

 [Paper 리뷰] Fewer-Token Neural Speech Codec with Time-Invariant Codes
[Paper 리뷰] Fewer-Token Neural Speech Codec with Time-Invariant Codes
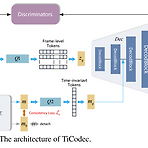
Fewer-Token Neural Speech Codec with Time-Invariant CodesNeural codec은 speech를 discrete token으로 변환하는 데 사용되지만, excessive token sequence는 오히려 prediction accuracy에 부정적인 영향을 줄 수 있음TiCodecTime-invariant information을 별도의 code로 encoding/quantizing하여 encoding에 사용되는 frame-level information의 양을 줄임Utterance에서 time-invariant code의 consistency를 향상하기 위해, time-invariant encoding consistency loss를 도입논문 (ICASSP ..
 [Paper 리뷰] CQNV: A Combination of Coarsely Quantized Bitstream and Neural Vocoder for Low Rate Speech Coding
[Paper 리뷰] CQNV: A Combination of Coarsely Quantized Bitstream and Neural Vocoder for Low Rate Speech Coding
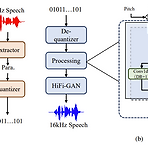
CQNV: A Combination of Coarsely Quantized Bitstream and Neural Vocoder for Low Rate Speech Coding기존 neural codec architecture 내에는 parameter quantization의 redundancy가 나타남CQNVParameteric codec의 coarsely quantized parameter를 neural vocoder와 결합한 neural codecParameter processing module을 도입해 speech coding parameter의 bitstream을 강화하고 reconstruction 품질을 개선논문 (INTERSPEECH 2023) : Paper Link1. Introduction..
 [Paper 리뷰] EdiTTS: Score-based Editing for Controllable Text-to-Speech
[Paper 리뷰] EdiTTS: Score-based Editing for Controllable Text-to-Speech
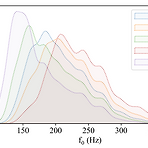
EdiTTS: Score-based Editing for Controllable Text-to-SpeechText-to-Speech를 위해 score-based modeling을 기반으로 speech editing method를 적용할 수 있음EdiTTSAdditional training이나 task-specific optimization 없이 content, pitch 측면에서 audio에 대한 targeted, granular editing을 허용Gaussian prior space에서 coarse, deliberate perturbation을 적용하여 diffusion model에서 desired behavior를 유도하고, mask와 softening kernel을 통해 target region에..
 [Paper 리뷰] SiD-WaveFlow: A Low-Resource Vocoder Independent of Prior Knowledge
[Paper 리뷰] SiD-WaveFlow: A Low-Resource Vocoder Independent of Prior Knowledge
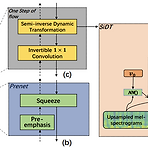
SiD-WaveFlow: A Low-Resource Vocoder Independent of Prior KnowledgeFlow-based nerual vocoder는 high-fidelity의 음성을 합성할 수 있지만, training에 많은 speech data가 필요하고 computationally heavy 함SiD-WaveFlowLow-resource 합성을 위한 flow-based neural vocoderWaveGlow의 Affine Coupling Layer의 계산 효율성을 개선하기 위해 Semi-inverse Dynamic Transformation module을 도입논문 (INTERSPEECH 2022) : Paper Link1. IntroductionVocoder는 mel-spectr..
 [Paper 리뷰] EATS: End-to-End Adversarial Text-to-Speech
[Paper 리뷰] EATS: End-to-End Adversarial Text-to-Speech
EATS: End-to-End Adversarial Text-to-SpeechText-to-Speech pipeline은 일반적으로 multiple stage 방식으로 구성됨EATSNormalized text나 phoneme에서 end-to-end 방식으로 음성을 합성하는 모델Feed-forward generator와 token length prediction에 기반한 differentiable alignment search를 통해 효과적인 training과 추론을 지원Adversarial feedback과 prediction loss를 조합하여 high-fidelity의 음성을 합성추가적으로 생성된 audio의 temporal variation을 capture 할 수 있는 dynamic time war..
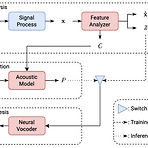 [Paper 리뷰] MSMC-TTS: Multi-Stage Multi-Codebook VQ-VAE based Neural TTS
[Paper 리뷰] MSMC-TTS: Multi-Stage Multi-Codebook VQ-VAE based Neural TTS
MSMC-TTS: Multi-Stage Multi-Codebook VQ-VAE based Neural TTSVector-quantized, compact speech representation을 도입하여 neural text-to-speech의 성능을 향상할 수 있음MSMC-TTSVector-Quantized Variational AutoEncoder based feature를 채택하여 acoustic feature를 서로 다른 time resolution의 sequence로 encoding 하고, 이를 multiple codebook으로 quantize 함Prediction 과정에서는 multi-stage predictor는 Euclidean distance와 triplet loss를 최소화하여 inp..