

티스토리 뷰
Paper/TTS
[Paper 리뷰] LiteTTS: A Lightweight Mel-spectrogram-free Text-to-wave Synthesizer Based on Generative Adversarial Networks
feVeRin 2024. 1. 8. 16:46반응형
LiteTTS: A Lightweight Mel-spectrogram-free Text-to-wave Synthesizer Based on Generative Adversarial Networks
- 빠른 속도로 고품질의 음성을 합성할 수 있는 lightweight end-to-end text-to-speech 모델이 필요
- LiteTTS
- Feature prediction module과 waveform generation module을 결합한 single framework
- Feature prediction module은 input text 및 prosodic information에 대한 latent space embedding을 추정
- Waveform generation module은 추정된 latent embedding을 condition으로 waveform을 합성
- Pre-trained model을 사용하지 않고 domain transfer technique을 사용하여 모델을 jointly train
- 논문 (INTERSPEECH 2021) : Paper Link
1. Introduction
- Text-to-Speech (TTS) 시스템의 품질은 지속적으로 향상되고 있음
- Tacotron2, Transformer TTS와 같은 autoregressive 모델
- 안정적인 합성이 가능하지만 추론 속도가 느림 - FastSpeech2 같은 non-autoregressive 모델
- 병렬 처리가 가능하기 때문에 빠른 추론이 가능함
- Tacotron2, Transformer TTS와 같은 autoregressive 모델
- 대부분의 TTS 모델은 two-stage 방식을 활용함
- (1) Feature predicton module이 input text로부터 Mel-spectrogram을 생성하고, (2) Waveform generation module이 Mel-spectrogram으로부터 vocoder를 통해 waveform을 합성
- 이러한 Two-stage 방식은 두 module 간의 error propagation 문제가 발생할 수 있음
- Mel-spectrogram 생성을 위한 decoder가 필요하기 때문에 network size가 커지는 문제도 있음
- 이때, network에서 Mel-spectrogram decoder를 제거할 수 있으면 모델 size를 상당히 줄일 수 있음
-> 그래서 intermediate speech representation인 Mel-spectrogram을 생성하지 않는 fully text-to-wave 모델인 LiteTTS를 제안
- LiteTTS
- Generative Adversarial Network (GAN) style의 waveform generation module을 활용하여 직접적으로 waveform을 합성
- Text에서 prosodic information을 추출하기 위한 domain transfer technique의 적용
- 작고 빠른 처리 속도를 가진 효율적인 architecture의 구현
< Overall of LiteTTS >
- 13.4M의 parameter 만을 필요로하는 작은 크기의 fully text-to-wave 모델
- Domain transfer를 활용해 음성 합성 과정에 prosodic information을 반영
- 결과적으로 3.84의 높은 MOS 달성과 Tacotron2 보다 5배 빠른 합성이 가능
2. Proposed Model
- LiteTTS는 prosody encoder $\mathbf{E}^{p}$, text encoder $\mathbf{E}^{t}$, domain transfer encoder $\mathbf{E}^{f}$, alignment module $\mathbf{A}$, duration predictor $\mathbf{P}$, waveform generator $\mathbf{G}$, discriminator block $\mathbf{D}$로 구성됨
- $m$ phoneme과 $n$-length reference Mel-spectrogram은 각각 $x=[x_{1}, x_{2}, ..., x_{m}]$, $\mathbf{Z} = [z_{1}, z_{2}, ..., z_{n}]$으로 표현되고, 모델의 input으로 사용됨
- Phonetic information은 text encoder를 통해 얻어지고, prosody information은 domain transfer encoder나 prosody encoder를 통해 얻어짐
- 해당 두 source는 Mel-spectrogram과 동일한 length로 확장되어 waveform generator를 통해 음성으로 합성됨
- Discriminator는 음성이 합성된 음성인지 실제 녹음된 음성인지를 판별
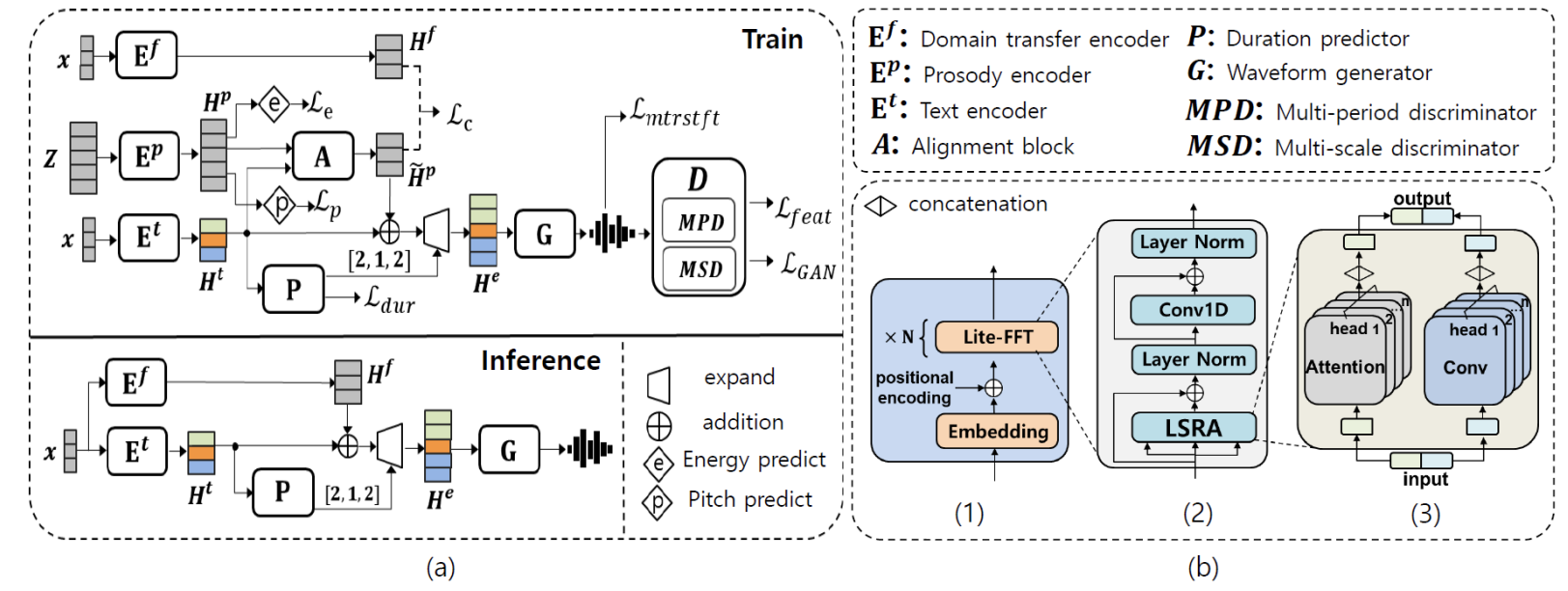
- Model Architecture
- Text Encoder $\mathbf{E}^{t}$
- Text encoder는 input $x$로부터 phonetic embedding $\mathbf{H}^{t} = \mathbf{E}^{t}(x)$를 생성
- $\mathbf{H}^{t} = [\mathbf{h}^{t}_{1}, \mathbf{h}^{t}_{2}, ..., \mathbf{h}^{t}_{m}]$ - Input $x$는 positional embedding을 추가하기 전에, learnable phonetic embedding lookup table을 사용하여 먼저 embedding 됨
- 이후 결합된 embedding은 여러 개의 lite Feed-Forward Transformer (lite-FFT) block을 통과하여 high-level phonetic embedding $\mathbf{H}^{t}$를 얻음 - lite-FFT는 기존 attention module을 대체하기 위해 Long-Short Range Attention (LSRA)를 채택
- LSRA는 input information을 병렬로 처리하는 두개의 branch를 활용함
- Attention branch는 convolution branch가 local information을 얻을 때, global knowlege를 수집하는 것을 목표로함
-> 결과적으로 LSRA를 통해 더 적은 수의 parameter를 사용하면서도 높은 성능을 달성
- Text encoder는 input $x$로부터 phonetic embedding $\mathbf{H}^{t} = \mathbf{E}^{t}(x)$를 생성
- Prosody Encoder $\mathbf{E}^{p}$
- TTS 모델에서 음성의 data 분포를 효과적으로 모델링하기 위해서는 prosody가 필수적임
- FastSpeech2의 경우, predictor network를 사용하여 energy, pitch에 대한 prosodic knowledge를 모델에 제공했음
- BUT, 각 prosodic factor 별로 predictor network를 사용하는 것은 최적의 선택이 아님
- 특히 neural network의 경우 over-parameterize 되기 쉽기 때문에 전체 성능을 손상시키지 않으면서 전체의 3/4를 제거 가능
-> 따라서, single network는 하나 이상의 특정 task를 수행할 수 있음 - 앞선 insight를 기반으로, input acoustic feature에서 여러개의 prosodic feature를 추출하는 single network를 설계
- Prosody encoder는 acoustic feature $\mathbf{Z}$를 input으로하여 prosody embedding $\mathbf{H}^{p} = [\mathbf{h}^{p}_{1}, \mathbf{h}^{p}_{2}, ..., \mathbf{h}^{p}_{n}]$을 출력 - Single prosody network $\mathbf{E}^{p}$는 여러 prosodic factor를 함께 제공할 수 있도록 구성됨
- Embedding $\mathbf{H}^{p}$ 다음에 pitch/energy prediction을 수행하여 prosody embeding $\mathbf{H}^{p}$에 두 information이 반영되도록 함
- 이때 pitch/energy prediction loss는:
$\mathcal{L}_{p} = \frac{1}{n} \sum_{i=1}^{n} || p_{i} - \bar{p}_{i} ||_{1}$
$\mathcal{L}_{e} = \frac{1}{n} \sum_{i=1}^{n} || e_{i} - \bar{e}_{i} ||_{1}$
- $p, e$ : 각각 ground-truth pitch/energy, $\bar{p}, \bar{e}$ : 예측된 pitch/energy
- Alignment Block $\mathbf{A}$
- Alignment block $\mathbf{A}$는 $n$-length frame-level prosody embedding $\mathbf{H}^{p}$를 $m$-length phoneme-level prosody representation $\tilde{\mathbf{H}}^{p}$로 변환
- $\tilde{\mathbf{H}}^{p} = \mathbf{A}(\mathbf{H}^{p})$ - 학습 단계에서, prosody embedding $\tilde{\mathbf{H}}^{p}$는 phonetic embedding과 결합되어 $\mathbf{H}^{c} = \mathbf{H}^{t} + \tilde{\mathbf{H}}^{p}$를 생성
- 이때, $\mathbf{H}^{c}$는 input utterance의 phoneme과 prosody information을 모두 전달
- Alignment block $\mathbf{A}$는 $n$-length frame-level prosody embedding $\mathbf{H}^{p}$를 $m$-length phoneme-level prosody representation $\tilde{\mathbf{H}}^{p}$로 변환
- Duration Predictor $\mathbf{P}$
- Duration predictor는 각 phoneme에 해당하는 Mel-spectrogram frame 수인 duration을 예측하는데 사용됨
- Text embedding $\mathbf{H}^{t}$가 주어지면, vector $\bar{\mathbf{d}} = [\bar{d}_{1}, \bar{d}_{2}, ..., \bar{d}_{m}]$는, $\bar{\mathbf{d}} = \mathbf{P}(\mathbf{H}^{t})$로써 $m$개의 input phoneme에 대한 예측 duration을 나타냄
- 이때, $\sum_{i=1}^{m} \bar{d}_{i} = n$ - Duration predictor에 대한 loss function은:
$\mathcal{L}_{dur} = \frac{1}{m} \sum_{i=1}^{m} || d_{i} - \bar{d}_{i} ||_{1}$
- $d$ : ground-truth duration - 이후, embedding $\mathbf{H}^{c}$는 duration $\bar{\mathbf{d}}$에 따라 확장됨
- (i.g.) $\mathbf{H}^{c}$의 $i$-th frame은 $d_{i}$번 반복되어 stack됨
- 결과적으로 $\mathbf{H}^{c}$에 대한 확장으로 $\mathbf{H}^{e} = [\mathbf{h}^{e}_{1}, \mathbf{h}^{e}_{2}, ..., \mathbf{h}^{e}_{n}]$를 얻음
- 그리고 나서 embedding $\mathbf{H}^{e}$는 waveform generator $\mathbf{G}$로 가기 전에 projection layer를 통과함
- Domain Transfer Encoder $\mathbf{E}^{f}$
- Input phoneme sequence $x$를 사용하여 $m$-length embedding을 생성함 $\mathbf{H}^{f} = \mathbf{E}^{f}(x)$
- Embedding $\mathbf{H}^{f}$와 embedding $\tilde{\mathbf{H}}^{p}$이 서로 가까워지도록 하는 loss function $\mathcal{L}_{c}$를 사용하여, 동일한 prosody domain에 대한 knowledge를 share하도록 함
- 이때 $\mathcal{L}_{c}$로써 pair-wise ranking loss, cosine similarity 등 보다 단순히 L1 loss를 사용하는 것이 더 효과적임 - 학습이 진행됨에 따라, loss function $\mathcal{L}_{c}$로 인해 $\tilde{\mathbf{H}}^{p}$에서 형성되는 prosody information이 $\mathbf{H}^{f}$로 전달됨
- 추론 과정에서 domain transfer block은 의미있는 pitch와 energy information을 가지는 $\mathbf{H}^{f}$를 추출해야함
- 이후, $\mathbf{H}^{f}$는 $\tilde{\mathbf{H}}^{p}$ 대체하여 phonetic embedding $\mathbf{H}^{t}$에 직접 제공됨
- Waveform Generator $\mathbf{G}$ and Discriminator $\mathbf{D}$
- 일반적으로 intermediate speech representation인 Mel-spectrogram을 생성하기 위해 encoder 다음에 decoder를 필요로함
- BUT, LiteTTS는 lightweight 모델을 설계하기 위해 Mel-spectrogram을 사용하지 않음 - 학습 과정에서 waveform generator $\mathbf{G}$의 input으로 hidden embedding $\mathbf{H}^{e}$의 fixed-length segment가 사용되고, 이후 generator $\mathbf{G}$는 input을 upsampling하여 raw waveform을 생성
- Discriminator $\mathbf{D}$는 input이 합성된 것인지 실제 recoding된 reference인지를 판별
- 일반적으로 intermediate speech representation인 Mel-spectrogram을 생성하기 위해 encoder 다음에 decoder를 필요로함

- Training Losses
- HiFi-GAN의 generator-discriminator architecture를 채택
- Discriminator block $\mathbf{D}$는 2개의 sub-module, Multi-Period Discriminator (MPD)와 Multi-Scale Discriminator (MSD)로 구성
- 각 sub-module은 각각 서로 다른 period와 scale로 audio input을 처리하는 여러개의 sub-discriminator로 구성됨 - Waveform generation과 Discriminator 학습은 LSGAN의 objective function을 사용:
$\mathcal{L}_{GAN} (D;G) = \mathbb{E}_{v,s} [ \sum_{k=1}^{K} (D_{k}(v)-1)^{2} + (D_{k} (G(s)))^{2}]$
$\mathcal{L}_{GAN} (G;D) = \mathbb{E}_{s} [\sum_{k=1}^{K} (D_{k}(G(s))-1)^{2}]$
- $v$ : 서로 다른 periodicity, scale의 ground-truth waveform
- $s$ : $\mathbf{H}^{e}$와 동일, $K$ : sub-discriminator의 총 개수
- $D_{k}$ : MPD/MSD의 sub-discriminator - Generator에는 추가적으로 feature matching loss가 적용됨:
$\mathcal{L}_{feat}(G;D) = \mathbb{E}_{x,s} [ \sum_{k=1}^{K} \sum_{i=1}^{T} \frac{1}{N_{i}} || D_{k}^{i} (x) - D_{k}^{i} (G(s)) ||_{1} ]$
- $T$ : sub-discriminator $D_{k}$의 layer 수
- $N_{i}$ : $i$-th layer의 전체 feature 수
- $D^{i}$ : 해당 layer의 feature - 추가적으로 안정성 향상을 위한 auxiliary loss로써, multi-resolution STFT loss $\mathcal{L}_{mrstft}$를 사용
- 다양한 frame size, hop size, FFT size에서 생성된 STFT와 ground-truth waveform 간의 차이를 capture - 따라서, 최종 loss는:
$\mathcal{L}_{G} = \mathcal{L}_{GAN} (D;G) + \lambda_{f} \mathcal{L}_{feat}(G;D) + \mathcal{L}_{dur} + \lambda_{m} \mathcal{L}_{mrstft} + \mathcal{L}_{p} + \mathcal{L}_{e} + \lambda_{c} \mathcal{L}_{c}$
$ \mathcal{L}_{D} = \mathcal{L}_{GAN}(G;D)$
- $\lambda_{f}, \lambda_{m}, \lambda_{c}$는 각각 2, 30, 5
- Discriminator block $\mathbf{D}$는 2개의 sub-module, Multi-Period Discriminator (MPD)와 Multi-Scale Discriminator (MSD)로 구성
3. Experiments
- Settings
- Datasets : LJSpeech
- Comparisons : FastSpeech2, Tacotron2
- Results
- Evaluation
- LiteTTS는 FastSpeech2, Tacotron2의 절반도 되지 않는 13.4M의 parameter만 필요로 함
- Real-Time Factor (RTF) 측면에서 LiteTTS는 Tacotron2 보다 5배, FastSpeech2 보다 1.6배 빠르게 audio 합성이 가능
- 추론 단계에서 phonetic embedding $\mathbf{H}^{t}$와 transferred prosody $\mathbf{H}^{f}$가 병렬로 계산되기 때문 - Multiplay-Accumulate Operations (MACs) 측면에서 LiteTTS는 27.0GMACs만을 사용하여 Tacotron2, FastSpeech2 보다 연산 비용이 낮음
- 음성 품질 측면에서도 LiteTTS는 3.84 MOS로 FastSpeech2 보다 높은 값을 보임
- Autogregressive 모델인 Tacotron2 보다는 MOS가 다소 낮았지만 통계적으로 유의하지는 않음

- Ablation Inference
- LiteTTS는 추론 시 phonetic embedding $\mathbf{H}^{t}$와 prosody embedding $\mathbf{H}^{f}$를 사용함
- (a) $\mathbf{H}^{t}$만 사용하는 경우
: Pitch, energy contour가 flat 하게 나타남 (prosody information이 없기 때문) - (b)$\mathbf{H}^{f}$만 사용하는 경우
: 다양한 prosody가 나타남 - (c) $\mathbf{H}^{t}, \mathbf{H}^{f}$ 모두 사용하는 경우
: (b)와 비슷하게 다양한 prosody를 가짐
- (a) $\mathbf{H}^{t}$만 사용하는 경우
- Automatic Speech Recognition (ASR)로 합성된 음성을 평가해 보면,
- (a)와 (c)의 PER이 (b) 보다 상당히 낮음
- (b)는 phonetic information을 사용하지 않기 때문
- LiteTTS는 추론 시 phonetic embedding $\mathbf{H}^{t}$와 prosody embedding $\mathbf{H}^{f}$를 사용함


반응형
'Paper > TTS' 카테고리의 다른 글
댓글