

티스토리 뷰
Paper/Conversion
[Paper 리뷰] FasterVoiceGrad: Faster One-Step Diffusion-based Voice Conversion with Adversarial Diffusion Conversion Distillation
feVeRin 2025. 8. 24. 08:25반응형
FasterVoiceGrad: Faster One-Step Diffusion-based Voice Conversion with Adversarial Diffusion Conversion Distillation
- Diffusion-based Voice Conversion model은 iterative sampling으로 인해 상당히 느림
- FasterVoiceGrad
- Adversarial Diffusion Conversion Distillation을 통해 diffusion model과 content encoder를 distill
- 특히 효과적인 distillation을 위해 adversarial distillation, score distillation training을 활용
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Voice Conversion (VC)는 linguistic content를 preserve 하면서 다른 voice로 convert 하는 것을 목표로 함
- 특히 diffusion-based non-parallel VC model은 뛰어난 speaker similarity를 달성할 수 있지만, iterative sampling으로 인한 slow conversion 문제가 있음
- 이를 해결하기 위해 FastVoiceGrad는 multi-step VoiceGrad를 one-step diffusion-based VC model로 distill 함
- 특히 adversarial training과 score distillation training을 활용하여 sampling step을 reduce 함
- BUT, 해당 cost reduction은 reverse diffusion process에 한정되어 있고, content encoder의 computational cost를 고려하지 않음
- Straightforward solution으로 original content encoder를 faster module로 replace 하는 것을 고려할 수 있지만, training 과정에서 identity mapping을 학습하여 input을 그대로 output 할 수 있음
-> 그래서 reverse process와 content encoder를 simultaneously distill 한 FasterVoiceGrad를 제안
- FasterVoiceGrad
- Reverse diffusion process와 content encoder를 Adversarial Diffusion Conversion Distillation (ADCD)를 통해 simultaneously distilling
- 추가적으로 content preservation을 위한 reconversion score distillation과 speaker emphasis를 위한 inverse score distillation을 도입
< Overall of FasterVoiceGrad >
- FastVoiceGrad에 ADCD를 적용한 one-step VC model
- 결과적으로 기존보다 우수한 성능을 달성
2. Preliminary: VoiceGrad/FastVoiceGrad
- VoiceGrad
- VoiceGrad는 Denoising Diffusion Probabilistic Model (DDPM)을 기반으로 한 non-parallel VC model임
- VoiceGrad는 conversion target으로 mel-spectrogram $\mathbf{x}$를 사용하고, speaker embedding $\mathbf{s}$, content embedding $\mathbf{p}$를 기반으로 conversion을 수행함
- Conversion process에서 $\mathbf{x},\mathbf{p}$는 source speaker $src$로부터 추출되고, $\mathbf{s}$는 target speaker $tgt$로부터 추출되어 speaker characteristic을 convert 함 - Diffusion Process
- 먼저 input mel-spectrogram $\mathbf{x}_{0} \,\, (=\mathbf{x})$는 $T$ step을 따라 noise $\mathbf{x}_{T}\sim \mathcal{N}(0,I)$로 transform 됨
- Normal distribution의 reproductivity와 reparameterization trick을 활용하여, $t$-step diffused data $\mathbf{x}_{t}\,\,\,(t\in \{1,...,T\})$는 다음과 같이 얻어짐:
(Eq. 1) $ \mathbf{x}_{t}=\sqrt{\bar{\alpha}_{t}}\mathbf{x}_{0}+\sqrt{1-\bar{\alpha}_{t}}\epsilon$
- $\bar{\alpha}_{t}=\prod_{i=1}^{t}\alpha_{i}$, $1-\alpha_{i}$ : $i$-th step의 noise variance, $\epsilon\sim \mathcal{N}(0,I)$
- Reverse Diffusion Process
- Reverse process에서 $\mathbf{x}_{T}$는 $\mathbf{x}_{0}$으로 gradually denoise 됨
- 각 reverse diffusion step의 denoising process는:
(Eq. 2) $\mu_{\theta}(\mathbf{x}_{t},t,\mathbf{s},\mathbf{p})=\frac{1}{\sqrt{\alpha_{t}}} \left(\mathbf{x}_{t}-\frac{1-\alpha_{t}}{\sqrt{1-\bar{\alpha}_{t}}}\epsilon_{\theta} (\mathbf{x}_{t},t,\mathbf{s},\mathbf{p})\right)$
- $\epsilon_{\theta}$ : parameter $\theta$를 가지는 denoising function - 해당 process는 $\mathbf{s}^{src}, \mathbf{p}^{src}$를 기반으로 수행되고, conversion 시에는 $\mathbf{s}^{tgt}, \mathbf{p}^{src}$를 사용함
- Training Objective
- $\epsilon_{\theta}$는 diffusion process의 noise를 reconstruct 하기 위해 다음의 objective로 optimize 됨:
(Eq. 3) $\mathcal{L}_{DDPM}(\theta)=\mathbb{E}_{\mathbf{x}_{0}^{src},t,\epsilon} \left[\left|\left| \epsilon-\epsilon_{\theta}\left( \mathbf{x}_{t}^{src},t,\mathbf{s}^{src}, \mathbf{p}^{src} \right)\right|\right|_{1}\right]$
- $\epsilon_{\theta}$는 diffusion process의 noise를 reconstruct 하기 위해 다음의 objective로 optimize 됨:
- VoiceGrad는 conversion target으로 mel-spectrogram $\mathbf{x}$를 사용하고, speaker embedding $\mathbf{s}$, content embedding $\mathbf{p}$를 기반으로 conversion을 수행함
- FastVoiceGrad
- FastVoiceGrad는 adversarial loss, score distillation loss를 사용하여 VoiceGrad를 one-step diffusion-based VC model로 distillation 함
- $\theta, \phi$를 각각 teacher, student model parameter라고 했을 때, FastVoiceGrad는 reconstruction process에서 distillation을 수행함
- Adversarial Loss
- FastVoiceGrad의 adversarial loss는:
(Eq. 4) $\mathcal{L}_{adv}(\psi)=\mathbb{E}_{\mathbf{x}_{0}^{src}}\left[\left( \mathcal{D}\left( \mathcal{V}\left(\mathbf{x}_{0}^{src}\right)\right)-1\right)^{2}+\left(\mathcal{D}\left(\mathcal{V} \left(\mathbf{x}_{\phi}^{rec}\right)\right)\right)^{2}\right]$
(Eq. 5) $\mathcal{L}_{adv}(\phi)=\mathbb{E}_{\mathbf{x}_{0}^{src}}\left[ \left(\mathcal{D} \left(\mathcal{V}\left(\mathbf{x}_{\phi}^{rec}\right)\right)-1\right)^{2}\right]$
- $\mathcal{D}$ : parameter $\psi$를 가지는 discriminator, $\mathcal{V}$ : vocoder
- $\mathbf{x}_{\phi}^{rec}=\mu_{\phi}(\mathbf{x}_{t'}^{src},t',\mathbf{s}^{src}, \mathbf{p}^{src})$ : student model $\mu_{\phi}$를 통해 얻어지는 one-step reverse diffusion result
- $\mathbf{x}_{t'}^{src}$ : $t'$-step diffused $\mathbf{x}_{0}^{src}$, $\mu_{\phi}$ : (Eq. 2)로 calculate 됨 - 특히 해당 formulation은 $\mathbf{x}_{\phi}^{rec}$를 얻기 위해 time-domain에서 adversarial training을 수행함
- GAN training을 stabilize 하기 위해 feature matching loss $\mathcal{L}_{FM}(\phi)$가 $\mathbf{x}_{\phi}^{rec},\mathbf{x}_{0}$에 적용됨
- FastVoiceGrad의 adversarial loss는:
- Score Distillation Loss
- Score distillation loss는 다음과 같음:
(Eq. 6) $\mathcal{L}_{dist}(\phi)=\mathbb{E}_{\mathbf{x}_{0}^{src},t}\left[ \sqrt{\bar{\alpha}_{t}}\left|\left| \mathbf{x}_{\phi}^{rec}-\mathbf{x}_{\theta}^{rec}\right|\right|_{1}\right]$
- $\mathbf{x}_{\theta}^{rec}=\mu_{\theta}(\text{sg}(\mathbf{x}_{\phi,t}^{rec}),t, \mathbf{s}^{src},\mathbf{p}^{src})$ : teacher model $\mu_{\theta}$를 통해 $\mathbf{x}_{\phi}^{rec}$를 reversely diffusing 하여 얻어짐
- $\text{sg}$ : stop-gradient, $\mathbf{x}_{\phi,t}^{src}$ : $t$-step diffused $\mathbf{x}_{\phi}^{rec}\,\, (t\in \{1,...,T\})$ - 해당 loss는 $\mathbf{x}_{\phi}^{rec}$가 teacher model $\mu_{\theta}$에 의해 denoise 된 data와 match 하도록 encourage 함
- Score distillation loss는 다음과 같음:
3. FasterVoiceGrad
- FasterVoiceGrad는 reverse diffusion module과 content encoder를 distill 하여 conversion을 speed up 함
- 구조적으로는 FastVoiceGrad의 computationally intensive Conformer-based content encoder를 training 중에 freeze 하고 trainable, computationally efficient CNN $\mathbf{p}_{\phi}$로 replace 함
- 이때 기존 reconstruction distillation은 다음의 이유로 사용할 수 없음
- Content encoder가 trainable 한 경우, $\mathbf{x}$는 content encoder path $\mathbf{x}_{0}^{src}\rightarrow \mathbf{p}_{\phi}^{src}\rightarrow \mathbf{x}_{\phi}^{rec}$를 통해 reconstruct 됨
- 따라서 reverse diffusion process $\mathbf{x}_{t'}^{src}\rightarrow \mu_{\phi}\rightarrow \mathbf{x}_{\phi}^{rec}$는 ignore 됨
- 이를 해결하기 위해, FasterVoiceGrad는 Adversarial Diffusion Conversion Distillation (ADCD)를 도입함
- 구조적으로는 FastVoiceGrad의 computationally intensive Conformer-based content encoder를 training 중에 freeze 하고 trainable, computationally efficient CNN $\mathbf{p}_{\phi}$로 replace 함

- Extension from Reconstruction to Conversion
- Conversion Adversarial Loss
- Reverse diffusion module $\mu_{\phi}$는 reconstruction 대신 conversion을 수행하고, $\mathbf{x}_{\phi}^{cv}=\mu_{\phi}(\mathbf{x}_{t'},t',\mathbf{s}^{tgt},\mathbf{p}_{\phi}^{src})$를 생성함
- $\mathbf{s}^{tgt}$는 $\mathbf{s}^{src}$ 대신 input speaker embedding으로 사용됨 - 그러면 (Eq. 4), (Eq. 5)는 다음과 같이 replace 됨:
(Eq. 7) $\mathcal{L}_{adv}^{cv}(\psi)=\mathbb{E}_{\mathbf{x}_{0}^{src}}\left[\left( \mathcal{D}\left(\mathcal{V}\left(\mathbf{x}_{0}^{src}\right)\right)-1\right)^{2}+ \left(\mathcal{D}\left(\mathcal{V}\left(\mathbf{x}_{\phi}^{cv}\right)\right)\right)^{2}\right]$
(Eq. 8) $\mathcal{L}_{adv}^{cv}(\phi)=\mathbb{E}_{\mathbf{x}_{0}^{src}}\left[\left(\mathcal{D}\left( \mathcal{V}\left( \mathbf{x}_{\phi}^{cv}\right)\right)-1\right)^{2}\right]$
- 추가적으로 논문은 feature matching loss $\mathcal{L}_{FM}(\phi)$를 적용함
- Reverse diffusion module $\mu_{\phi}$는 reconstruction 대신 conversion을 수행하고, $\mathbf{x}_{\phi}^{cv}=\mu_{\phi}(\mathbf{x}_{t'},t',\mathbf{s}^{tgt},\mathbf{p}_{\phi}^{src})$를 생성함
- Conversion Score Distillation Loss
- 마찬가지로 (Eq. 6)의 score distillation loss는 다음과 같이 replace 됨:
(Eq. 9) $\mathcal{L}_{dist}^{cv}(\phi)=\mathbb{E}_{\mathbf{x}_{0}^{src},t}\left[\sqrt{\bar{\alpha}_{t}}\left|\left| \mathbf{x}_{\phi}^{cv}-\mathbf{x}_{\theta}^{cv}\right|\right|_{1}\right]$
- $\mathbf{x}_{\theta}^{cv}=\mu_{\theta}(\text{sg}(\mathbf{x}_{\phi,t}^{cv}),t,\mathbf{s}^{tgt},\mathbf{p}^{src})$ : $\mathbf{s}^{tgt},\mathbf{p}^{src}$, $t$-step diffused $\mathbf{x}^{cv}_{\phi}$에 대한 teacher model $\mu_{\theta}$를 통해 $\mathbf{x}_{\phi}^{cv}$를 diffuse/reversely diffuse 하여 얻어짐
- 마찬가지로 (Eq. 6)의 score distillation loss는 다음과 같이 replace 됨:
- Content Preservation by Reconversion Score Distillation
- $\mathbf{x}_{\phi}^{cv}$의 content preservation을 향상하기 위해, 논문은 conversion을 다시 수행하고 twice-converted mel-spectrogram $\mathbf{x}_{\phi}^{cv2}=\mu_{\phi}(\mathbf{x}_{\phi,t'}^{cv},t',\mathbf{s}^{tgt2},\mathbf{p}_{\phi}^{cv})$에 score distillation loss를 적용함
- 여기서 $\mathbf{x}^{cv}_{\phi,t'}$은 $t'$-step diffused $\mathbf{x}_{\phi}^{cv}$, $\mathbf{s}^{tgt2}$는 second conversion을 위한 speaker embedding, $\mathbf{p}_{\phi}^{cv}$는 $\mathbf{x}_{\phi}^{cv}$에서 추출된 content embedding을 의미함
- 결과적으로 $\mathbf{x}_{\phi}^{cv2}$에 대한 score distillation loss는:
(Eq. 10) $\mathcal{L}_{dist}^{cv2}(\phi)=\mathbb{E}_{\mathbf{x}_{0}^{src},t}\left[ \sqrt{\bar{\alpha}_{t}}\left|\left| \mathbf{x}^{cv2}_{\phi}-\mathbf{x}_{\theta}^{cv2}\right|\right|_{1}\right]$
- $\mathbf{x}_{\theta}^{cv2}=\mu_{\theta}(\text{sg}(\mathbf{x}_{\phi,t}^{cv2}), t, \mathbf{s}^{tgt2},\mathbf{p}^{src})$ : $t$-step diffused $\mathbf{x}_{\phi}^{cv2}, \mathbf{s}^{tgt}, \mathbf{p}^{src}$에 대한 teacher model $\mu_{\theta}$를 통해 $\mathbf{x}_{\phi}^{cv2}$를 diffuse/reversely diffuse 하여 얻어짐

- Speaker Emphasis by Inverse Score Distillation
- Speaker identity 향상하기 위해, 논문은 $\mathcal{L}_{dist}^{cv}(\phi)$를 사용하여 converted mel-spectrogram $\mathbf{x}_{\phi}^{cv}$가 target mel-spectrogram와 close 하면서 다른 speaker와는 멀어지도록 함
- 해당 inverse score distillation loss는:
(Eq. 11) $\mathcal{L}_{inv\text{-}dist}^{cv}(\phi)=-\mathbb{E}_{\mathbf{x}_{0}^{src},t} \left[\sqrt{\bar{\alpha}_{t}}\left|\left| \mathbf{x}_{\phi}^{cv}-\mathbf{x}_{\theta}^{inv}\right|\right|_{1}\right]$
- $\mathbf{x}_{\theta}^{inv}=\mu_{\theta}(\text{sg}(\mathbf{x}_{\phi,t}^{cv}),t, \mathbf{s}^{inv},\mathbf{p}^{src})$ : other speaker embedding $\mathbf{s}^{inv}$, $\mathbf{p}^{src}$에 대한 teacher model $\mu_{\theta}$를 통해 $\mathbf{x}_{\phi}^{cv}$를 diffuse/reversely diffuse 하여 얻어짐 - Reconversion이 적용된 경우, 유사한 loss $\mathcal{L}_{inv\text{-}dist}^{cv2}$가 reconverted mel-spectrogram $\mathbf{x}_{\phi}^{cv2}$에 적용됨
- 결과적으로 얻어지는 total loss는:
(Eq. 12) $\mathcal{L}_{ADCD}(\phi)=\mathcal{L}_{adv}^{cv}(\phi) +\lambda_{FM}\mathcal{L}_{FM}(\phi) +\lambda_{dist}\mathcal{L}_{dist}^{cv}(\phi)+\lambda_{inv\text{-}dist}(\phi)\mathcal{L}_{inv\text{-}dist}^{cv}(\phi)$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, +\lambda_{dist}\mathcal{L}_{dist}^{cv2}(\phi) +\lambda_{inv\text{-}dist}\mathcal{L}_{inv\text{-}dist}^{cv2}(\phi)$
(Eq. 13) $\mathcal{L}_{ADCD}(\psi)=\mathcal{L}_{adv}^{cv}(\psi)$
- $\lambda_{FM}=2,\lambda_{dist}=45,\lambda_{inv\text{-}dist}=22.5$ : weighting hyperparameter - $\phi,\psi$는 각각 $\mathcal{L}_{ADCD}(\phi), \mathcal{L}_{ADCD}(\psi)$를 optimize 하여 얻어짐
- 해당 inverse score distillation loss는:

4. Experiments
- Settings
- Dataset : VCTK
- Comparisons : FastVoiceGrad
- Results
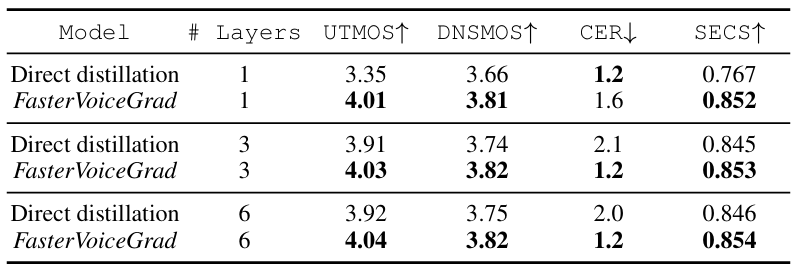
- 전체적으로 FasterVoiceGrad의 성능이 더 우수함

- MOS 측면에서도 더 나은 성능을 보임

- LibriTTS dataset에 대해서도 뛰어난 generalability를 보임

- Model Analysis
- 각 component는 성능 향상에 유효함

- Direct distillation과 비교하여 FasterVoiceGrad training이 더 효과적임
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글