

티스토리 뷰
Paper/Conversion
[Paper 리뷰] StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
feVeRin 2024. 8. 18. 09:33반응형
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
- Unsupervised non-parallel many-to-many voice conversion을 위해 generative adversarial network를 활용할 수 있음
- StarGANv2-VC
- Adversarial source classifier loss와 perceptual loss를 결합하여 사용
- Style encoder를 통해 plain reading speech를 stylistic speech로 변환
- 논문 (INTERSPEECH 2021) : Paper Link
1. Introduction
- Voice Conversion (VC)는 linguistic content를 preserve 하면서 speaker identity를 다른 speaker로 변환하는 것을 목표로 함
- 최근에는 VC에서 parallel data 뿐만 아니라 non-parallel data도 활용할 수 있도록 AutoEncoder, Text-to-Speech (TTS), Generative Adversarial Network (GAN)을 주로 활용함
- AutoEncoder 방식은 적절한 constraint로 training 하여 speaker-independent information을 encoding 함
- BUT, speaker-dependent information을 제거하기 위해 적절한 constraint가 필요하고, 변환 품질은 latent space에서 다양한 linguistic information을 retrieve 할 수 있는지에 따라 달라짐 - GAN-based 방식은 CycleGAN-VC와 같이 decoder가 target speaker와 비슷한 음성을 생성하도록 유도하는 discriminator를 활용함
- BUT, discriminator가 real data의 meaningful feature를 학습한다는 보장이 없으므로 dissimilarity나 distortion 등이 발생함 - TTS-based 방식은 text label을 통해 input speech에서 aligned linguistic feature를 추출하여 합성을 수행함
- BUT, text label이 포함된 data를 확보하기 까다로움
-> 그래서 non-parallel, unsupervised VC를 지원하는 StarGANv2-VC를 제안
- StarGANv2-VC
- StarGANv2를 기반으로 speaker similarity를 향상하기 위해 adversarial source classifier loss를 도입
- 추가적으로 automatic speech recognition (ASR) network와 fundamental frequency $F0$ extraction network를 사용하여 perceptual loss를 적용
< Overall of StarGANv2-VC >
- StarGANv2를 기반으로 adversarial source loss, perceptual loss를 추가
- 결과적으로 기존보다 뛰어난 conversion 성능을 달성
2. Method
- StarGANv2-VC
- StarGANv2는 single discriminator와 generator를 기반으로 style encoder/mapping network로 얻어지는 domain-specific style vector를 반영하여 각 domain에 해당하는 image를 생성함
- 이때 논문은 각 speaker를 individual domain으로 취급하여 해당 architecture를 VC task에 적용
- $F0$-consistent conversion을 달성하기 위해 pre-trained joint detection and classification (JDC) $F0$ extraction network를 활용
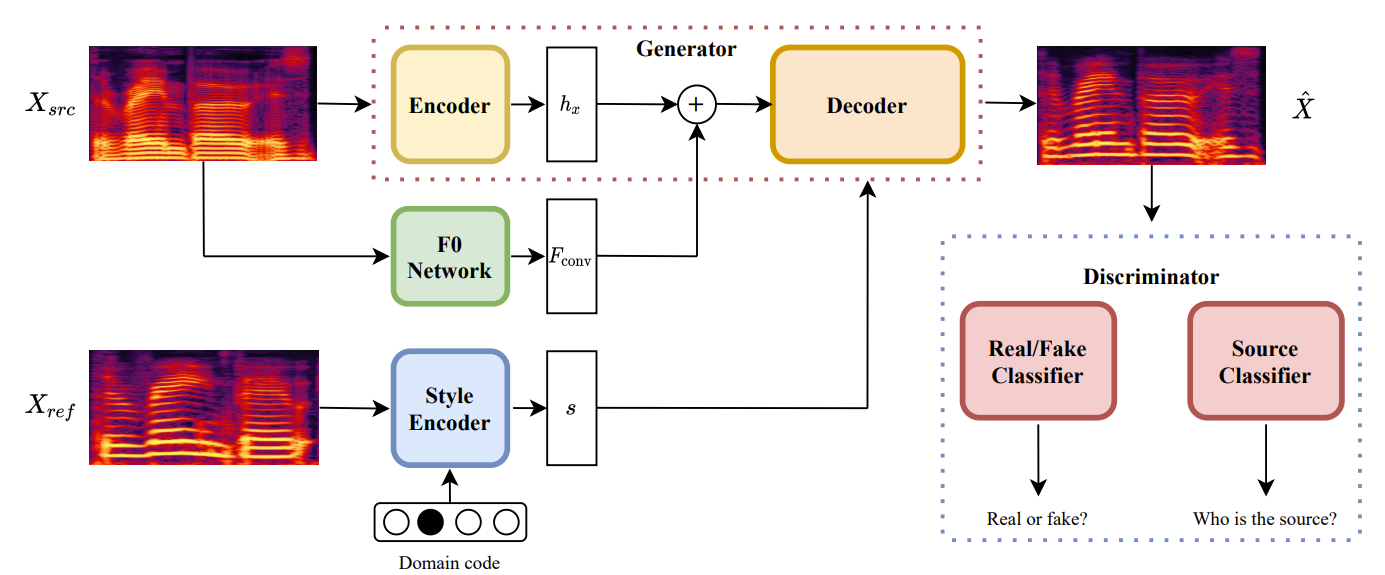
- Generator
- Generator $G$는 input mel-spectrogram $\mathbf{X}_{src}$를 $G(\mathbf{X}_{src}, h_{sty}, h_{f0})$로 변환함
- $h_{sty}$의 style은 mapping network/style encoder로 얻어지고 $h_{f0}$의 fundamental frequency는 $F0$ extraction network $F$로 얻어짐
- $F0$ Network
- $F0$ extraction network $F$는 input mel-spectrogram에서 fundamental frequency를 추출하는 pre-trained JDC network를 사용
- JDC network는 BLSTM unit과 convolutional layer로 구성됨
- 이때 $\mathbf{X}\in\mathcal{X}$에 대한 convolutional output $F_{conv}(\mathbf{X})$만을 input feature로 사용
- Mapping Network
- Mapping network $M$은 domain $y\in\mathcal{Y}$에서 random latent code $\mathbf{z}\in\mathcal{Z}$를 가지는 style vector $h_{M}=M(\mathbf{z},y)$를 생성
- Latent code는 모든 domain에서 다양한 style representation을 제공하기 위해 Gaussian distribution에서 sampling 됨
- 이때 style vector representation은 모든 domain에서 share 되고, domain-specific representation이 shared representation에 적용됨
- Style Encoder
- Reference mel-spectrogram $\mathbf{X}_{ref}$가 주어지면, style encoder $S$는 domain $y\in\mathcal{Y}$에서 style code $h_{sty}=S(\mathbf{X}_{ref},y)$를 추출함
- 이때 mapping network $M$과 유사하게 $S$는 모든 domain에서 shared layer를 통해 input을 처리하고, domain-specific projection을 통해 shared feature를 domain-specific code로 mapping 함
- Discriminators
- Discriminator $D$는 모든 domain에서 real/fake sample 간의 common feature를 학습하는 shared layer를 가지고, 각 domain $y\in\mathcal{Y}$에서 sample을 distinguish 하는 domain-specific binary classifier로 구성됨
- BUT, domain-specific classifier는 single convolution layer로 구성되므로 speaker pronunciation과 같은 domain-specific feature를 capture 하지 못할 수 있음
- 따라서 논문은 $D$와 동일한 architecture를 가지는 additional classifier $C$를 사용하여 converted sample의 original domain을 학습함
- 이를 통해 conversion 이후에 input domain에서 어떤 feature가 elude 되는지를 학습함으로써 generator에는 invariant 하지만 original domain에는 characteristic 한 feedback을 제공
- 결과적으로 generator는 target domain에서 similar sample을 생성하게 됨
- Training Objectives
- StarGANv2-VC는 parallel data 없이 source domain $y_{src}\in\mathcal{Y}$의 sample $\mathbf{X}\in\mathcal{X}_{y_{src}}$을 target domain $y_{trg}\in\mathcal{Y}$의 sample $\hat{\mathbf{X}}\in\mathcal{X}_{y_{trg}}$로 변환하는 mapping $G:\mathcal{X}_{y_{src}}\rightarrow \mathcal{X}_{y_{trg}}$를 학습하는 것을 목표로 함
- Training 중에 StarGANv2-VC는 target domain $y_{trg}\in\mathcal{Y}$와 style code $s\in \mathcal{S}_{y_{trg}}$를 randomly sampling 함
- 여기서 mapping network는 $s=M(\mathbf{z},y_{trg})$이고, Style encoder는 $s=S(\mathbf{X}_{ref},y_{trg})$
- $\mathbf{z}\in\mathcal{Z}$ : latent code, $\mathbf{X}_{ref}\in\mathcal{X}$ : reference input
- 결과적으로 Mel-spectrogram $\mathbf{X}\in\mathcal{X}_{y_{src}}$, source domain $y_{src}\in\mathcal{Y}$, target domain $y_{trg}\in\mathcal{Y}$가 주어지면, StarGANv2-VC는 다음의 loss function을 결합하여 training 됨
- Adversarial Loss
- Generator는 input mel-spectrogram $\mathbf{X}$와 style vector $s$를 input으로 하여 adversarial loss를 통해 새로운 mel-spectrogram $G(\mathbf{X},s)$를 생성하는 방법을 학습함:
(Eq. 1) $\mathcal{L}_{adv}=\mathbb{E}_{\mathbf{X},y_{src}}\left[\log D(\mathbf{X},y_{src})\right]+\mathbb{E}_{\mathbf{X},y_{trg},s}\left[\log (1-D(G(\mathbf{X},s), y_{trg}))\right]$
- $D(\cdot,y)$ : domain $y\in\mathcal{Y}$에 대한 real/fake classifier output
- Generator는 input mel-spectrogram $\mathbf{X}$와 style vector $s$를 input으로 하여 adversarial loss를 통해 새로운 mel-spectrogram $G(\mathbf{X},s)$를 생성하는 방법을 학습함:
- Adversarial Source Classifier Loss
- Source classifier $C$에 대한 additional adversarial loss는:
(Eq. 2) $\mathcal{L}_{advcls}=\mathbb{E}_{\mathbf{X},y_{trg},s}\left[\text{CE}(C(G(\mathbf{X},s)),y_{trg} )\right]$
- $\text{CE}(\cdot)$ : cross-entropy loss
- Source classifier $C$에 대한 additional adversarial loss는:
- Style Reconsturction Loss
- Style reconstruction loss는 생성된 sample로부터 style code를 reconstruct 하도록 보장함:
(Eq. 3) $\mathcal{L}_{sty}=\mathbb{E}_{\mathbf{X},y_{trg},s}\left[|| s-S(G(\mathbf{X},s),y_{trg})||_{1}\right]$
- Style reconstruction loss는 생성된 sample로부터 style code를 reconstruct 하도록 보장함:
- Style Diversification Loss
- Style diversification loss는 generator가 다른 style code로 다양한 sample을 생성하도록 함
- 이를 위해 생성된 sample 간의 Mean Absolute Error (MAE)와 서로 다른 code로 생성된 sample 간의 $F0$ feature의 MAE를 최대화:
(Eq. 4) $\mathcal{L}_{ds}=\mathbb{E}_{\mathbf{X},s_{1},s_{2},y_{trg}}\left[|| G(\mathbf{X},s_{1})-G(\mathbf{X},s_{2})||_{1}\right]+\mathbb{E}_{\mathbf{X},s_{1},s_{2},y_{trg}}\left[ || F_{conv}(G(\mathbf{X},s_{1}))-F_{conv}(G(\mathbf{X},s_{2})) ||_{1}\right]$
- $s_{1}, s_{2}\in\mathcal{S}_{y_{trg}}$ : domain $y_{trg}\in\mathcal{Y}$에서 randomly sample 된 style code
- $F_{conv}(\cdot)$ : $F0$ network $F$의 convolutional layer output
- $F0$ Consistency Loss
- $F0$-consistent result를 얻기 위해, $F0$ network $F$에서 제공하는 normalized $F0$ curve에 대해 $F0$-consistency loss를 적용함
- Input mel-spectrogram $\mathbf{X}$의 경우, $F(\mathbf{X})$는 $\mathbf{X}$의 각 frame에 대한 absolute $F0$ value를 Hz로 제공
- Male/female speaker는 average $F0$가 다르므로, absolute $F0$ value $F(\mathbf{X})$를 temporal mean $\hat{F}(\mathbf{X})=\frac{F(\mathbf{X})}{|| F(\mathbf{X})||_{1}}$으로 제공 - 그러면 $F0$ consistency loss는:
(Eq. 5) $\mathcal{L}_{f0}=\mathbb{E}_{\mathbf{X},s}\left[|| \hat{F}(\mathbf{X})-\hat{F}(G(\mathbf{X},s))||_{1}\right]$
- $F0$-consistent result를 얻기 위해, $F0$ network $F$에서 제공하는 normalized $F0$ curve에 대해 $F0$-consistency loss를 적용함
- Speech Consistency Loss
- Converted speech가 source와 동일한 linguistic content를 가지도록 pre-trained joint CTC-attention VGG-BLSTM network의 convolutional feature를 사용한 speech consistency loss를 적용
- 이때 LSTM layer 이전의 intermediate layer output을 linguistic feature $h_{asr}(\cdot)$으로 사용 - 그러면 speech consistency loss는:
(Eq. 6) $\mathcal{L}_{asr}=\mathbb{E}_{\mathbf{X},s}\left[|| h_{asr}(\mathbf{X})-h_{asr}(G(\mathbf{X},s))||_{1}\right]$
- Converted speech가 source와 동일한 linguistic content를 가지도록 pre-trained joint CTC-attention VGG-BLSTM network의 convolutional feature를 사용한 speech consistency loss를 적용
- Norm Consistency Loss
- 생성된 sample의 speech/silence interval을 preserve 하기 위해 norm consistency loss를 도입
- 이를 위해 $t$-th frame에서 $N$ mel과 $T$ frame을 가지는 mel-spectrogram $\mathbf{X}$에 대한 absolute column-sum norm $||\mathbf{X}_{\cdot, t}||=\sum_{n=1}^{N}| \mathbf{X}_{n,t}|$을 사용
- $t\in\{1,...,T\}$ : frame index - 결과적으로 얻어지는 norm consistency loss는:
(Eq. 7) $\mathcal{L}_{norm}=\mathbb{E}_{\mathbf{X},s}\left[\frac{1}{T} \sum_{t=1}^{T}\left|\, || \mathbf{X}_{\cdot,t}||- ||G(\mathbf{X},s)_{\cdot,t} ||\,\right|\right]$
- Cycle Consistency Loss
- Input의 다른 feature를 preserve 하기 위해 cycle consistency loss를 활용:
(Eq. 8) $\mathcal{L}_{cyc}=\mathbb{E}_{\mathbf{X},y_{src},y_{trg},s}\left[|| \mathbf{X}-G(G(\mathbf{X},s),\tilde{s})||_{1}\right]$
- $\tilde{s}=S(\mathbf{X},y_{src})$ : source domain $y_{src}\in\mathcal{Y}$에서 input의 estimated style code
- Input의 다른 feature를 preserve 하기 위해 cycle consistency loss를 활용:
- Full Objective
- 최종적으로 얻어지는 total generator obejctive는:
(Eq. 9) $\min_{G,S,M}\mathcal{L}_{adv}+\lambda_{advcls}\mathcal{L}_{advcls}+\lambda_{sty}\mathcal{L}_{sty}-\lambda_{ds}\mathcal{L}_{ds}+\lambda_{f0}\mathcal{L}_{f0}+\lambda_{asr}\mathcal{L}_{asr}+\lambda_{norm}\mathcal{L}_{norm}+\lambda_{cyc}\mathcal{L}_{cyc}$
- $\lambda_{advcls}, \lambda_{sty},\lambda_{ds}, \lambda_{f0},\lambda_{asr},\lambda_{norm},\lambda_{cyc}$ : hyperparameter - Total discriminator obejctive는:
(Eq. 10) $\min_{C,D}-\mathcal{L}_{adv}+\lambda_{cls}\mathcal{L}_{cls}$
- $\lambda_{cls}$ : hyperparameter - 여기서 source classifier loss $\mathcal{L}_{cls}$는:
(Eq. 11) $\mathcal{L}_{cls}=\mathbb{E}_{\mathbf{X},y_{src},s}\left[ \text{CE}(C(G(\mathbf{X},s)), y_{src})\right]$
- 최종적으로 얻어지는 total generator obejctive는:
- Adversarial Loss

3. Experiments
- Settings
- Dataset : VCTK, JVS, ESD
- Comparisons : AutoVC
- Results
- 전체적으로 StarGANv2-VC가 가장 우수한 성능을 보임

- Ablation study 측면에서 각 loss term을 제거하는 경우, 성능 저하가 발생함

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글