

 [Paper 리뷰] SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models
[Paper 리뷰] SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion Models
SimpleSpeech: Towards Simple and Efficient Text-to-Speech with Scalar Latent Transformer Diffusion ModelsDiffusion 기반의 non-autoregressive text-to-speech 모델은 높은 효율성이 요구됨SimpleSpeechScalar quantization을 수행하는 speech codec인 SQ-Codec을 활용- Complex speech signal을 finite, compact scalar latent space로 mapping 하는 역할이후 SQ-Codec의 scalar latent space에 transformer diffusion model을 적용논문 (INTERSPEECH 2024) : Pa..
 [Paper 리뷰] TokSing: Singing Voice Synthesis based on Discrete Tokens
[Paper 리뷰] TokSing: Singing Voice Synthesis based on Discrete Tokens
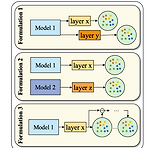
TokSing: Singing Voice Synthesis based on Discrete TokensSelf-supervised learning model에서 추출된 discrete token을 활용하여 singing voice synthesis의 성능을 향상할 수 있음TokSingFlexible token blending을 제공하는 token formulator를 갖춘 discrete-based singing voice synthesis modelMelody signal을 discrete token과 integrate 하고 musical encoder에 melody enhancement strategy를 도입논문 (INTERSPEECH 2024) : Paper Link1. IntroductionSin..
 [Paper 리뷰] Light-TTS: Lightweight Multi-Speaker Multi-Lingual Text-to-Speech
[Paper 리뷰] Light-TTS: Lightweight Multi-Speaker Multi-Lingual Text-to-Speech
Light-TTS: Lightweight Multi-Speaker Multi-Lingual Text-to-SpeechText-to-Speech 모델은 대부분 attention-based autoregressive model이므로 합성 속도가 느리고 model parameter가 크다는 한계가 있음Light-TTSNon-autoregressive model을 기반으로 빠른 음성 합성을 지원다양한 language의 code-switch가 가능한 multi-lingual system을 구성논문 (ICASSP 2021) : Paper Link1. Introduction일반적으로 Text-to-Speech (TTS) 모델은 text-speech alignment를 학습하기 위해 attention mechanism..
 [Paper 리뷰] Lightweight Zero-Shot Text-to-Speech with Mixture of Adapters
[Paper 리뷰] Lightweight Zero-Shot Text-to-Speech with Mixture of Adapters
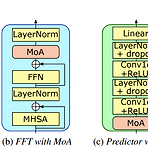
Lightweight Zero-Shot Text-to-Speech with Mixture of AdaptersLarge-scale model을 기반으로 한 zero-shot text-to-speech는 speaker characteristic reproducing에서 우수한 성능을 보이고 있지만, 실제로 활용하기에는 너무 큼Zero-Shot TTS with MoAMixture of Adapters (MoA) module을 non-autoregressive TTS 모델의 decoder와 variance adaptor에 결합Speaker embedding을 기반으로 speaker characteristics와 관련된 적절한 adapter를 선택하여 adatation ability를 향상논문 (INTERSPE..
 [Paper 리뷰] FLY-TTS: Fast, Lightweight and High-Quality End-to-End Text-to-Speech Synthesis
[Paper 리뷰] FLY-TTS: Fast, Lightweight and High-Quality End-to-End Text-to-Speech Synthesis
FLY-TTS: Fast, Lightweight and High-Quality End-to-End Text-to-Speech SynthesisFast, Lightweight Text-to-Speech 모델에 대한 요구사항이 커지고 있음FLY-TTSDecoder를 Fourier spectral coefficient를 생성하는 ConvNeXt block으로 대체하고, inverse STFT를 적용하여 waveform을 합성Model size를 compress 하기 위해 text encoder와 flow-based model에 grouped parameter-sharing을 도입추가적으로 합성 품질 향상을 위해 large pre-trained WavLM을 통해 adversarial training 함논문 (I..
 [Paper 리뷰] DFlow: A Generative Model Combining Denoising AutoEncoder and Normalizing Flow for High Fidelity Waveform Generation
[Paper 리뷰] DFlow: A Generative Model Combining Denoising AutoEncoder and Normalizing Flow for High Fidelity Waveform Generation
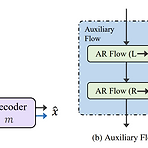
DFlow: A Generative Model Combining Denoising AutoEncoder and Normalizing Flow for High Fidelity Waveform GenerationHigh-fidelity의 waveform generation을 위한 vocoder가 필요함DFlow고품질 생성을 위해 Normalizing Flow와 Denoising AutoEncoder를 결합추가적으로 model size와 training set을 확장하여 DFlow를 large-scale universal vocoder로 scaling up논문 (ICML 2024) : Paper Link1. IntroductionDeep Generative Model (DGM)은 waveform generat..