

티스토리 뷰
Paper/Conversion
[Paper 리뷰] ReFlow-VC: Zero-Shot Voice Conversion based on Rectified Flow and Speaker Feature Optimization
feVeRin 2025. 7. 25. 13:08반응형
ReFlow-VC: Zero-Shot Voice Conversion based on Rectified Flow and Speaker Feature Optimization
- Diffusion-based Voice Conversion model은 상당한 sampling step을 요구함
- ReFlow-VC
- Rectified Flow를 통해 Gaussian distribution을 direct path를 따라 true mel-spectrogram distribution으로 변환
- 추가적으로 content, pitch information을 활용하여 speaker feature를 optimize
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Zero-Shot Voice Conversion (VC)는 linguistic content를 변경하지 않으면서 source speaker speech를 target speaker voice로 convert 하는 것을 목표로 함
- 특히 zero-shot VC를 위해서는 content, timbre를 포함한 다양한 attribute를 disentangle 해야 함
- 기존의 zero-shot VC model은 source speaker의 speaking style과 linguistic content를 target speaker의 timbre와 combine 하여 converted speech를 생성함
- 대표적으로 AutoVC는 pre-trained speaker verification network를 conditional input으로 사용함
- BUT, speech signal의 complexity와 content, timbre modeling으로 인한 한계가 있음 - 추가적으로 대부분의 VC model은 CycleGAN-VC, StarGAN-VC와 같이 AutoEncoder, Generative Adversarial Network architecture에 의존적임
- 대표적으로 AutoVC는 pre-trained speaker verification network를 conditional input으로 사용함
- 한편으로 DiffVC, DDDM-VC 등은 Denoising Diffusion Probabilistic Model (DDPM)을 활용하여 high-quality sample을 생성함
- BUT, diffusion model은 statisfactory sample을 얻기 위해 상당한 iteration이 필요함
-> 그래서 diffusion-based VC model의 추론 속도를 향상한 ReFlow-VC를 제안
- ReFlow-VC
- Rectified Flow Model을 기반으로 direct path를 통해 Gaussian distribution을 true mel-spectrogram distribution으로 transform
- 추가적으로 cross-attention과 gated fusion을 통해 speaker feature에 대한 fine-grained control을 지원
< Overall of ReFlow-VC >
- Rectified Flow Model을 활용한 zero-shot VC model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Rectified Flow
- Rectified Flow Model은 standard Gaussian distribution $\pi_{0}$를 straight-line을 통해 ground-truth distribution $\pi_{1}$으로 transform 하는 Ordinary Differential Equation (ODE) model에 해당함
- Sample $X_{0}\sim \pi_{0}, X_{1}\sim \pi_{1}$이 주어졌을 때 rectified flow는:
(Eq. 1) $dZ_{t}=v(Z_{t},t)dt$
- $Z_{0}$는 $\pi_{0}$에서 얻어지고, transformation은 distribution $\pi_{1}$을 따름
- $v$ : 두 distribution 간의 direction $(X_{1}-X_{0})$와 flow를 align 하는 drift force - 이때 flow는 least squares regression problem을 minimize 하여 학습됨:
(Eq. 2) $ \min_{v}\int_{0}^{1}\left|\left| (X_{1}-X_{0})-v(X_{t},t)\right|\right|^{2}dt$ - $X_{t}$는 $X_{0},X_{1}$ 간의 linear interpolation으로써:
(Eq. 3) $X_{t}=tX_{1}+(1-t)X_{0}$ - $X_{t}$의 naive evolution은 non-causal path $dX_{t}=(X_{1}-X_{0})dt$를 따르는 반면, rectified flow는 $(X_{1}-X_{0})$에 따라 $v$를 adjust 하여 trajectory가 any point에서도 cross 하지 않도록 함
- 이를 통해 rectified flow는 solution의 uniqueness를 preserve 할 수 있음
- 즉, rectified flow는 non-causal intersection을 avoid 하여 well-defined non-crossing path를 보장함
- Training 시 rectified flow objective는 drift force $v$를 minimize 하는 것을 학습함:
(Eq. 4) $\hat{\theta}=\arg\min_{\theta}\mathbb{E}\left[\left|\left| (X_{1}-X_{0})-v(X_{t},t)\right|\right|^{2}\right]$
- $t\sim \text{Uniform}([0,1])$ - Training 이후 학습된 model은 ODE $dZ_{t}=\hat{v}(Z_{t},t)dt$를 solve 하여 $X_{0}$를 $X_{1}$로 transform 함
- 해당 procedure는 recursively apply 할 수 있고, transformation sequence $Z'=\text{ReFlow}(Z_{0},Z_{1})$을 통해 transport efficiency를 개선하고 linear flow trajectory를 얻을 수 있음
- 이러한 recursive process를 통해 time-discretization error를 reduce 하고 flow simulating에 대한 computational advantage를 얻을 수 있음
- Sample $X_{0}\sim \pi_{0}, X_{1}\sim \pi_{1}$이 주어졌을 때 rectified flow는:

- Rectified Flow Model for VC
- ReFlow-VC는 feature fusion 이후 time $t$와 speaker condition feature $c$에 따라 noise distribution을 mel-spectrogram distribution으로 변환함
- 먼저 $\pi_{0}$를 standard Gaussian distribution, $\pi_{1}$을 ground-truth mel-spectrogram data distribution이라고 하자
- $X_{0}\sim \pi_{0}, X_{1}\sim \pi_{1}$ - 그러면 ReFlow-VC의 training objective는:
(Eq. 5) $ \mathcal{L}_{\theta}=\mathbb{E}\left[\left|\left| (X_{1}-X_{0})-v_{\theta}(X_{t},t,c)\right|\right|^{2}\right]$
- $t\in \text{Uniform}([0,1])$, $X_{t}=tX_{1}+(1-t)X_{0}$
- ReFlow-VC는 model $v_{\theta}$ output과 $(X_{1}-X_{0})$ 간의 $L2$ loss를 제외한 어떤 auxiliary loss도 필요하지 않음 - 추론 시에는 speaker feature $c$에 condition 된 $Z_{0}\sim \pi_{0}$에서 시작하여 $v_{\theta}$를 기반으로 ODE를 directly solve 함
- High-fidelity generation의 경우 RK45 ODE solver를 사용하고, one-step generation의 경우 Euler ODE solver를 사용할 수 있음
- 추가적으로 recursive rectified flow를 VC에 적용하여 2-ReFlow-VC를 얻을 수 있음
- 2-ReFlow-VC는 ReFlow-VC로 생성된 sample을 사용해 rectified flow model을 retrain 하는 것과 같음
- 먼저 $\pi_{0}$를 standard Gaussian distribution, $\pi_{1}$을 ground-truth mel-spectrogram data distribution이라고 하자
3. Architecture
- Encoder
- Encoder는 average voice encoder인 HuBERT-soft, speaker encoder인 VQ-VAE, feature fusion module로 구성됨
- 논문은 DiffVC를 따라 speaker-independent speech representation으로 average phoneme-level mel feature를 채택함
- Source audio는 average voice encoder를 통해 average speaker mel $\text{Average_mel}$로 transform 됨
- HuBERT-soft는 continuous content feature를 추출하기 위해 사용됨
- HuBERT-soft는 uncertainty를 modeling 하여 content information을 capture 하고 converted speech의 clarity, naturalness를 향상함 - Speaker Encoder는 YAPPT algorithm을 사용하여 audio에서 pitch ($F0$)를 추출하고 speaker-independent pitch information을 encoding 함
- 각 sample의 $F0$는 각 speaker에 대해 normalize 되어 speaker-independent pitch information을 얻음 - VQ-VAE는 vector quantized pitch representation을 추출하는 데 사용됨
- 논문은 timbre modeling capacity를 향상하기 위해 feature fusion module을 도입함
- 이를 위해 model은 speaker feature를 dynamically adjust 하고 content, pitch information을 통해 feature를 flexibly modify 하여 speaker characteristic의 expressiveness를 향상함
- 추가적으로 cross-attention과 gating mechanism은 personalized speaker trait를 capture 하고, multiple attention과 self-attention mechanism은 naturalness를 향상하는 데 사용됨
- 구조적으로 fusion encoder는 다음과 같이 구성됨
- Pitch conv projection layer는 input pitch feature dimension을 $1$에서 $256$으로 transform 함
- 이후 2개의 cross-attention layer는 서로 다른 feature 간의 mutual attention을 facilitate 함
- 이때 각 layer는 $256$ dimension input을 receive 하여 $256$ dimension을 output 함 - Gated fusion module은 $256$-dimensional input의 information fusion effect를 향상함
- Self-attention mechanism은 $256$-dimensional input의 self-attention performance를 iteratively refine 하여 input의 key part에 gradually focusing 함
- Multi-head attention mechanism은 다양한 feature를 학습하고 focus 하는 ability를 강화함
- 이때 $256$-dimensional input/output, $8$ attention head를 사용함
- 논문은 DiffVC를 따라 speaker-independent speech representation으로 average phoneme-level mel feature를 채택함

- Decoder
- Decoder는 Grad-TTS와 같이 U-Net architecture를 기반으로 하고, human voice의 full range를 capture 하기 위해 4배 더 많은 channel을 가짐
- Speaker conditioning network $g_{t}(Y)$는 2D convolution과 MLP layer로 구성됨
- 이때 output은 $128$-dimensional vector로써 $\hat{X}_{t},\bar{X}$의 concatenation과 함께 $128$ channel로 broadcast-concatenate 됨
4. Experiments
- Settings
- Results
- 전체적으로 ReFlow-VC의 성능이 가장 뛰어남

- 2-ReFlow-VC를 사용하면 ReFlow-VC 보다 조금 더 나은 SECS를 달성할 수 있음
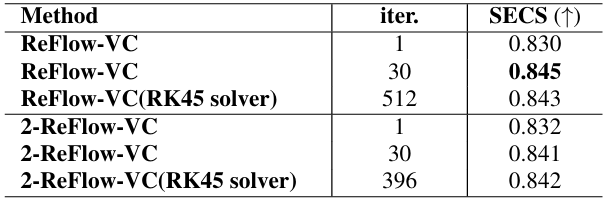
- Rectified Flow는 동일한 sampling step에서 더 빠른 sampling speed를 보임

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글