

 [Paper 리뷰] DETS: End-to-End Single-Stage Text-to-Speech via Hierarchical Diffusion GAN Models
[Paper 리뷰] DETS: End-to-End Single-Stage Text-to-Speech via Hierarchical Diffusion GAN Models
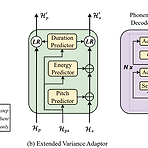
DETS: End-to-End Single-Stage Text-to-Speech via Hierarchical Diffusion GAN ModelsEnd-to-End text-to-speech는 여전히 naturalness와 prosody diversity 측면에서 한계가 있음DETSHierarchical denoising diffusion GAN을 도입한 end-to-end frameworkDenoising distribution을 모델링하기 위해 non-Gaussian multi-modal function을 채택하여 다양한 pitch와 rhythm을 반영할 수 있는 one-to-many relationship을 학습논문 (ICASSP 2024) : Paper Link1. IntroductionText..
 [Paper 리뷰] StyleSpeech: Self-Supervised Style Enhancing with VQ-VAE-based Pre-training for Expressive Audiobook Speech Synthesis
[Paper 리뷰] StyleSpeech: Self-Supervised Style Enhancing with VQ-VAE-based Pre-training for Expressive Audiobook Speech Synthesis
StyleSpeech: Self-Supervised Style Enhancing with VQ-VAE-based Pre-training for Expressive Audiobook Speech SynthesisAudiobook을 위한 음성 합성은 generalized architecture와 training data의 unbalanced style distribution으로 인해 한계가 있음StyleSpeechExpressive audiobook synthesis를 위해 VQ-VAE-based pre-training을 통한 self-supervised style enhancing method를 적용Text style encoder는 large-scale unlabeled text-only data로 p..
 [Paper 리뷰] ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
[Paper 리뷰] ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
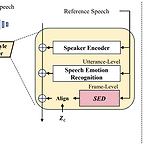
ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis기존의 emotional speech synthesis는 reference audio에서 추출된 utterance-level style embedding을 활용하기 때문에 speech prosody의 multi-scale property를 neglecting 하는 경우가 많음ED-TTSSpeech Emotion Diarization (SED)과 Speech Emotion Recognition (SER)을 활용하여 multi-scale에서 emotion을 모델링SER에서 추출한 utterance-level emotion..
 [Paper 리뷰] MIDI-Voice: Expressive Zero-Shot Singing Voice Synthesis via MIDI-Driven Priors
[Paper 리뷰] MIDI-Voice: Expressive Zero-Shot Singing Voice Synthesis via MIDI-Driven Priors
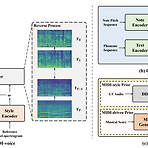
MIDI-Voice: Expressive Zero-Shot Singing Voice Synthesis via MIDI-Driven Priors기존의 Singing Voice Synthesis 모델은 unseen speaker와 fundamental frequency를 부정확하게 예측하므로 낮은 합성 품질을 보임MIDI-Voice더 나은 singing voice style adaptation을 위해 MIDI-based prior를 score-based diffusion model에 적용특히 MIDI-driven prior를 생성하여 note information을 반영하고 고품질의 style adaptation을 지원추가적으로 expressive synthesis를 위해 DDSP-based MIDI-sty..
 [Paper 리뷰] CLaM-TTS: Improving Neural Codec Language Modeling for Zero-Shot Text-to-Speech
[Paper 리뷰] CLaM-TTS: Improving Neural Codec Language Modeling for Zero-Shot Text-to-Speech
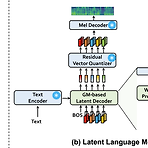
CLaM-TTS: Improving Neural Codec Language Modeling for Zero-Shot Text-to-SpeechZero-shot Text-to-Speech를 위해 audio의 discrete token에 대한 multiple stream을 encode 하는 neural audio codec을 활용할 수 있음이때 audio tokenization은 long sequence legnth와 multiple sequence modeling의 complexity로 인해 scalability의 한계가 있음CLaM-TTSToken length에 대한 뛰어난 compression을 달성하고, Language model이 한 번에 multiple token을 생성할 수 있도록 하는 prob..
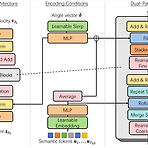 [Paper 리뷰] Efficient Neural Music Generation
[Paper 리뷰] Efficient Neural Music Generation
Efficient Neural Music GenerationMusicLM은 semantic, coarse acoustic, fine acoustic modeling을 통해 뛰어난 음악 생성 능력을 보여주고 있음BUT, MuiscLM은 fine-grained acoustic token을 얻기 위해 많은 계산 비용이 필요함MeLoDy고품질의 음악 생성이 가능하면서 forward pass의 효율성을 개선한 LM-guided diffusion modelSemantic modeling을 위해 MusicLM을 inherit 하고 dual-path diffusion과 audio VAE-GAN을 사용하여 conditioning semantic token을 waveform으로 decoding특히 dual-path dif..