
 [Paper 리뷰] Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation
[Paper 리뷰] Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech Generation
Single-Codec: Single-Codebook Speech Codec towards High-Performance Speech GenerationMulti-codebook speech codec은 multi-sequence prediction으로 인해 efficiency와 robustness에 bottleneck이 발생함Single-CodecDisentangled VQVAE를 통해 speech를 time-invariant embedding과 phonetically-rich discrete sequence로 decouple 하는 single-codebook, single-sequence codec특히 encoder에서Temporal information을 반영하는 BLSTM module을 통해 co..
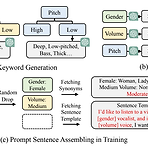 [Paper 리뷰] Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt
[Paper 리뷰] Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language Prompt
Prompt-Singer: Controllable Singing-Voice-Synthesis with Natural Language PromptSinging Voice Synthesis는 여전히 style attribute를 explicitly control 하는 것이 어려움Prompt-SingerGender, vocal range, volume 등을 natural language prompt로 control하는 singing voice synthesis 모델Multi-scale hierarchy를 가지는 decoder-only transformer를 기반으로 melodic accuracy를 유지하면서 text-conditioned vocal range control이 가능한 range-melody de..
 [Paper 리뷰] ScoreDec: A Phase-Preserving High-Fidelity Audio Codec with a Generalized Score-based Diffusion Post-Filter
[Paper 리뷰] ScoreDec: A Phase-Preserving High-Fidelity Audio Codec with a Generalized Score-based Diffusion Post-Filter
ScoreDec: A Phase-Preserving High-Fidelity Audio Codec with a Generalized Score-based Diffusion Post-FilterWaveform-domain end-to-end neural codec은 low-bitrate의 coding이 가능하지만 여전히 natural audio와의 품질 차이가 존재함해당 neural codec의 성능을 향상하기 위해서는 GAN training이 필요하지만, original phase information preserving을 방해한다는 문제가 있음ScoreDecGAN training에서 original phase preserving을 위해, complex spectral domain에서 score-base..
 [Paper 리뷰] Glow-WaveGAN: Learning Speech Representations from GAN-based Variational Auto-Encoder for High Fidelity Flow-based Speech Synthesis
[Paper 리뷰] Glow-WaveGAN: Learning Speech Representations from GAN-based Variational Auto-Encoder for High Fidelity Flow-based Speech Synthesis
Glow-WaveGAN: Learning Speech Representations from GAN-based Variational Auto-Encoder for High Fidelity Flow-based Speech SynthesisText-to-Speech 모델은 주로 mel-spectrogram과 같은 low-resolution intermediate representation에 의존하므로 vocoder와 acoustic model 간의 mismatch가 존재함Glow-WaveGANPre-designed intermediate representation에 의존하지 않고 GAN과 결합된 VAE를 사용하여 speech에서 latent representation을 직접 학습이후 flow-based aco..
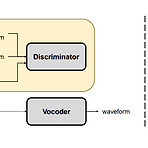 [Paper 리뷰] GANSpeech: Adversarial Training for High-Fidelity Multi-Speaker Speech Synthesis
[Paper 리뷰] GANSpeech: Adversarial Training for High-Fidelity Multi-Speaker Speech Synthesis
GANSpeech: Adversarial Training for High-Fidelity Multi-Speaker Speech SynthesisMulti-speaker text-to-speech 모델을 fine-tuning 하여 limited training data로 다양한 speaker의 음성을 합성할 수 있음- BUT, 여전히 real speech sample과 비교하여 합성 결과의 품질이 떨어짐GANSpeechNon-autoregressive Text-to-Speech 모델에 adversarial training을 적용추가적으로 adversarial training에서 사용되는 feature matching loss에 대한 automatic scaling method를 도입논문 (INTERSPEE..
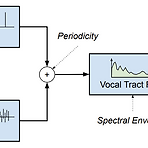 [Paper 리뷰] Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech Synthesis
[Paper 리뷰] Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech Synthesis
Ultra-Lightweight Neural Differential DSP Vocoder for High Quality Speech SynthesisNeural vocoder를 통해 고품질의 audio를 합성할 수 있지만, 여전히 low-end device에서는 real-time으로 사용하기 어려움한편으로 Digital Signal Processing 기반의 vocoder는 lightweight FFT를 통해 구현될 수 있으므로 neural vocoder보다 빠르게 동작가능함- BUT, vocal tract의 approximate representation에 대해 over-smoothed acoustic model prediction을 사용하므로 합성 품질이 저하되는 경향이 있음DDSP VocoderDi..