

티스토리 뷰
Paper/Vocoder
[Paper 리뷰] SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis
feVeRin 2024. 3. 15. 09:48반응형
SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis
- Generative Adversarial Network는 빠른 합성을 보장하면서 고품질의 음성을 생성할 수 있음
- SpecDiff-GAN
- Discriminator 이전에 Gaussian noise를 real/fake sample 모두에 inject 하는 forward diffusion process를 통해 training stability를 향상
- Discriminator task를 더 어렵게 만드는 spectrally-shaped noise 분포를 도입
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Audio 합성은 주어진 acoustic feature를 기반으로 natural-sounding audio signal을 합성하는 것을 목표로 함
- 일반적으로 사용되는 autoregressive 모델은 sequential한 특성으로 인해 추론 시간이 느리다는 단점이 있음
- Flow-based 모델은 complex invertible 변환을 수행해야 하므로 parameter-inefficient 함
- Generative Adversarial Network (GAN)은 빠르고 계산 효율적이면서 고품질의 합성이 가능함
- BUT, training이 어렵고 mode collapse와 같은 문제를 겪을 수 있음 - 한편으로 GAN의 단점은 Denoising Diffusion Probabilistic Model (DDPM)의 도입으로 해결할 수 있음
- BUT, reverse process를 수행하기 위해서는 많은 step 수를 필요로 함
-> 그래서 audio 합성에서 GAN의 stability 문제와 DDPM의 추론 속도 문제를 해결하는 SpecDiff-GAN을 제안
- SpecDiff-GAN
- HiFi-GAN을 기반으로 noise-shaping diffusion process를 적용
- Training stability를 위해 discriminator의 input (real/fake)에 instance noise를 inject - Discriminator task를 어렵게 하는 spectrally-shaped noise 분포를 활용
- Mel-spectrogram input의 spectral envelope를 기반으로 한 inverse filter를 사용하여 여러 noise 분포를 비교
- HiFi-GAN을 기반으로 noise-shaping diffusion process를 적용
< Overall of SpecDiff-GAN >
- Gaussian noise를 real/fake sample 모두에 inject 하는 forward diffusion process를 적용하여 training stability를 향상
- Spectrally-shaped noise 분포를 활용하여 discriminator task를 개선
- 결과적으로 우수한 합성 품질과 빠른 추론 속도를 달성함
2. Method
- Architecture
- Generator는 HiFi-GAN의 architecture를 활용함
- 이때 periodic pattern을 효과적으로 capture 하기 위해 period $p$로 parameterize 된 여러 개의 sub-discriminator로 구성되는 Multi-Period Discriminator (MPD)를 도입
- 한편으로 Multi-Scale Discriminator (MSD) 대신 UnivNet의 Multi-Resolution Discriminator (MRD)를 사용함
- MRD를 사용하면 sample 품질이 더욱 향상되고 artifact를 줄일 수 있음 - 이러한 temporal/spectral resolution discriminator를 통해 full-band에 걸쳐 high-resolution signal을 생성할 수 있음

- Enhancing the GAN Model with Diffusion
- GAN training에 diffusion process를 적용하여 discriminator가 original/generated data의 perturbed version을 distinguish 하는 방법을 학습하도록 함
- Forward diffusion process 동안 $x_{0}\sim q(x_{0})$로 denote 되는 initial sample은 Gaussian noise에 의해 점진적으로 perturb 되는 $T$ sequential step을 거침
- Noise schedule을 $\{ \beta \}_{t=1}^{T}$라 하면, 위 과정은 $q(x_{1:T}|x_{0})=\prod_{t\geq 1}q(x_{t}|x_{t-1})$로 formalize 할 수 있음
- 이때 $q(x_{t}|x_{t-1})=\mathcal{N}(x_{t};\sqrt{1-\beta_{t}}x_{t-1},\beta_{t}I)$ - $\alpha_{t}=1-\beta_{t}, \bar{\alpha}_{t}=\prod_{u=1}^{t}\alpha_{u}$라고 하면, forward process에서 $x_{t}$는 arbitrary time step $t$에서 $x_{t}=\sqrt{\bar{\alpha}_{t}}x_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon$에 의해 closed form으로 sampling 됨
- $\epsilon \sim \mathcal{N}(0,\Sigma)$
- Noise schedule을 $\{ \beta \}_{t=1}^{T}$라 하면, 위 과정은 $q(x_{1:T}|x_{0})=\prod_{t\geq 1}q(x_{t}|x_{t-1})$로 formalize 할 수 있음
- $x\sim p(x)$는 ground-truth audio이고 $s$는 generator의 input condition (mel-spectrogram)이라고 하면, $G(s)$는 generated signal로 나타낼 수 있음
- 이때 perturbed sample은 다음과 같이 얻어짐:
(Eq. 1) $y \sim q(y|x,t), \,\, y=\sqrt{\bar{\alpha}_{t}}x+\sqrt{1-\bar{\alpha}_{t}}\epsilon$
(Eq. 2) $y_{g}\sim q(y_{g}|G(s),t),\,\, y_{g}=\sqrt{\bar{\alpha}_{t}}G(s)+\sqrt{1-\bar{\alpha}_{t}}\epsilon'$
- $\epsilon, \epsilon' \sim \mathcal{N}(0,\Sigma)$
- $q(y|x,t)$ : target data $x$와 diffusion step $t$가 주어졌을 때 noisy sample $y$의 conditional 분포
- $q(y_{g}|G(s),t)$ : generated signal $G(s)$와 diffusion step $t$가 주어졌을 때 noisy sample $y_{g}$의 conditional 분포
- Forward diffusion process 동안 $x_{0}\sim q(x_{0})$로 denote 되는 initial sample은 Gaussian noise에 의해 점진적으로 perturb 되는 $T$ sequential step을 거침
- Noise Distribution
- $\Sigma$에 대한 2가지 option을 고려할 수 있음
- $\Sigma_{standard}=\sigma^{2}I$로 설정한 경우 : StandardDiff-GAN
- $\sigma$ : scalar, $I$ : identity matrix - SpecGrad와 같이 spectral envelope를 기반으로 noise를 설정한 경우 : SpecDiff-GAN
- 이때 filter $\mathbf{M}_{spec}$은 SpecGrad에서 사용된 filter의 inverse임 ($\mathbf{M}_{spec}=\mathbf{M}_{SG}^{-1}$)
- 이는 low-energy region에서 increased noise incorporation을 강조하는 noise 분포를 생성하므로 discriminator task를 어렵게 만들 수 있음 - 여기서 SpecDiff-GAN의 noise 분포 분산은 $\Sigma_{spec} = \mathbf{L}_{spec}\mathbf{L}_{spec}^{T}$로 설정
- $\mathbf{L}_{spec} = \mathbf{G} \mathbf{M}_{spec} \mathbf{G}^{+}$
- $\mathbf{G}, \mathbf{G}^{+}$ : STFT와 그 inverse에 대한 matrix representation
- 이때 filter $\mathbf{M}_{spec}$은 SpecGrad에서 사용된 filter의 inverse임 ($\mathbf{M}_{spec}=\mathbf{M}_{SG}^{-1}$)
- $\Sigma_{standard}=\sigma^{2}I$로 설정한 경우 : StandardDiff-GAN
- Adaptive Diffusion
- Interval $[T_{\min},T_{\max}]$ 내에서 $T$로 denote 되는 최대 diffusion step 수에 대한 adaptive update mechanism을 사용하여 training 중에 discriminator의 difficulty를 dynamically regulate
- 이러한 adaptive adjustment를 통해 discriminator가 real/fake sample을 distinguish 하는 방법을 학습할 때 다양한 어려움을 겪을 수 있도록 보장함
- Discriminator가 학습에 어려움을 겪으면 $T$를 줄여 non-perturbed sample 같은 단순한 sample에서 학습하도록 하고,
- Discriminator가 너무 쉽게 distinguish 하면 $T$를 늘려 sample에 더 많은 complexity를 부여함 - 이때 training data에 대한 discriminator의 overfitting 정도를 정량화하기 위해
- $B$ consecutive minibatch에서 계산되는 아래의 metric을 도입:
(Eq. 3) $r_{d}=\mathbb{E}[\mathrm{sign}(D_{train}-0.5)]$
- $D_{train}$ : training set sample에 대한 discriminator output
- $\mathbb{E}[\cdot]$ : $B$ minibatch의 평균
- $r_{d}$가 1에 가까우면 overfitting을 의미하고, 0에 가까우면 overfitting이 없음을 의미 - 이에 따라 다음과 같이 $B=4$ minibatch 마다 $T$를 update 함:
(Eq. 4) $T\leftarrow T +\mathrm{sign}(r_{d}-d_{target})\cdot C$
- $d_{target}$ : $r_{d}$에 대해 desired value를 나타내는 hyperparameter
- $C$ : $T$가 $T_{\min}$에서 $T_{\max}$로 transition 되는 rate를 regulate 하는 constant - 이후 diffusion timestep $t\leq T$는 $c_{T}=\sum_{u=1}^{T}u$로 정의된 discrete 분포 $p_{\pi}$에서 다음과 같이 도출됨:
(Eq. 5) $t\sim p_{\pi}:=\mathrm{Discrete}(1/c_{T},2/c_{T},...,T/c_{T})$
- 해당 분포는 큰 $t$ 값에 더 많은 weight를 부여하여 training 중 diffusion step 선택에 영향을 미침
- $B$ consecutive minibatch에서 계산되는 아래의 metric을 도입:
- 이러한 adaptive adjustment를 통해 discriminator가 real/fake sample을 distinguish 하는 방법을 학습할 때 다양한 어려움을 겪을 수 있도록 보장함
- Training Losses
- SpecDiff-GAN의 training loss는
- Simplicity를 위해 두 discriminator를 $D$라고 하면, discriminative loss는:
(Eq. 6) $\mathcal{L}_{D}=\mathbb{E}_{(x,s,t,y,y_{g})}[(D(y)-1)^{2}+(D(y_{g}))^{2}]$
- $y, y_{g}$ : (Eq. 1), (Eq. 2) - Generator loss는 adversarial loss와 feature matching (FM) loss, mel-spectrogram loss를 사용하여 formulate 됨:
(Eq. 7) $\mathcal{L}_{G}=\mathbb{E}_{(s,t,y_{g})}[(D(y_g)-1)^{2}]+\lambda_{FM}\mathbb{E}_{(x,s,t,y,y_{g})}\left[ \sum_{i=1}^{L}\frac{1}{N_{i}}|| D^{i}(y)-D^{i}(y_{g})||_{1} \right]$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, +\lambda_{mel}\mathbb{E}_{(x,s)}[|| \phi(x)-\phi(G(s)) ||_{1}]$
- $\lambda_{FM}, \lambda_{mel}$ : scalar coefficient, $\phi$ : mel-spectrogram transform function
- $L$ : layer 수, $D^{i}$ : discriminator $i$-th layer의 feature, $N_{i}$ : 해당 feature의 수
- Simplicity를 위해 두 discriminator를 $D$라고 하면, discriminative loss는:
3. Experiments
- Settings
- Results
- Inference Results for the Different Datasets
- LJSpeech dataset에서의 결과를 확인해 보면, SpecDiff-GAN은 기존 모델들과 비교하여 가장 우수한 성능을 보임
- 특히 SpecDiff-GAN은 noise shaping으로 인해 $\Sigma_{standard}$를 사용하는 StandardDiff-GAN 보다 더 뛰어남

- VCTK에서의 합성 결과를 비교해 보면, SpecDiff-GAN은 BigVGAN과 비교할만한 성능을 보임
- 특히 baseline인 HiFi-GAN, UnivNet과 비교하여 SpecDiff-GAN, StandardDiff-GAN은 상당한 성능 차이를 보임

- MAPS, ENST-Drums에서의 결과를 비교해 보면,
- MAPS에서도 마찬가지로 SpecDiff-GAN이 좋은 성능을 보임
- ENST-Drums의 경우, StandardDiff-GAN이 우수한 성능을 보였는데, 이는 작은 dataset size와 동일한 드럼 연주의 영향 때문

- Ablation Study
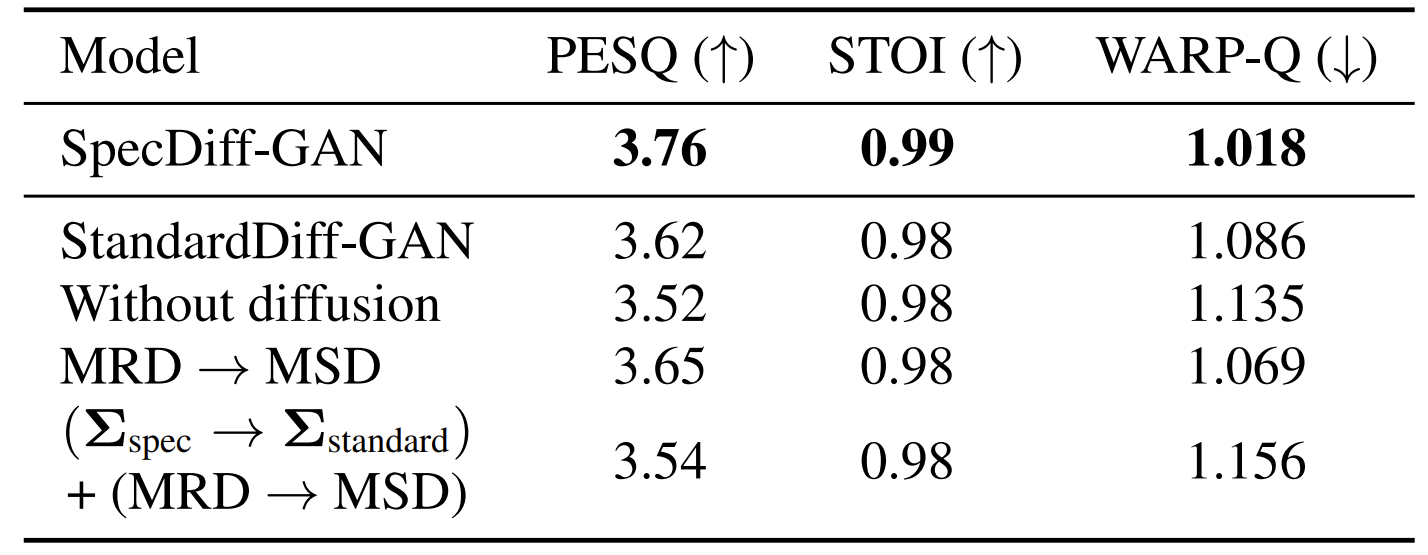
- MRD, diffusion process, reshaped noise 분포에 대한 ablation study를 수행해 보면
- Spectrally-shaped noise 분포를 제거하고 $\Sigma_{standard}$를 채택하는 경우 성능이 저하됨
- 마찬가지로 MRD를 대체하거나 diffusion process를 배제하는 경우에도 성능 저하가 발생
- Model Complexity
- BigVGAN과 비교하여 SpecDiff-GAN은 대략 200k 더 적은 parameter 수를 가지고 더 빠른 합성 속도를 보임
- BigVGAN의 추론 속도 저하는 snake activation function의 존재 때문

반응형
'Paper > Vocoder' 카테고리의 다른 글
댓글