

티스토리 뷰
Paper/SVS
[Paper 리뷰] LiteSing: Towards Fast, Lightweight and Expressive Singing Voice Synthesis
feVeRin 2024. 1. 9. 16:51반응형
LiteSing: Towards Fast, Lightweight and Expressive Singing Voice Synthesis
- 경량화된 고품질의 Singing Voice Synthesis 시스템이 필요함
- LiteSing
- Generative Adversarial Network architecture 하에서 악보의 full condition을 예측하고, 해당 condition에서 acoustic feature를 생성
- Dynamic spectrogram energy, Voiced/Unvoiced decision, Dynamic pitch curve를 구성해 expressiveness를 향상
- Pitch와 timbre를 개별적으로 예측하여 두 feature의 interdependence를 회피
- 논문 (ICASSP 2021) : Paper Link
1. Introduction
- Singing Voice Synthesis (SVS)는 가사, rhythm, pitch 등의 악보 information으로부터 acoustic waveform을 합성하는 것을 목표로 함
- NPSS, Mellotron, DurlAN과 같은 autoregressive SVS 모델들이 등장함
- BUT, 느린 추론 속도로 인해 non-autoregressive Sequence-to-Sequence (Seq2Seq) 모델이 제안됨
- WGANSing의 경우, U-Net을 기반으로하는 adversarial sining synthesis를 활용함
- XiaoiceSing의 경우, self-attention과 1D convolution을 활용하는 FastSpeech를 활용 - FastSpeech에서 개선된 FastSpeech2를 활용하면, variance adaptor를 통해 one-to-many mapping 문제 해결이 가능함
-> 그래서 FastSpeech2를 활용하여 dynamic spectrogram energy, dynamic pitch curve와 같은 variance condition을 예측하고 추론 속도를 향상한 LiteSing을 제안
- LiteSing
- WaveNet을 non-autoregressive architecture로 수정해 추론 속도를 가속화하고 parameter 수를 줄임
- Encoder에서 pitch를 예측하고, Decoder에서 timbre feature를 출력함으로써 pitch 예측에 관계없이 모델은 timbre와 pronunciation을 학습
- Reference singing voice에서 추출된 full condition을 활용하여 더 expressive 한 합성이 가능 - WGAN framework를 통해 Mean Squared Error (MSE) 학습을 개선
< Overall of LiteSing >
- 악보의 full condition을 예측하여 expressive한 acoustic feature를 생성하는 non-autoregressive SVS 모델
- Generative Adversarial Network (GAN)를 활용한 lightweight architecture
- 결과적으로 추론 속도, 모델 size, expressiveness 측면에서 우수한 성능을 달성
2. Architecture
- LiteSing은 악보에서 phoneme, pitch 등의 basic element를 추출한 다음,
- Encoder와 condition predictor를 통해 dynamic spectrogram energy, pitch curve, Voice/Unvoice (V/UV) decision 등의 expressive full condition을 예측
- 이후 expressive full condition과 phoneme sequence는 concatenate되어 decoder를 통한 timbre 예측에 사용됨
- 최종적으로 LiteSing은 WORLD vocoder를 사용하여 가창 음성을 합성

- WaveNet
- LiteSing은 WaveNet을 architecture의 핵심 block으로써 사용함
- BUT, 일반적인 WaveNet은 autoregressive 하게 순차적으로 sample을 하나씩 생성하기 때문에 상당히 느림
- WaveNet의 추론 속도를 높이기 위해,
- Autoregressive WaveNet으로 학습된 분포하에서 output 확률을 일치시키는 non-autoregressive WaveNet을 학습시킴
- 이때, teacher-student training 파이프라인을 제거하고 local condition을 명시적으로 활용하여 모델을 단순화 - LiteSing에서 WaveNet은 end-to-end Seq2Seq module로써 사용됨
- 구조적으로는 residual connection, dilated convolution, gated convolution과 같은 기존의 WaveNet block들을 활용
- 대신 receptive field를 늘리기 위해 casual convolution을 dilated convolution으로 대체
- 추가적으로 condition에 대한 feature map을 생성하기 위해 gated convolution 앞에 $1 \times 1$ convolution을 사용 - 모든 layer의 output은 tanh activation과 $1 \times 1$ convolution 이전에 합산됨
- Encoder
- 악보는 note pitch, note duration, 가사 등의 basic element들로 구성됨
- LiteSing에서는 가사와 note duration으로부터 syllable sequence를 얻은 다음, 가창 음성 합성을 위해 각 syllable을 여러 개의 phoneme들로 decompose 함
- Single-phoneme syllable의 경우, single vowel phoneme 이전에 40ms의 auxiliary phoneme을 추가
- Multi-phoneme syllable의 경우, consonant와 vowel에 대한 2개의 부분으로 decompse - Phonetic pronunciation 품질을 향상하기 위해, sequence의 각 phoneme은 연관된 syllable과 concatenate됨
- 이때 phoneme sequence는 $M \in R^{N\times 2}$의 matrix
- $N$ : sequence length이자 acoustic feature의 총 frame 수와 같음 - 구조적으로 encoder는 악보의 condition에 대한 hidden layer representation을 생성하는 2-layer WaveNet으로 구성됨
- 추가적으로 original phoneme sequence와 note pitch를 유지함으로써, basic element에 대한 information loss를 완화
- LiteSing에서는 가사와 note duration으로부터 syllable sequence를 얻은 다음, 가창 음성 합성을 위해 각 syllable을 여러 개의 phoneme들로 decompose 함
- Condition Predictor
- 생성 모델에서 one-to-many mapping 문제는 동일한 phoneme sequence을 서로 다른 표현에 대응해야 하기 때문에 발생
- 이를 해결하는 효과적인 solution은 one-to-many를 many-to-many로 변환하는 더 많은 variance condition을 input으로 사용하는 것
- 따라서 LiteSing은 encoder의 hidden layer representation으로부터 dynamic energy, V/UV decision, pithc curve 등에 대한 full condition을 생성하는 condition predictor를 도입
- Expressive full condition은 reference 곡에서 추출되거나 더 높은 품질을 위해 수정될 수 있음 - 구조적으로 condition predictor는 1D convolution, ReLU activation, layer normalization, dropout으로 구성됨
- Condition predictor는 서로 다른 activation function을 가지는 3개의 linear layer를 사용하여 3가지의 서로 다른 condition을 생성 - Condition predictor를 최적화하기 위해 MSE를 활용:
$\mathcal{L}_{cp} = \mathcal{L}_{energy} + \mathcal{L}_{V/UV} + \mathcal{L}_{curve}$
- $ \mathcal{L}_{energy}$ : energy에 대한 loss
- $ \mathcal{L}_{V/UV}$ : V/UV decision에 대한 loss
- $ \mathcal{L}_{curve}$ : pitch curve에 대한 loss
- Energy와 V/UV decision은 $[0,1]$의 범위를 가지고, sigmoid activation이 사용됨
- Decoder
- Decoder는 4-layer WaveNet을 사용하여 full condition을 Mel-Generalized Cepstral (MGC)와 aperiodicity (BAP)을 포함하는 timbre feature sequence로 병렬 변환
- Timbre 변환 decoder의 장점
- Decoder에서 pitch 예측을 제거함으로써 timbre feature에 집중할 수 있음
- Training corpus가 광범위한 pitch를 다루지 않으므로, corpus size와 parameter 수를 줄일 수 있음
- Decoder에서 full condition을 수정함으로써 phonetic pronunciation과 emotional expression를 조절할 수 있음
- Phoneme sequence에 syllable information이 포함되어 있으므로 이전 phoneme, 다음 phoneme, normalized position은 제거됨
- 추가적으로 over-smoothing을 완화하기 위해 ground-truth와 예측값 사이의 MSE loss와 WGAN loss를 사용
- Timbre 변환 decoder의 장점
- Discriminator
- Acoustic feature 생성은 full condition하에서 2D image 생성 문제로 재구성할 수 있음
- 특히 GAN은 이러한 2D image 생성 문제에 효과적임
- WGAN은 생성된 분포와 실제 분포 사이의 Earth Mover distance에 대한 근사치를 최적화하는 방식을 사용
- WGAN의 도입을 통해 mode collapse, vanishing gradient 등의 문제를 해결할 수 있음 - WGAN architecture는 generator $G$와 discriminator $D$에 대한 2개의 network로 구성됨
- Target acoustic feature와 예측된 feature를 3D image representation $S \in R^{N \times M \times 2}$로 변환
- $N$ : frame 수, $M$ : acoustic feature의 차원 - 3개의 residual block으로 구성된 discriminator는 generator로 얻어진 합성 output과 실제 output을 판별하도록 학습되고, generator는 discriminator를 속이도록 학습됨
- 이때 generator의 loss function은:
$\mathcal{L}_{WGAN}(G) = -E[D(G(z)]$
$\mathcal{L}_{MSE}(G) = \frac{1}{N} \sum_{i=1}^{N} (G(z)-x)^{2}$
$\mathcal{L}(G) = w_{1} \times \mathcal{L}_{WGAN}(G) + w_{2} \times \mathcal{L}_{MSE} (G) + w_{3} \times \mathcal{L}_{cp}$
- $z$ : latent input, $x$ : target acoustic feature
- Target acoustic feature와 예측된 feature를 3D image representation $S \in R^{N \times M \times 2}$로 변환
- 특히 GAN은 이러한 2D image 생성 문제에 효과적임
3. Experiments
- Settings
- Dataset : Mandarin dataset
- Comparisons : FastSpeech2, NPSS
- Overall Performance
- Auto-regressive WaveNet을 활용하는 NPSS와 비교했을 때, LiteSing은 더 빠른 추론 속도와 합성 품질을 달성
- FastSpeech2와 비교했을 때, LiteSing은 모델 size와 추론 속도 측면에서 압도적임
- 합성 품질 측면에서도, 3.60과 3.63 MOS로 큰 차이를 보이지 않음

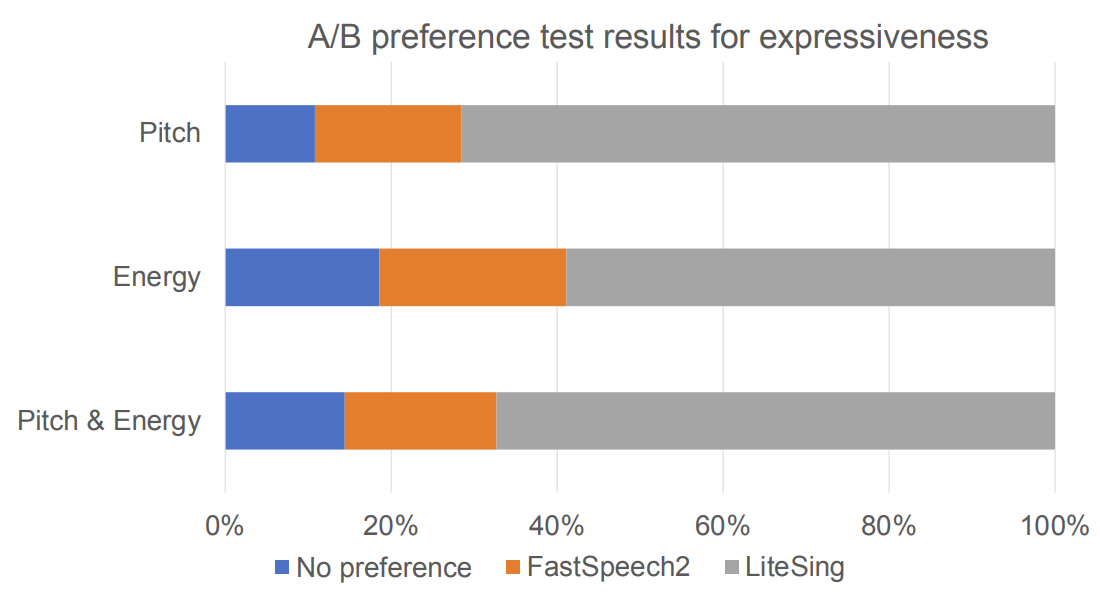
- 모델의 expressiveness를 검증하기 위해 A/B test를 수행했을 때,
- 67.3%가 LiteSing을 선호했음
반응형
'Paper > SVS' 카테고리의 다른 글
댓글