

티스토리 뷰
Paper/TTS
[Paper 리뷰] ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
feVeRin 2024. 5. 14. 09:57반응형
ED-TTS: Multi-Scale Emotion Modeling using Cross-Domain Emotion Diarization for Emotional Speech Synthesis
- 기존의 emotional speech synthesis는 reference audio에서 추출된 utterance-level style embedding을 활용하기 때문에 speech prosody의 multi-scale property를 neglecting 하는 경우가 많음
- ED-TTS
- Speech Emotion Diarization (SED)과 Speech Emotion Recognition (SER)을 활용하여 multi-scale에서 emotion을 모델링
- SER에서 추출한 utterance-level emotion embedding과 SED로 얻은 fine-grained frame-level emotion embedding을 통합하고, 해당 embedding을 denoising diffusion probabilistic model의 reverse process를 condition 하는 데 사용함
- Cross-domain SED를 사용해 soft label을 예측하고 fine-grained emotion-annotated dataset 부족 문제를 해결
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Denoising Diffusion Probabilistic Model (DDPM)은 text-to-speech (TTS)에서 우수한 성능을 보이고 있음
- 대표적으로 EmoDiff는 classifier guidance와 DDPM을 결합하여 controllable emotion synthesis를 수행함
- BUT, 이와 같은 label guidance는 unseen emotion에 대해서는 확장하기 어려움 - 한편으로 EmoMix의 경우, DDPM의 reverse process에 대한 condition으로 pre-trained Speech Emotion Recognition (SER) model에서 추출된 high-dimensional emotion embedding을 활용함
- BUT, 이때 사용되는 utterance-level style embedding은 coarse-to-fine의 multi-scale feature를 반영하지 못함 - 특히 inotation과 같은 fine-grained prosodic expression은 TTS에서 중요한 요소이고, 실제로 speaker는 speech의 특정 부분을 강조하여 emotion을 더 apparent 하게 전달함
- 즉, speech에서 표현되는 emotion을 명확한 temporal boundary를 가지는 varying speech event로써 처리해야 함
- 이때 Speech Emotion Diarization (SED)는 정확한 emotion과 해당하는 boundary를 simultaneously identify 하는 것을 목표로 함
- 대표적으로 EmoDiff는 classifier guidance와 DDPM을 결합하여 controllable emotion synthesis를 수행함
-> 그래서 speech emotion의 nuance와 해당 boundary를 효과적으로 반영할 수 있는 Emotion Diarization-TTS (ED-TTS)를 제안
- ED-TTS
- Utterance-level, frame-level emotional feature를 각각 추출하는 pre-trained SER/SED model을 가지고, DDPM을 기반으로 한 sequence-to-sequence architecture
- 특히 emotional TTS에서 finely annotated dataset 부족 문제를 해결하기 위해 SED를 도입
- 즉, unlabeled dataset에서 SED가 예측한 fine-grained soft emotion label을 사용하여 TTS model training을 supervise 함 - SED와 TTS dataset의 distribution shift를 줄여 soft label accuracy를 향상하는 cross-domain training을 적용
< Overall of ED-TTS >
- DDPM 기반의 multi-scale emotional TTS model로써 utterance-level SER과 frame-level SED를 활용하여, emotion의 category와 variation/boundary를 각각 identify
- SED model을 통해 frame-level fine-grained emotion label을 예측하여 TTS model training을 supervise
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- ED-TTS는 Grad-TTS를 기반으로 함
- 이때 multi-scale style encoder는 SER의 utterance-level extracter로 사용되고, fine-grained emotion feature와 boundary를 예측하기 위해 additional pre-trained SED model을 도입함
- 이후 추출된 multi-scale style embedding을 사용해 DDPM의 reverse process를 condition 함
- 추가적으로 TTS model training을 supervise 하기 위해 pre-trained cross-domain SED model로 예측된 frame-level soft emotion label을 활용
- Preliminary on Score-based Diffusion Model
- ED-TTS는 Grad-TTS를 따라 Stochastic Differential Equation (SDE)를 사용하는 score-based diffusion model을 TTS에 적용
- 먼저 data distribution $X_{0}$를 terminal distribution $X_{T}$로 변환하는 diffusion process는:
(Eq. 1) $dX_{t}=-\frac{1}{2}X_{t}\beta_{t}dt+\sqrt{\beta_{t}}dW_{t},\,\,\, t\in[0,T]$
- $\beta_{t}$ : pre-defined noise schedule, $W_{t}$ : Wiener process
- 이때 해당 SDE에는 diffusion process의 reverse trajectory를 따르는 reverse SDE가 존재함 - 여기서 Ordinary Differential Equation인 reverse time SDE의 discretized version을 solve 함으로써, 다음과 같이 terminal distribution $X_{T}$로부터 data $X_{0}$를 생성할 수 있음:
(Eq. 2) $X_{t-\frac{1}{N}}=X_{t}+\frac{\beta_{t}}{N}\left(\frac{1}{2}X_{t}+\nabla_{X_{t}}\log p_{t}(X_{t})\right)+\sqrt{\frac{\beta_{t}}{N}}z_{t}$
- $t\in\left\{ \frac{1}{N},\frac{2}{N},...,1 \right\}$, $N$ : discretized reverse process step의 수
- $z_{t}$ : standard Gaussian noise에서 sample 된 값 - BUT, score $\nabla_{X_{t}}\log p_{t}(X_{t})$는 intractable 함
- (Eq. 1)에서 distribution $X_{t}|X_{0}\sim\mathcal{N}(\rho(X_{0},t),\lambda(t))$로 유도되고, 여기서 $\rho(X_{t},t), \lambda(t)$는 closed form을 가짐
- 따라서 score는 $\epsilon_{t}$를 Gaussian noise라고 할 때, $\nabla_{X_{t}}\log p_{t}(X_{t}|X_{0})=-\lambda(t)^{-1}\epsilon_{t}$와 같음
- 결과적으로 score를 추정하기 위해 neural network $\epsilon_{\theta}(X_{t},\mu,t,Z_{s})$는 다음을 통해 training 됨:
(Eq. 3) $\mathcal{L}_{diff}=\mathbb{E}_{x_{0},t,Z_{s},\epsilon_{t}}\left[|| \epsilon_{\theta}(X_{t},\mu,t,Z_{s})+\lambda(t)^{-1}\epsilon_{t}||_{2}^{2}\right]$
- $\mu$ : style, text related Gaussian mean
- 먼저 data distribution $X_{0}$를 terminal distribution $X_{T}$로 변환하는 diffusion process는:
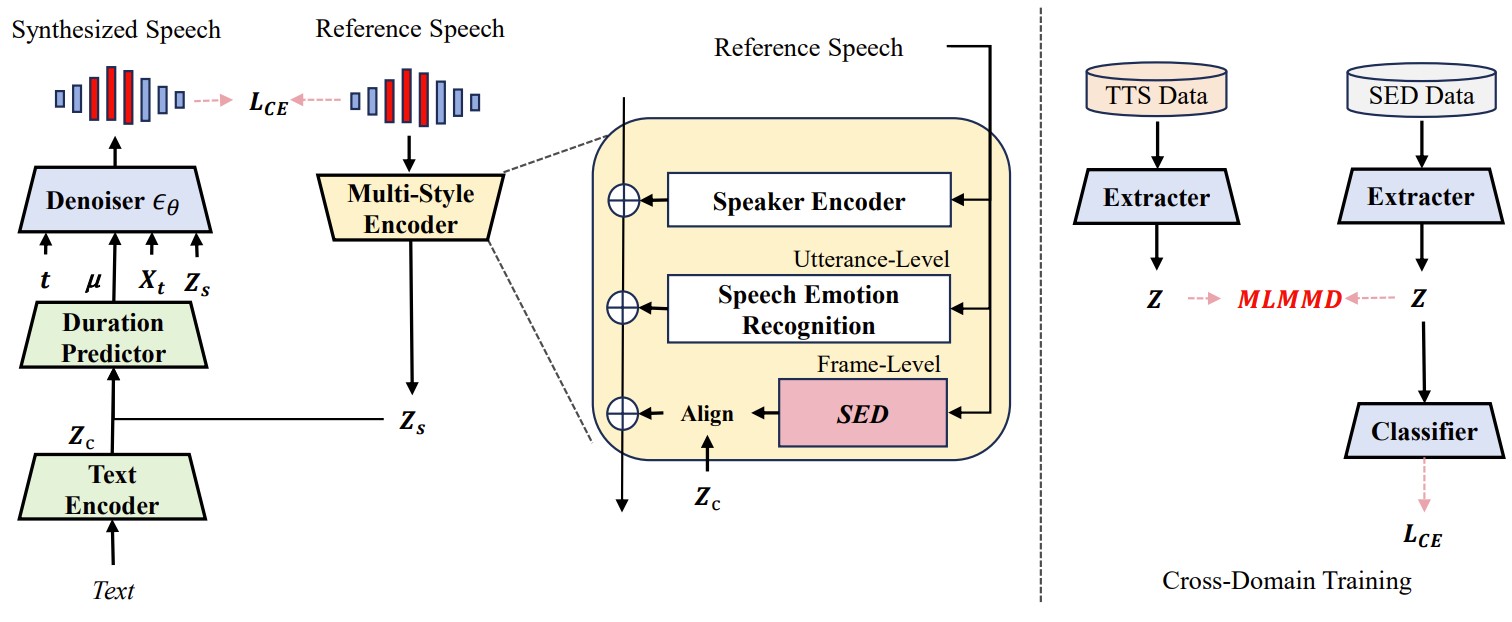
- Multi-Scale Style Encoder
- ED-TTS는 위 그림과 같이 single SER을 포함하는 emotion encoder를 multi-scale로 확장하여 emotion category, variation, boundary information을 추출함
- 해당 module은 frame-level style feature를 추출하기 위한 additional SED model과 utterance-level style feature를 추출하는 pre-trained SER이 포함됨
- 이때 SER model은 reference speech의 mel-spectrogram과 해당 delta, delta-delta coefficient로부터 fixed size embedding을 추출
- SED model로써는 self-supervised model인 pre-trained WavLM을 채택하고 linear classifier를 추가함
- WavLM에는 CNN-based feature encoder와 transformer block이 사용되고 downstream frame-wise SED task에 대해 fine-tuning 됨
- ED-TTS에서는 transformer output을 frame-level style embedding으로써 사용
- 한편으로 speaker conditioning을 위해 resemblyzer를 speaker encoder로 사용함
- 이때 fine-grained style conditioning을 위해서는 variable-length frame-level prosodic feature를 input text representation과 align 해야 함
- 따라서 style representation을 phonetic repsentation $Z_{c}$와 align 하기 위해, 두 modality 간의 alignment를 학습하여 주어진 style에 따라 content를 reweight 하는 multi-head attention block을 적용
- 이때 text encoder에 의해 처리된 phoneme representation $Z_{c}$는 query로 사용되고, frame-level style representation은 key, value로 사용됨 - Content-style alignment 이후, aligned representation은 utterance-level style embedding과 speaker embeddding에 추가되어 multi-scale embedding $Z_{s}$를 구성함
- 최종적으로 $Z_{s}$는 duration predictor와 denoiser에 전달되어 duration modeling을 condition 하고, DDPM process를 reverse 함
- 따라서 style representation을 phonetic repsentation $Z_{c}$와 align 하기 위해, 두 modality 간의 alignment를 학습하여 주어진 style에 따라 content를 reweight 하는 multi-head attention block을 적용
- 해당 module은 frame-level style feature를 추출하기 위한 additional SED model과 utterance-level style feature를 추출하는 pre-trained SER이 포함됨
- Cross-Domain Training of SED
- ED-TTS는 reference와 합성된 speech 간의 emotion gap과 boundary offset을 최소화해야 함
- 이를 위해 SED를 사용하여 unlabeled TTS dataset의 frame-level soft emotion label을 예측하여 ED-TTS를 supervise 함
- 여기서 합성된 sample이 reference와 동일한 frame-level emotion을 가지도록 하는 additional cross-entropy loss를 통해 training 함 - 이때 SED는 TTS dataset과는 다른 SED dataset에 대해 pre-train 되기 때문에 domain adaptation technique을 사용하여 다양한 dataset에 대한 distribution shift를 최소화할 수 있음
- Kernel-based metric인 Maximum Mean Miscrepancy (MMD)는 두 distribution의 equivalence를 결정하는 데 사용됨
- 해당 방식은 domain adaptation 측면에서 emotional TTS의 cross-domain SER에 유용함
- 먼저 source data $S=\{S_{1},S_{2},...,S_{n_{s}}\}$와 target data $T=\{T_{1}, T_{2},...,T_{n_{t}}\}$에 대해, MMD의 정의는:
(Eq. 4) $\textrm{MMD}^{2}(S,T)=\left|\left| \frac{1}{n_{s}}\sum_{i=1}^{n_{s}}\phi(S_{i})-\frac{1}{n_{t}}\sum_{j=1}^{n_{t}}\phi(T_{j}) \right|\right|_{\mathcal{H}}^{2}$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,= \frac{1}{n_{s}^{2}}\sum_{i=1}^{n_{s}}\sum_{j=1}^{n_{s}}k(S_{i},S_{j})+\frac{1}{n_{t}^{2}}\sum_{i=1}^{n_{t}}\sum_{j=1}^{n_{t}}k(T_{i},T_{j})-\frac{2}{n_{s}n_{t}}\sum_{i=1}^{n_{s}}\sum_{j=1}^{n_{t}}k(S_{i},T_{j}) $
- $\phi(\cdot)$ : data에서 Reproducing Kernel Hilbert Space (RKHS)로의 mapping
- $k$ : Gaussian kernel function - 이때 emotion category에 따라 source domain과 target domain을 서로 다른 subdomain으로 나누어, 각 subdomain에 대해 Local MMD (LMMD)를 적용함
- 추가적으로 LMMD를 bottleneck layer와 feature encoder의 CNN layer에도 적용한 Multi-layer LMMD (MLMMD)로 확장하여 더 suitable 한 shared feature space를 얻음:
(Eq. 5) $\textrm{MLMMD}^{2}(S,T)=\frac{1}{L\cdot C}\sum_{L=1}^{L}\sum_{c=1}^{C}\left|\left| \sum_{S_{i}\in D_{s}} W_{S_{i}}^{C}\phi(S_{i})-\sum_{T_{j}\in D_{t}}W_{T_{j}}^{C}\phi(T_{j})\right|\right|_{\mathcal{H}}^{2}$
- $L$ : SED feature encoder의 CNN layer 수, $C$ : emotion category 수 - 일반적으로 source, target domain에서 emotion category는 mix 되어 있거나 unknown임
- 따라서 pre-trained SER에서 얻은 classification probability $W_{S_{i}}^{C}, W_{T_{j}}^{C}$를 사용하여 source domain과 target domain의 mixed/unknown emotion category를 represent 함
- 결과적으로 cross-domain SED의 training은 downstream SED에서 WavLM model을 fine-tuning 하는 것으로 볼 수 있고, 이때 total loss function은:
(Eq. 6) $\mathcal{L}=\mathcal{L}_{CE}+\lambda \mathcal{L}_{MLMMD}$
- $\lambda$ : MLMMD loss에 대한 weight
- 이를 위해 SED를 사용하여 unlabeled TTS dataset의 frame-level soft emotion label을 예측하여 ED-TTS를 supervise 함
3. Experiments
- Settings
- Dataset : BC2013-English Audiobook Dataset
- Comparisons : FG-TTS, EmoMix
- Results
- Cross-Domain SED Results
- Cross-domain SED task에 대해 SED-MLMMD의 성능이 가장 뛰어난 것으로 나타남
- 즉, domain 간의 distributional gap을 줄이면 cross-domain SED 성능이 향상된다는 것을 의미

- Emotional Speech Evaluation
- Emotion speech synthesis 측면에서 ED-TTS가 가장 우수한 합성 품질을 보임
- 이는 ED-TTS에 적용된 multi-scale emotion modeling이 효과적이라는 것을 의미함

- Ablation Study
- Ablation study 측면에서 합성 품질과 reclassification score의 저하는 fine-grained level에서 emotion style representation modeling의 중요성을 나타냄
- 특히 soft label supervision과 cross-domain training이 없는 경우, CERA가 크게 저하됨

반응형
'Paper > TTS' 카테고리의 다른 글
댓글