

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] LightVoc: An Upsampling-Free GAN Vocoder based on Conformer and Inverse Short-Time Fourier Transform
feVeRin 2024. 3. 13. 09:41반응형
LightVoc: An Upsampling-Free GAN Vocoder based on Conformer and Inverse Short-Time Fourier Transform
- Generative Adversarial Network (GAN) 기반의 기존 vocoder는 mel-spectrogram으로부터 audio를 생성하기 위해 iterative upsampling을 필요로 함
- Iterative upsampling은 network 복잡도를 증가시키므로 vocoder의 추론 속도를 저하시키는 주요 원인 - LightVoc
- Upsampling block을 Conformer block으로 대체하는 GAN-based vocoder
- 새로운 discriminator 조합을 도입하여 full-band에 걸쳐 high-resolution waveform을 생성
- 논문 (INTERSPEECH 2023) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 input text sequence를 acoustic sequence로 mapping 하는 acoustic model과 해당 acoustic sequence로부터 raw waveform을 합성하는 neural vocoder로 구성됨
- 이때 neural vocoder는 크게 autoregressive (AR), non-autoregressive (non-AR) 두 가지로 분류될 수 있음
- AR 방식은 우수한 합성 품질을 보이지만 상당히 느린 추론 속도를 가짐
- Non-AR 방식은 ligthweight 하면서도 고품질의 audio를 합성할 수 있다는 장점이 있음 - Non-AR 방식 중에서도 Generative Adversarial Network (GAN) 기반의 vocoder가 상당히 우수한 성능을 보임
- 일반적으로 GAN-based vocoder는 generator와 discriminator 두 가지로 구성됨
- Generator는 mel-spectrogram에서 audio를 합성하고, discriminator는 합성된 audio를 evaluate 하는 역할 - 특히 generator는 output sequence가 target waveform의 temporal resolution과 match 될 때까지 input sequence를 upsampling 하기 위해 convolution-based block을 사용함
- 이러한 iterative upsampling은 network의 복잡도를 증가시키고 결과적으로 추론 속도를 느리게 만듦
- 이를 해결하기 위해 iSTFTNet은 inverse Short-Time Fourier Transform (iSTFT)로 upsampling layer를 대체하는 방법을 도입함
- 일반적으로 GAN-based vocoder는 generator와 discriminator 두 가지로 구성됨
- Iterative upsampling 문제 외에도, GAN-based vocoder는 receptive field를 증가시키기 위해 dilated convolution에 상당히 의존적임
- 대표적으로 HiFi-GAN의 Multi-Receptive field Fusion (MRF) module은 다양한 dilation rate와 kernel size 조합을 가지는 CNN으로 구성됨
- BUT, CNN은 fine-grained local information을 추출하는 데는 적합하지만, pitch/energy와 같은 long-term dependency를 capture 하는데는 어려움이 있음 - 그에 비해 self-attention을 활용하는 Transformer는 long-term dependency를 capture하는데 장점이 있음
- 따라서 convolution과 self-attention을 결합한 Conformer를 활용하면 local/global dependency를 모두 반영할 수 있음
- 대표적으로 HiFi-GAN의 Multi-Receptive field Fusion (MRF) module은 다양한 dilation rate와 kernel size 조합을 가지는 CNN으로 구성됨
- 이때 neural vocoder는 크게 autoregressive (AR), non-autoregressive (non-AR) 두 가지로 분류될 수 있음
-> 그래서 Conformer와 iSTFT를 기반으로 한 upsampling-free GAN vocoder인 LightVoc를 제안
- LightVoc
- Generator를 lightweight 하고 빠르게 만들기 위해, iSTFTNet의 모든 upsampling block을 Conformer block으로 대체
- Full-band에 걸쳐 high-resolution waveform을 생성하는 discriminator 조합을 제시
< Overall of LightVoc >
- Upsampling block을 Conformer block으로 대체하는 GAN-based vocoder
- 새로운 discriminator 조합을 도입하여 full-band에 걸쳐 high-resolution waveform을 생성
- 결과적으로 고품질의 합성을 유지하면서 추론 속도를 크게 향상
2. Method
- LightVoc는 GAN architecture를 기반으로 mel-spectrogram에서 audio를 합성하는 generator와 합성된 audio를 evaluate 하는 discriminator로 구성됨
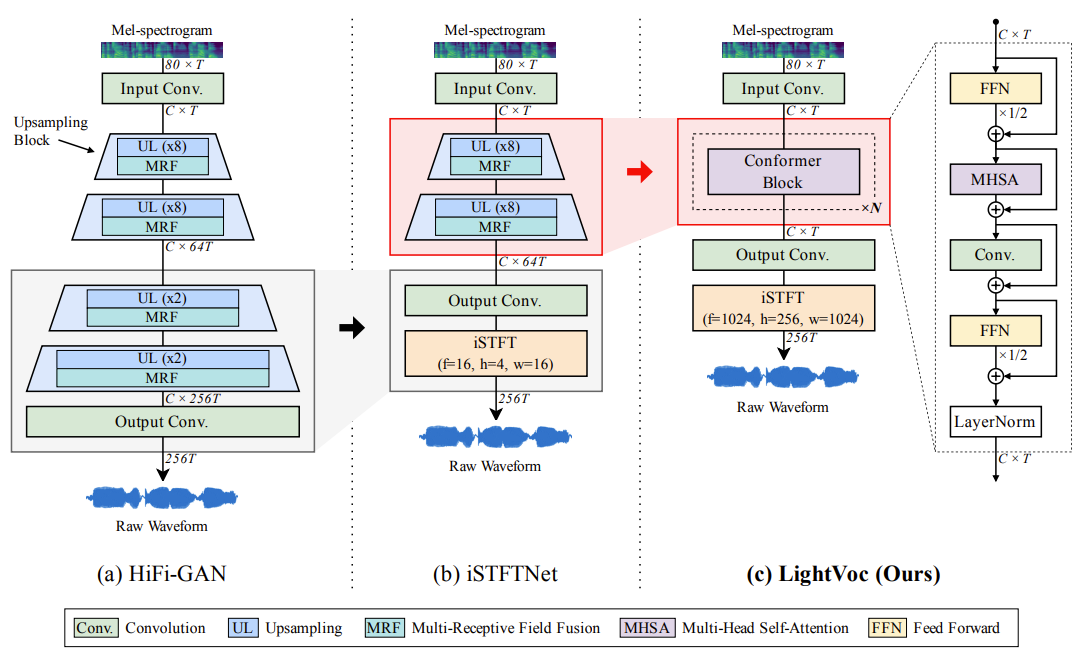
- Generator
- LightVoc의 generator는
- iSTFTNet을 기반으로 모델의 복잡도를 줄이고 long-term dependency를 반영하기 위해, 모든 upsampling block을 Conformer block으로 대체함
- 이때 data pipeline은
- Stage 1
- Full-band log-mel spectrogram이 두 convolution layer 사이의 $N$개 Conformer block stack에 전달됨
- 이때 Conformer의 output은 magnitude와 phase information - Stage 2
- 이후 iSTFT layer는 magnitude, phase information을 사용하여 raw waveform을 합성
- 이때 iSTFT layer의 size, hop length, window length는 mel-spectrogram 추출을 위해 사용된 Stage 1의 STFT layer와 동일함
- Stage 1
- 해당 pipeline에서 각 Conformer block은 Feed-Forward (FFN) module, Multi-Head Self-Attention (MHSA) module, Convolution (Conv) module, Normalization layer (LayerNorm)이 있는 FFN으로 구성됨
- MHSA와 Conv module을 통해 Conformer는 input sequence에서 local/global context feature를 모두 추출
- 추가적으로 skip connection을 통해 Conformer의 gradient vanishing을 방지

- Discriminator
- LightVoc의 discriminator는
- Collaborative Multi-Band Discriminator (CoMBD), Sub-Band Discriminator (SBD), Multi-Resolution Spectrogram Discriminator (MRSD)를 조합하여 구성됨
- Avocodo에서 제안된 CoMBD와 SBD는 low-frequency band에 bias 된 training objective와 naive downsampling으로 발생하는 aliasing과 artifact를 제거하는 역할을 수행
- BUT, CoMBD와 SBD 만을 사용하면 아래 그림과 같이 high-frequency band에서 over-smoothing이 발생함
- 따라서 MRSD를 추가적으로 도입하여 over-smoothing 문제를 해결하고 합성 품질을 향상 - 결과적으로 LightVoc는 CoMBD, SBD, MRSD를 사용하여 full-band에 걸쳐 high-resolution waveform을 생성함

3. Experiments
- Settings
- Dataset : LJSpeech
- Comparisons : Parallel WaveGAN, Multi-Band MelGAN, HiFi-GAN, iSTFTNet
- Results
- Impact of Audio Length on GPU-based Synthesizing Speed
- 90초 보다 짧은 audio file을 합성할 때 LightVoc는 iSTFTNet을 제외한 다른 모델들보다 빠른 속도를 보임
- LightVoc는 Conformer block의 quadratic 계산 복잡성으로 인해 audio file이 30초 이상 길어지면 속도 저하가 발생함
- Self-attention 기반의 vocoder 구현에는 속도 향상에 분명한 한계가 있음을 의미

- Comparison with Prior Works on Multiple Metrics
- 정량적, 정성적 지표 측면에서 성능을 비교해 보면 LightVoc의 MOS, RTF가 가장 뛰어난 것으로 나타남
- 특히 LightVoc는 HiFi-GAN, iSTFTNet의 1/3 수준의 parameter 만으로도 우수한 성능을 달성할 수 있음

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글