

티스토리 뷰
반응형
EATS: End-to-End Adversarial Text-to-Speech
- Text-to-Speech pipeline은 일반적으로 multiple stage 방식으로 구성됨
- EATS
- Normalized text나 phoneme에서 end-to-end 방식으로 음성을 합성하는 모델
- Feed-forward generator와 token length prediction에 기반한 differentiable alignment search를 통해 효과적인 training과 추론을 지원
- Adversarial feedback과 prediction loss를 조합하여 high-fidelity의 음성을 합성
- 추가적으로 생성된 audio의 temporal variation을 capture 할 수 있는 dynamic time warping을 도입
- 논문 (ICLR 2021) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 일반적으로 independent 하게 설계된 multiple stage로 구성됨
- 대표적으로 text normalization, aligned linguistic featurisation, mel-spectrogram synthesis, raw audio waveform synthesis 등의 여러 pipeline을 가짐
- 해당 modular pipeline을 통해 high-fidelity의 합성이 가능하지만, 다음의 몇 가지 단점이 있음
- 각 stage 마다 supervision이 필요하므로 상당한 ground-truth annotation과 sequential training이 요구됨
- Machine learning에서 효과적인 data-driven end-to-end learning의 이점을 활용할 수 없음
- 특히 end-to-end 방식은 network 전체에서 학습된 intermediate feature representation을 유지함으로써 기존 TTS 모델에 존재하는 intermediate bottleneck을 제거 가능
- 각 stage 마다 supervision이 필요하므로 상당한 ground-truth annotation과 sequential training이 요구됨
-> 그래서 TTS pipeline을 단순화하고 end-to-end 방식으로 동작하는 EATS를 제안
- EATS
- Pure text나 unaligned raw phoneme sequence에서 speech waveform을 output 하는 End-to-end Adversarial TTS 모델
- 모델의 aligner는 raw input sequence를 처리하고 learnt abstract feature space에서 low-frequency aligned feature를 생성
- Aligner output은 기존 TTS의 temporally aligned mel-spectrogram이나 linguistic feature를 대체 - 이후 해당 feature는 decoder로 전달되고, 1D convolution으로 upsampling 하여 24kHz의 waveform을 생성
- 추가적으로 adversarial feedback과 domain-specific loss를 결합하여 end-to-end training을 지원
< Overall of EATS >
- 각 input token의 duration을 예측하고 audio-aligned representation을 생성하는 fully differentiable, efficient feed-forward aligner architecture를 도입
- Flexible dynamic time warping-based prediction loss를 사용하여 input conditioning과 alignment를 enforcing 하고 음성의 timing variability를 capture
- 결과적으로 state-of-the-art 수준의 합성 품질을 달성
2. Method
- 논문은 24kHz의 raw audio에 character/phoneme sequence를 mapping하는 neural network (generator)를 training 하는 것을 목표로 함
- 이때 input/output signal의 length는 서로 다르고 align되어 있지 않기 때문에, 각 input token이 어떤 output token에 해당하는지 알 수 없음
- 따라서 위 문제를 해결하기 위해, EATS는 2개의 block으로 나누어서 구성됨
- Aligner : unaligned input sequence를 output과 align하고 200Hz의 low sample rate로 mapping 하는 역할
- Decoder : aligner의 output을 full audio frequency로 upsampling하는 역할
- 이때 전체 architectrue는 differentiable하고 end-to-end 방식으로 training 됨
- 특히 EATS는 feed-forward convolutional network로 구성되어 real-time보다 200배 빠른 속도로 합성이 가능함
- EATS는 aligned linguistic feature에서 동작하는 adversarial network인 GAN-TTS를 기반으로 구성됨
- 이때 pre-computed linguistic feature를 사용하는 GAN-TTS와 달리 EATS의 generator는 aligner block의 output을 활용
- 특히 latent vector $\mathbf{z}$와 speaker embedding $\mathbf{s}$를 통해 speaker-conditional 하게 모델을 구성하여, multiple speaker dataset에서도 training 할 수 있도록 함
- 추가적으로 GAN-TTS의 random window discriminator (RWD)를 채택하고, $\mu$-law transform을 적용하여 real audio input을 pre-process 함 - 결과적으로 generator는 $\mu$-law domain에서 audio를 생성하도록 training 되고, sampling시에는 inverse transformation을 적용
- 여기서 generator training을 위한 loss function은:
(Eq. 1) $\mathcal{L}_{G}=\mathcal{L}_{G,adv}+\lambda_{pred}\mathcal{L}''_{pred}+\lambda_{length}\mathcal{L}_{length}$
- $\mathcal{L}_{G,adv}$ : adversarial loss로 GAN-TTS의 discriminator objective인 Hinge loss와 pair 됨
- $\mathcal{L}''_{pred}$ : auxiliary prediction loss, $\mathcal{L}_{length}$ : length loss - 이러한 adversaraial training은 효율적인 feed-forward training을 가능하게 하는 장점이 있음
- 특히 해당 loss는 mode-seeking 되는 경향이 있으므로, TTS와 같이 realism이 중요한 경우 유용함
- 여기서 generator training을 위한 loss function은:
- 이때 pre-computed linguistic feature를 사용하는 GAN-TTS와 달리 EATS의 generator는 aligner block의 output을 활용

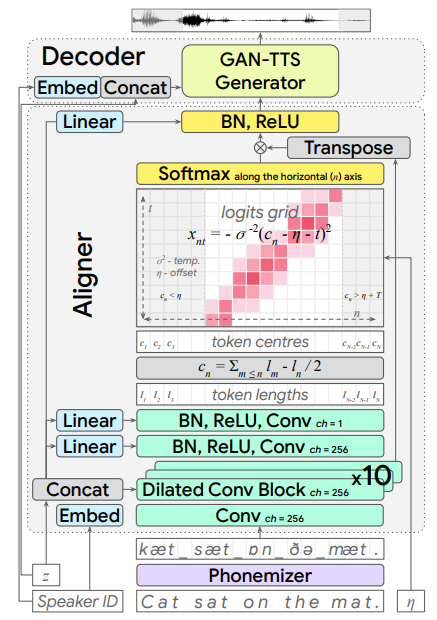
- Aligner
- 먼저 length $N$의 token sequence $\mathbf{x}=(x_{1},...,x_{N})$이 주어지면, token representation $\mathbf{h}=f(\mathbf{x},\mathbf{z},\mathbf{s})$를 계산함
- $f$ : batch normalization과 ReLU activation이 포함된 dilated convolution layer stack
- Latent $\mathbf{z}$와 speaker embedding $\mathbf{s}$는 batch normalization layer의 scale과 shift parameter를 modulate 하는 역할 - 다음으로 각 input token의 length를 $l_{n}=g(h_{n},\mathbf{z},\mathbf{s})$와 같이 개별적으로 예측하고, 이때 $g$는 MLP로써 예측되는 length가 non-negative임을 보장하기 위해 output에 ReLU nonlinearity를 사용함
- 이후 token length의 cumulative sum $e_{n}=\sum_{m=1}^{n}l_{m}$으로 predicted token end position을 찾을 수 있음
- 이때 token centre position은 $c_{n}=e_{n}-\frac{1}{2}l_{n}$ - 그러면 해당 predicted position을 기반으로 token representation을 200Hz에서 audio-aligned representation으로 interpolate 할 수 있음: $\mathbf{a}=(a_{1},...,a_{S})$
- $S=\lceil N\rceil$ : output timestep의 총 개수 - 최종적으로 $a_{t}$ 계산을 위해, $t$와 $c_{n}$ 사이의 squared distance에 대한 softmax를 적용하여 token representation $h_{n}$에 대한 interpolation weight를 얻음:
(Eq. 2) $w^{n}_{t}=\frac{\exp(-\sigma^{-2}(t-c_{n}))^{2}}{\sum_{m=1}^{N}\exp(-\sigma^{-2}(t-c_{m}))^{2}}$
- Gaussian kenel과 같이, temperature parameter $\sigma^{2}$로 scale 되고 논문에서는 10.0으로 설정해 사용
- 이후 token length의 cumulative sum $e_{n}=\sum_{m=1}^{n}l_{m}$으로 predicted token end position을 찾을 수 있음
- 위의 weight를 사용하면 $a_{t}=\sum_{n=1}^{N}w_{t}^{n}h_{n}$를 계산할 수 있고, 이는 non-uniform interpolation과 같음
- 결과적으로 token length를 예측하고 cumulative summation을 통해 position을 구함으로써, alignment의 monocity를 implict 하게 enforce 할 수 있음
- 특히 punctuation과 같이 non-monotonic effect가 있는 token은 dilated convolution $f$의 stack으로 인해 전체 utterance에 영향을 줄 수 있음
- 이는 convolution의 receptive field가 전체 token sequence에 걸쳐 information을 propagate 할 수 있을 만큼 충분히 크기 때문 - 추가적으로 convolution은 다양한 sequence length에 대한 generalization을 보장할 수도 있음
- 특히 punctuation과 같이 non-monotonic effect가 있는 token은 dilated convolution $f$의 stack으로 인해 전체 utterance에 영향을 줄 수 있음
- $f$ : batch normalization과 ReLU activation이 포함된 dilated convolution layer stack
- Windowed Generator Training
- Training example은 1~20 second로 legnth가 다양하므로 training 중에 모든 sequence를 maximal length로 padding 하는 것은 expensive 함
- 실제로 24kHz에서 20 second의 audio은 480000 timestep에 해당하므로 memory requirement가 높아짐
- 따라서 논문은 각 example에서 2 second window를 randomly extract 하는 training window를 도입해 random offset $\eta$를 uniformly sampling 함
- 이때 aligner는 해당 window에 대한 200Hz audio-aligned representation을 생성한 다음, decoder로 전달함
- 여기서 sampled window 내에 있는 timestep $t$에 대해서만 $a_{t}$를 계산할 수 있지만, 전체 input sequence에 대한 predicted token length $l_{n}$도 계산해야 함
- Evaluation 중에는 full utterance에 대한 audio-aligned representation을 생성하고 decoder로 전달함
- Adversarial Discriminators
- Random Window Discriminator
- EATS는 GAN-TTS의 Random Window Discriminator (RWD)를 ensemble 하여 사용함
- 여기서 각 RWD는 training window에서 randomly sample 된 서로 다른 length의 audio fragment에서 동작함
- 이를 위해 논문은 $[240,480,960,1920,3600]$의 window size를 가지는 5개의 RWD를 사용
- 이때 24kHz에서 3600 sample은 150ms audio에 해당하므로 모든 RWD는 short timescale에서 동작함 - 한편으로 EATS의 모든 RWD는 text에 대해 unconditional 함
- 즉, text sequence나 aligner output에 access 할 수 없고, 대신 projection embedding을 통해 speaker에 condition 됨
- Spectrogram Discriminator
- 추가적으로 spectrogram domain에서 full training window에 대해 동작하는 spectrogram discriminator를 도입함
- 이를 위해, audio signal에서 log-scale mel-sepctrogram을 추출하고 BigGAN-deep architecture를 적용함
- 여기서 spectrogram discriminator 역시 projection embedding을 통해 speaker identity를 반영함
- Spectrogram Prediction Loss
- Adversarial feedback만으로는 alignment를 학습하기에 부족함
- Training 시작 시 aligner는 정확한 alignment를 생성하지 못하므로 input token의 information은 부정확하게 temporally distribute 됨
- Unconditional discriminator는 useful learning signal을 제공하지 않으므로, conditional discriminator를 사용해야 함
- BUT, conditional discriminator는 aligned ground-truth가 필요한 문제가 있음
- 따라서 conditional discriminator에도 aligner module을 적용하면, 마찬가지로 부정확하게 동작하므로 사실상 unconditional discriminator와 같아짐
- 위 문제를 해결하기 위해, 논문은 spectrogram domain에서 explicit prediction loss를 사용하여 learning을 guide 하는 방식을 도입함
- 먼저 generator output의 log-scale mel-spectrogram과 해당 ground-truth training window 간의 $L_{1}$ loss를 최소화함
- 그러면 $S_{gen}$을 생성된 audio의 spectrogram, $S_{gt}$를 ground-truth spectrogram, $S[t,f]$를 timestep $t$에서 log-scale 된 magnitude, $f$를 mel-frequency bin이라고 했을 때, prediction loss는:
(Eq. 3) $\mathcal{L}_{pred}=\frac{1}{F}\sum_{t=1}^{T}\sum_{f=1}^{F}|S_{gen}[t,f]-S_{gt}[t,f]|$
- $T, F$ : 각각 timestep과 mel-frequency bin 수 - Time-domain이 아닌 spectrogram-domain에서 prediction loss를 계산하면, 생성된 signal과 ground-truth 사이의 phase difference에 대한 invariance가 증가하는 이점이 있음
- 추가적으로 $S_{gt}$를 계산하기 전에, ground-truth waveform에 small jitter를 적용하여 audio의 artifact를 줄임
- 이때 $\mathcal{L}_{pred}$에서는 학습을 위해 mel-spectrogram을 사용하지만, 전체 generator 자체는 spectrogram을 생성하지 않음
- 즉, 해당하는 waveform에서 gradient를 backpropagating 하기 위해 spectrogram 변환을 사용
- Dynamic Time Warping
- Spectrogram prediction loss는 token length가 deterministic 하다고 가정함
- 따라서 이러한 alignment를 relax 하기 위해 Dynamic Time Warping (DTW)을 채택함
- DWT는 생성된 spectrogram $S_{gen}$과 target spectrogram $S_{gt}$ 간의 minimal-cost alignment path $p$를 iterative 하게 find 하여 prediction loss를 계산하는 방식
- 두 spectrogram의 first timestep $p_{gen,1}=1, p_{gt,1}=1$에서 시작하고, 각 iteration $k$에서 다음의 possible action 중 하나를 수행:
- Action 1. $S_{gen}, S_{gt}$ 모두에서 next time step으로 이동 : $p_{gen,k+1}=p_{gen,k}+1, p_{gt,k+1}=p_{gt,k}+1$
- Action 2. $S_{gt}$에서만 next time step으로 이동 : $p_{gen,k+1}=p_{gen,k}, p_{gt,k+1}=p_{gt,k}+1$
- Action 3. $S_{gen}$에서만 next time step으로 이동 : $p_{gen,k+1}=p_{gen,k}+1, p_{gt,k+1}=p_{gt,k}$ - 그러면 resulting path는 $p=\left\langle (p_{gen,1},p_{gt,1}),...,(p_{gen,K_{p}},p_{gt,K_{p}})\right\rangle$과 같이 얻어짐
- $K_{p}$ : length
- 각 action에서 $S_{gen}[p_{gen,k}], S_{gt}[p_{gt,k}]$ 사이의 $L_{1}$ distance에 따라 cost가 할당되고, 두 spectrogram을 동시에 선택하지 않는 경우 warp penalty $w$가 할당됨
- 즉, Action 2, 3을 선택하는 경우 spectrogram을 warping 함 ($w=1.0$을 사용) - 결과적으로 warp penalty는 identity alignment를 크게 벗어나지 않는 alignment path를 발생시킴
- Warping이 발생하는 iteration을 1, 그렇지 않은 경우를 0으로 설정하는 indicator $\delta_{k}$가 있다고 하자
- 그러면 total path cost $c_{p}$는:
(Eq. 4) $c_{p}=\sum_{k=1}^{K_{p}}\left(w\cdot \delta_{k}+\frac{1}{F}\sum_{f=1}^{F}|S_{gen}[p_{gen,k},f]-S_{gt}[p_{gt,k},f] |\right)$
- $K_{p}$ : warping degree에 따라 결정 ($T\leq K_{p}\leq 2T-1$) - DTW prediction loss는:
(Eq. 5) $\mathcal{L}'_{pred}=\min_{p\in\mathcal{P}}c_{p}$
- $\mathcal{P}$ : 모든 valid path set, $p\in\mathcal{P}$는 $p_{gen,1}=p_{gt,1}=1$이고 $p_{gen,K_{p}}=p_{gt,K_{p}}=T$일 때 성립 (즉, spectrogram의 first/last timestep이 align 된 경우)
- Alignment의 최소값을 찾기 위해, dynamic programming을 적용
- DTW는 differentiable 하지만, gradient는 minimal path로만 propagate 되므로 최적화가 어려움
- 따라서 EATS는 minimum을 soft minimum으로 대체한 soft DTW를 채택:
(Eq. 6) $\mathcal{L}''_{pred}=-\tau\cdot \log \sum_{p\in\mathcal{P}}\exp\left(-\frac{c_{p}}{\tau}\right)$
- $\tau=0.01$ : temperature parameter, $\lambda_{pred}=1.0$ : loss scale factor
- $\tau\rightarrow 0$으로 두는 것으로 minimum operation을 recover 할 수 있음 - 결과적으로 해당 loss는 모든 path에 대한 weighted aggregated cost로써, 모든 feasible path에 대한 gardient propagation을 가능하게 함
- 이때 trade-off로 인해 $\tau$가 클수록 최적화가 쉬워지지만, resulting loss는 minimal path cost를 덜 반영하게 됨
- 따라서 EATS는 minimum을 soft minimum으로 대체한 soft DTW를 채택:
- Prediction loss의 alignment를 relaxing을 통해 generator는 정확하게 align 된 waveform을 생성하더라도 큰 penalize를 받지 않음
- 이는 adversarial loss와 결합되어 보다 realistic 한 audio를 생성할 수 있도록 compensate 함
- 따라서 이러한 alignment를 relax 하기 위해 Dynamic Time Warping (DTW)을 채택함

- Aligner Length Loss
- 모델이 realistic token length prediction을 생성할 수 있도록, 예측된 utterance length가 ground-truth length에 가까워지도록 하는 loss를 추가함
- 여기서 해당 length는 모든 token length prediction을 summing 하여 얻어짐
- $L$을 200Hz에서 training utterance의 timestep 수, $l_{n}$을 $n$-th token의 predicted length, $N$을 token 수라고 했을 때, length loss는:
(Eq. 7) $\mathcal{L}_{length}=\frac{1}{2}\left(L-\sum_{n=1}^{N}l_{n}\right)^{2}$
- 논문은 scaling factor $\lambda_{length}=0.1$을 사용 - 이때 predicted length $l_{n}$은 ground-truth에 match 될 수 없음
- Text Pre-Processing
- EATS는 phoneme input을 사용하는 경우 더 좋은 성능을 얻을 수 있음
- 따라서 text normalization을 적용하여 character sequence를 pronounce 되는 대로 spell out 하고, phoneme으로 변환함
- 이를 위해 partial normalization과 phonemization을 지원하는 phonemizer를 사용 - 최종적으로 각 utterance의 beginning과 end에 존재하는 silence를 aligner가 고려할 수 있도록, sequence에 special silence token을 pre-/post-pad 함
- 따라서 text normalization을 적용하여 character sequence를 pronounce 되는 대로 spell out 하고, phoneme으로 변환함
3. Experiments
- Settings
- Dataset : North American English Speech (internal)
- Comparisons : GAN-TTS, WaveNet, Parallel WaveNet, Tacotron2
- Results
- EATS는 aligned linguistic feature에 의존하는 기존 방식 보다 더 적은 supervision을 사용하면서 뛰어난 합성 품질을 보임
- 추가적으로 ablation study 측면에서, 각 component를 제거하는 경우 성능 저하가 발생하는 것으로 나타남

- Training set의 주요 speaker 4명에 대한 MOS를 비교해 보면, 일반적으로 더 많은 training data를 가지면 MOS도 개선되지만 완전한 correlation을 가지지는 않음
- 특히 speaker #3의 경우, training data 수는 전체에서 3번째에 속하지만 가장 높은 MOS를 달성함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글