Model for Text-to-Speech and Singing Voice Synthesis
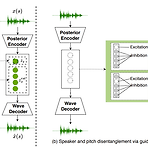
UniSyn: And End-to-End Unified Model for Text-to-Speech and Sining Voice Synthesis Text-to-Speech와 Singing Voice Synthesis를 단일 시스템으로 통합하는 기존의 방법들은, 동일한 화자로 제한되거나 cascaded model에 의존하는 한계가 있음 UniSyn 음성 합성과 가창 합성을 통합한 end-to-end 모델 Speaker와 style을 condition으로 사용하는 Multi-Conditional Variational AutoEncoder 구조 Timbre와 style의 disentangle을 위한 supervised guided-VAE와 Wasserstein distance 기반 timbre pertur..
 [Paper 리뷰] Diffusion-Based Generative Speech Source Separation
[Paper 리뷰] Diffusion-Based Generative Speech Source Separation
Diffusion-Based Generative Speech Source Separation Source separation을 위해 Stochastic Differential Equation을 활용할 수 있음 DiffSep 분리된 source에서 시작해 mixture를 중심으로 하는 Gaussian 분포로 수렴하는 continuous time diffusion-mixing proces를 활용 Diffusion-mixing process의 score function에 대한 marginal probability를 근사하는 neural network를 훈련 Neural network를 활용하여 mixture에서 source를 점진적으로 분리하는 reverse-time SDE를 solve 논문 (ICASSP 2..
 [Paper 리뷰] WaveGlow: A Flow-Based Generative Network for Speech Synthesis
[Paper 리뷰] WaveGlow: A Flow-Based Generative Network for Speech Synthesis
WaveGlow: A Flow-Based Generative Network for Speech Synthesis Flow-based network는 autoregression 없이 mel-spectrogram에서 고품질 음성을 합성할 수 있음 WaveGlow 고품질 음성 합성을 위해 Glow와 WaveNet의 아이디어를 활용 Training data의 likelihood를 최대화하여 training 단계를 간단하고 안정적으로 만듦 논문 (ICASSP 2019) : Paper Link 1. Introduction 효율적이고 고품질의 음성 합성에 대한 요구사항은 점차 증대되고 있음 음성 품질, latency에 대한 작은 변화도 customer experience와 preference에 큰 영향을 미치기 때문..
 [Paper 리뷰] Hybrid Transformers for Music Source Separation
[Paper 리뷰] Hybrid Transformers for Music Source Separation
Hybrid Transformers for Music Source Separation Music source separation에서 long range contextual information나 local acoustic feature는 유용하게 사용되는 정보임 Hybrid Transformer Demucs (HT Demucs) Hybrid Demucs 기반의 hybrid temporal/spectral bi-U-Net 구조 Innermost layer를 Transformer Encoder로 대체 하나의 domain에 대한 self-attention과 여러 domain 간의 cross-attention을 활용 논문 (ICASSP 2023) : Paper Link 1. Introduction Music S..
 [Paper 리뷰] Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search
[Paper 리뷰] Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search
Glow-TTS: A Generative Flow for Text-to-Speech via Monotonic Alignment Search Parallel text-to-speech 모델은 externel aligner의 guidance 없이 학습하기 어려움 Glow-TTS Externel aligner가 필요 없는 flow-based parallel text-to-speech 모델 Flow property와 dynamic programming을 결합한 monotonic alignment search의 도입 Hard monotonic alignment를 사용하면 robust한 생성이 가능하고 flow를 활용하면 빠르고 다양한 생성이 가능 논문 (NeurIPS 2020) : Paper Link 1. Int..