

 [Paper 리뷰] GenerSpeech: Toward Style Transfer for Generalizable Out-of-Domain Text-to-Speech
[Paper 리뷰] GenerSpeech: Toward Style Transfer for Generalizable Out-of-Domain Text-to-Speech
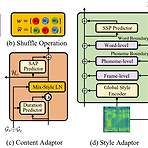
GenerSpeech: Towards Style Transfer for Generalizble Out-of-Domain Text-to-SpeechOut-of-Domain 음성 합성을 위해 style transfer를 활용할 수 있지만 몇 가지 한계가 존재함- Expressive voice의 dynamic style feature는 모델링과 transfer가 어려움- Text-to-Speech 모델은 source data와 다른 Out-of-Domain condition을 handle 할 수 있을 만큼 robust 해야 함GenerSpeechOut-of-Domain custom voice에 대해 high-fidelity zero-shot style transfer를 가능하게 하는 text-to-speech..
 [Paper 리뷰] VarianceFlow: High-Quality and Controllable Text-to-Speech using Variance Information via Normalizing Flow
[Paper 리뷰] VarianceFlow: High-Quality and Controllable Text-to-Speech using Variance Information via Normalizing Flow
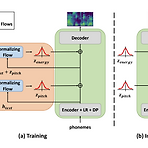
VarianceFlow: High-Quality and Controllable Text-to-Speech using Variance Information via Normalizing Flow Text와 speech 간의 one-to-many 관계를 학습하기 위해 두 가지 방식을 활용할 수 있음 - Normalizing Flow의 사용 - 합성 과정에서 pitch, energy 같은 variance information의 반영 VarianceFlow Normalizing Flow를 통해 variance를 모델링하여 더 정확하게 variance information을 예측 Normalizing Flow의 objective function은 variance와 text를 disentangle 하여 varianc..
 [Paper 리뷰] DDSP: Differentiable Digital Signal Processing
[Paper 리뷰] DDSP: Differentiable Digital Signal Processing
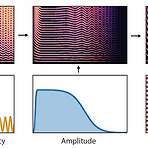
DDSP: Differentiable Digital Signal Processing대부분의 audio 생성 모델은 time 또는 frequency domain 중 하나에서 sampling을 생성함- Signal을 표현하는 데는 적합하지만 sound가 생성되고 인식되는 방식에 대한 knowledge를 활용하지 않음Vocoder의 경우 domain knowledge를 성공적으로 반영할 수 있지만 auto-differentiable-based 방식과는 통합하기 어려움Differentiable Digital Signal Processing (DDSP)기존의 signal processing 요소를 deep learning 방식과 통합Neural network의 expressive power를 잃지 않으면서 강력한..
 [Paper 리뷰] DiffVoice: Text-to-Speech with Latent Diffusion
[Paper 리뷰] DiffVoice: Text-to-Speech with Latent Diffusion
DiffVoice: Text-to-Speech with Latent Diffusion Text-to-Speech 모델의 성능 향상을 위해 latent diffusion을 활용할 수 있음 DiffVoice Adversarial training을 활용한 variational autoencoder를 통해 speech signal을 phoneme-rate representation으로 encode Diffusion model을 통한 latent representation과 duration의 joint modelling 논문 (ICASSP 2023) : Paper Link 1. Introduction Diffusion model은 합성 작업에서 뛰어난 성능을 보이고 있음 Text-to-Speech (TTS)에서는..
 [Paper 리뷰] DSPGAN: A GAN-based Universal Vocoder for High-Fidelity TTS by Time-Frequency Domain Supervision from DSP
[Paper 리뷰] DSPGAN: A GAN-based Universal Vocoder for High-Fidelity TTS by Time-Frequency Domain Supervision from DSP
DSPGAN: A GAN-based Universal Vocoder for High-Fidelity TTS by Time-Frequency Domain Supervision from DSP Generative Adversarial Network를 활용한 vocoder는 빠른 추론 속도와 효과적인 raw waveform 합성이 가능 하지만 unseen speaker에 대해서는 high-fidelity speech를 합성하기는 어려움 DSPGAN Digital Signal Processing에서의 time-frequency domain supervision을 도입하여 고품질 합성을 지원 Ground-truth와 예측 mel-spectrogram 사이의 mismatch를 해소하기 위해 DSP module에서 ..
 [Paper 리뷰] MixPath: A Unified Approach for One-shot Neural Architecture Search
[Paper 리뷰] MixPath: A Unified Approach for One-shot Neural Architecture Search
MixPath: A Unified Approach for One-shot Neural Architecture Search일반적인 two-stage neural architecture search method는 single-path search space에 제한되어 있음Multi-path structure를 효율적으로 search 하는 것은 여전히 어려움MixPathCandidate architecture를 정확하게 평가하기 위해 one-shot multi-path supernet을 학습시킴서로 다른 feature statistics를 regularize하기 위해 Shadow Batch Normalization을 도입결과적으로 Shadow Batch Normalization을 통해 최적화를 안정시키고 ra..