

티스토리 뷰
Paper/Conversion
[Paper 리뷰] DDDM-VC: Decoupled Denoising Diffusion Models with Disentangled Representation and Prior Mixup for Verified Robust Voice Conversion
feVeRin 2024. 10. 6. 11:13반응형
DDDM-VC: Decoupled Denoising Diffusion Models with Disentangled Representation and Prior Mixup for Verified Robust Voice Conversion
- Diffusion-based model은 data distribution에 많은 attribute가 존재하고 generation process에서 model parameter sharing에 대한 한계로 인해 각 attribute에 대한 specific style control이 어려움
- DDDM-VC
- Decoupled Denoising Diffusion Model을 도입하여 각 attribute에 대한 style transfer를 지원
- 특히 voice conversion task에서 linguistic information, intonation, timbre와 같은 speech attribute를 disentangling 하고 individually transferring 함 - 이를 위해 self-supervised representation을 통해 speech representation을 disentangle 하고, Decoupled Denoising Diffusion Model을 사용하여 disentangled representation으로부터 resynthesize를 수행
- 추가적으로 mixed style의 converted representation을 prior distribution으로 사용하는 Prior Mixup을 도입
- Decoupled Denoising Diffusion Model을 도입하여 각 attribute에 대한 style transfer를 지원
- 논문 (AAAI 2024) : Paper Link
1. Introduction
- Denoising Diffusion Probabilistic Model은 뛰어난 generation ability를 가지고 있음
- BUT, speech data에는 다양한 attribute가 포함되어 있으므로 all-level generation process에서 model parameter를 share 하는 single denoiser로는 각 attribute에 대한 specific style을 control 하기 어려움
- 이를 위해 imgae generation에서는 eDiff-i와 같이 single denoiser를 specific iterative step에 따라 점진적으로 multiple specialized denoiser로 subdivide 하는 방식을 사용함
- BUT, iteration에 대해 동일한 conditioning framework 내에서 각 attribute를 control 하는 것에는 한계가 있음 - 특히 voice conversion (VC)은 linguistic information을 유지하면서 voice style을 control 해야 하고, linguistic information, intonation, timbre 등의 다양한 attribute로 구성되어 있으므로 효과적인 disentangling이 필요함
-> 그래서 Decoupled Denoising Diffusion Model (DDDM)에 기반한 VC model인 DDDM-VC를 제안
- DDDM-VC
- Denoiser를 specific attribute-conditioned denoiser로 disentangle 하여 각 attribute에 대한 model controllability를 개선
- 여기서 각 denoiser는 동일한 noise level에서 own attribute noise에 focus 하고, 각 intermediate time step에서 noise를 제거함 - 이를 위해 self-supervised representation을 통해 source-filter theory에 기반한 speech representation을 disentangling 하고, DDDM을 활용하여 disentangle representation으로부터 각 attribute에 대한 speech를 resynthesize
- 추가적으로 converted speech를 mixed speech representation에서 생성된 diffusion model에 대한 prior distribution으로 사용하고 source speech를 restore 하는 voice style transfer training scenario인 Prior Mixup을 도입
- Denoiser를 specific attribute-conditioned denoiser로 disentangle 하여 각 attribute에 대한 model controllability를 개선
< Overall of DDDM-VC >
- 각 attribute의 style을 효과적으로 control 하기 위해, attribute를 decoupling 하는 DDDM을 채택
- 추가적으로 Prior Mixup을 도입하여 voice style transfer 성능을 향상
- 결과적으로 기존보다 뛰어난 conversion 성능을 달성
2. Background
- Denoising Diffusion Model은 일반적으로 random noise를 점진적으로 추가하는 forward process와 random noise를 제거하여 original sample을 restore 하는 reverse process로 구성됨
- 이때 Markov chain에 기반한 discrete-time diffusion process 대신 Stochastic Differential Equation (SDE) 기반의 continuous-time diffusion process를 사용하는 Score-based model을 채택할 수 있음
- 그러면 stochastic forward process는:
(Eq. 1) $d\mathbf{x}=f(\mathbf{x},t)dt+g(t)d\mathbf{w}$
- $f(.,t)$ : $\mathbf{x}(t)$의 drift coefficient, $g(t)$ : diffusion coefficient, $\mathbf{w}$ : Brownian motion - Reverse-time SDE는:
(Eq. 2) $d\mathbf{x}=\left[f(\mathbf{x},t)-g^{2}(t)\nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})\right]dt+g(t)d\bar{\mathbf{w}}$
- $\bar{\mathbf{w}}$ : backward-time Brownian motion, $\nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})$ : score function
- 그러면 stochastic forward process는:
- 결과적으로 $s_{\theta}(\mathbf{x},t)\simeq \nabla_{\mathbf{x}}\log p_{t}(\mathbf{x})$를 추정하기 위해 score-based diffusion model은 다음의 score-matching objective로 training 됨:
(Eq. 3) $\theta^{*}=\arg\min_{\theta}\mathbb{E}_{t}\left\{\lambda(t)\mathbb{E}_{\mathbf{x}(0)}\mathbb{E}_{\mathbf{x}(t)|\mathbf{x}(0)}\left[ \left|\left| s_{\theta}(\mathbf{x}(t),t)-\nabla_{\mathbf{x}(t)}\log p_{0t}(\mathbf{x}(t)|\mathbf{x}(0))\right|\right|_{2}^{2}\right] \right\}$
- 이때 Markov chain에 기반한 discrete-time diffusion process 대신 Stochastic Differential Equation (SDE) 기반의 continuous-time diffusion process를 사용하는 Score-based model을 채택할 수 있음
- Diffusion vs. GAN
- 한편으로 Avocodo와 같이 speech domain에서 Generative Adversarial Network (GAN)를 활용할 수도 있음
- BUT, GAN은 fidelity와 diversity 간의 trade-off로 인해 entire distribution을 covering 하지 못함
- 실제로 아래 표와 같이 동일한 encoder를 사용하여 성능을 비교해 보면, diffusion-based VC model이 GAN-based VC model 보다 더 나은 speaker adaptation 성능을 보임
- 따라서 논문은 diffusion-based VC model인 DiffVC를 baseline으로 채택하여 사용함

3. Decoupled Denoising Diffusion Models
- Generative model에서 각 attribute에 대한 style을 효과적으로 control 하기 위해, 논문은 multiple disentangled denoiser를 가지는 Decoupled Denoising Diffusion Model (DDDM)을 도입함
- 구체적으로 임의의 주어진 point에서 하나 이상의 attribute denoiser가 사용됨
- 즉, single denoiser를 사용하는 일반적인 diffusion process와 달리, DDDM은 denoiser를 disentangled representation을 가지는 $N$개의 denoiser로 subdivide 함 - 이때 DiffVC의 data-driven prior를 따라, 각 attribute denoiser의 prior로 attribute $Z_{n}$의 disentangled representation을 사용함
- 그러면 DDDM의 forward process는:
(Eq. 4) $dX_{n,t}=\frac{1}{2}\beta_{t}(Z_{n}-X_{n,t})dt+\sqrt{\beta_{t}}dW_{t}$
- $n\in [1,N]$, $n$ : 각 attribute, $N$ : attribute 수
- $\beta_{t}$ : stochastic noise를 regulate 하는 역할, $W_{t}$ : forward Brownian motion - 각 attribute에 대해 (Eq. 4)의 forward SDE에 대한 reverse trajectory가 존재하고, 각 disentangled denoiser의 reverse process는:
(Eq. 5) $d\hat{X}_{n,t}=\left(\frac{1}{2}(Z_{n}-\hat{X}_{n,t})-\sum_{n=1}^{N}s_{\theta_{n}} (\hat{X}_{n,t},Z_{n},t)\right)\beta_{t}dt+\sqrt{\beta_{t}}d\bar{W}_{t}$
- $t\in [0,1]$, $s_{\theta_{n}}$ : 각 attribute $n$에 대해 $\theta_{n}$으로 parameterize 된 score function
- $\bar{W}_{t}$ : backward Brownian motion - 여기서 각 prior attribute $n$을 가지는 noisy sample $X_{n,t}$를 생성하려면:
(Eq. 6) $p_{0t}(X_{n,t}|X_{0})=\mathcal{N}\left(e^{-\frac{1}{2}\int_{0}^{t}\beta_{s}ds}X_{0} +\left(1-e^{-\frac{1}{2}\int_{0}^{t}\beta_{s}ds}\right)Z_{n}, \left(1-e^{-\int_{0}^{t}\beta_{s}ds}\right)I\right)$
- $I$ : identity matrix - (Eq. 6)의 distribution은 Gaussian이므로, 다음을 얻을 수 있음:
(Eq. 7) $\nabla\log p_{0t}(X_{n,t}|X_{0})=-\frac{X_{n,t}- X_{0}\left(e^{-\frac{1}{2}\int_{0}^{t}\beta_{s}ds}\right)-Z_{n}\left(1-e^{-\frac{1}{2}\int_{0}^{t}\beta_{s}ds}\right)}{1-e^{-\int_{0}^{t}\beta_{s}ds}}$ - (Eq. 5)의 reverse process는 parameter $\theta_{n}$을 사용하여 다음의 objective를 통해 최적화됨:
(Eq. 8) $\theta_{n}^{*}=\arg\min_{\theta_{n}}\int_{0}^{1}\lambda_{t}\mathbb{E}_{X_{0}, X_{n,t}}\left|\left| s_{\theta_{n}}(X_{n,t},Z_{n},t)-\nabla\log p_{0t}(X_{n,t}|X_{0})\right|\right|_{2}^{2}dt$
- $\theta=[\theta_{1},...,\theta_{N}]$, $\lambda_{t}=1-e^{-\int_{0}^{t}\beta_{s}ds}$
- 그러면 DDDM의 forward process는:
- 추가적으로 DDDM-VC는 reverse SDE solver로 forward diffusion의 log-likelihood를 최대화하는 ML-SDE solver를 사용하여 fast sampling을 유도함
- 구체적으로 임의의 주어진 point에서 하나 이상의 attribute denoiser가 사용됨

4. DDDM-VC
- DDDM-VC는 전체적으로 source-filter encoder와 source-filter decoder로 구성됨

- Speech Disentanglement
- Content Representation
- Phonetic information과 관련된 content representation을 추출하기 위해 DDDM-VC는 self-supervised speech representation을 사용함
- 이때 robust zero-shot cross-lingual VC를 위해 large-scale cross-lingual speech dataset으로 train 된 Wav2Vec 2.0인 XLS-R의 continuous representation을 채택
- 추가적으로 filter encoder에 전달하기 전에 audio를 perturbe 하여 content-independent information을 제거함 - 결과적으로 XLS-R의 middle layer에는 substantial linguistic information이 포함되어 있으므로 해당 representation을 content representation으로 채택함
- Pitch Representation
- YAPPT algorithm을 사용하여 audio에서 fundamental frequency $F0$를 추출한 다음, speaker-irrelevant speaking style을 encode 함
- 각 sample의 $F0$는 speaker-independent pitch information을 위해 각 speaker에 대해 normalize 되고, VQ-VAE는 vector-quantized pitch representation을 추출하는 데 사용됨
- 추론 시에는 speaker가 아닌 각 sentence에 대해 $F0$를 normalize 함
- Speaker Representation
- Meta-StyleSpeech의 style encoder를 사용하여 mel-spectrogram에서 target speaker representation을 추출함
- 추출된 speaker representation은 global speaker representation을 위해 sentence 마다 평균되고, speaker adaptation을 위해 모든 encoder/decoder에 전달됨
- Speech Resynthesis
- Source-Filter Encoder
- DDDM-VC는 source-filter theory를 따라 speech attribute를 정의함
- 여기서 fitler encoder는 content와 speaker representation을 input으로 하고 source encoder는 pitch, speaker rperesentation을 input으로 함 - PriorGrad, DiffVC 등에서 사용된 data-driven piror는 phoneme-level average mel-spectrogram을 추출하기 위해 text transcript가 필요하고, smoothed mel-spectrogram으로 인해 mispronunciation이 발생한다는 단점이 있음
- 따라서 DDDM-VC에서는 detailed piror를 얻기 위해, mel-spectrogram $X_{mel}$에 의해 regularize 된 entirely reconstructed source $Z_{src}$와 mel-sepctrogram $Z_{ftr}$을 사용함:
(Eq. 9) $\mathcal{L}_{rec}=||X_{mel}-(Z_{src}+Z_{ftr})||_{1}$ - 여기서:
(Eq. 10) $Z_{src}=E_{src}(\text{pitch}, s),\,\,\, Z_{ftr}=E_{ftr}(\text{content}, s)$
- 따라서 DDDM-VC에서는 detailed piror를 얻기 위해, mel-spectrogram $X_{mel}$에 의해 regularize 된 entirely reconstructed source $Z_{src}$와 mel-sepctrogram $Z_{ftr}$을 사용함:
- Disentangle representation에서 disentangled source와 filter mel-spectrogram은 다른 speaker representation $s$로 simply convert 됨
- 결과적으로 논문은 VC를 위해 각 denoiser에서 converted source와 filter mel-spectrogram을 prior로 채택함
- DDDM-VC는 source-filter theory를 따라 speech attribute를 정의함
- Source-Filter Decoder
- 논문은 DDDM을 기반으로 source, filter representation에 대한 disentanlged denoiser를 활용함
- 여기서 source decoder는 source representation $Z_{src}$를 prior로 사용하고 filter decoder는 filter representation $Z_{ftr}$를 prior로 사용함 - 이후, 각 denoiser는 speaker representation에 따라 condition 된 동일한 noise를 가지는 각 prior에서 target mel-spectrogram을 생성하도록 training 됨
- 이를 통해 각 denoiser는 own attribute에서 single noise를 제거하는데 focus 할 수 있음
- 이때 forward process는:
(Eq. 11) $dX_{src,t}=\frac{1}{2}\beta_{t}(Z_{src}-X_{src,t})dt+\sqrt{\beta_{t}}dW_{t}$
(Eq. 12) $dX_{ftr, t}=\frac{1}{2}\beta_{t}(Z_{ftr}-X_{ftr,t})dt+\sqrt{\beta_{t}}dW_{t}$
- $t\in [0,1]$, $X_{src,t}, X_{ftr,t}$ : 각 prior attribute (source-related, filter-related)로 생성된 noisy sample - (Eq. 11), (Eq. 12)의 forward SDE에는 reverse trajectory가 존재하므로 reverse process는:
(Eq. 13) $d\hat{X}_{src,t}=\left(\frac{1}{2}(Z_{src}-\hat{X}_{src,t})-\left(s_{\theta_{src}}(\hat{X}_{src,t},Z_{src},s,t)+s_{\theta_{ftr}}(\hat{X}_{ftr,t},Z_{ftr},s,t) \right)\right)\beta_{t}dt + \sqrt{\beta_{t}}d\bar{W}_{t}$
(Eq. 14) $d\hat{X}_{ftr,t}=\left(\frac{1}{2}(Z_{ftr}-\hat{X}_{ftr,t})-\left( s_{\theta_{ftr}}(\hat{X}_{ftr,t},Z_{ftr},s,t)+s_{\theta_{src}}(\hat{X}_{src,t},Z_{src},s,t)\right)\right)\beta_{t}dt+ \sqrt{\beta_{t}}d\bar{W}_{t}$
- $s_{\theta_{src}},s_{\theta_{ftr}}$ : 각각 $\theta_{src},\theta_{ftr}$로 parameterize 된 score function
- 이때 forward process는:
- 논문은 DDDM을 기반으로 source, filter representation에 대한 disentanlged denoiser를 활용함

- Prior Mixup
- Speech를 여러 attribute로 disentangle 하고 self-supervised representation과 diffusion process를 사용하여 고품질 resynthesize가 가능하지만, 여전히 input speech로만 training 되므로 training-inference mismatch 문제가 존재함
- 이를 해결하기 위해 논문은 위 그림의 (c)와 같이 reconstructed representation 대신 randomly selected representation을 prior distribution으로 사용하는 Prior Mixup을 도입함
- Source-filter encoder는 disentangled representation에서 source와 filter를 reconstruct 하도록 train 될 수 있음
- 따라서 converted source와 filter는 다음과 같이 randomly selected speaker style $s_{r}$로 얻어짐:
(Eq. 15) $Z_{src,r}=E_{src}(\text{pitch},s_{r}),\,\,\, Z_{ftr,r}=E_{ftr}(\text{content},s_{r})$ - 그러면 randomly converted source $Z_{src,r}$과 filter $Z_{ftr,r}$은 다음과 같이 각 denoiser의 prior로 사용됨:
(Eq. 16) $dX_{src,t}=\frac{1}{2}\beta_{t}(Z_{src,r}-X_{src,t})dt+\sqrt{\beta_{t}}dW_{t}$
(Eq. 17) $dX_{ftr,t}=\frac{1}{2}\beta_{t}(Z_{ftr,t}-X_{ftr,t})dt+\sqrt{\beta_{t}}dW_{t}$ - (Eq. 16), (Eq. 17)에 대한 reverse process는:
(Eq. 18) $d\hat{X}_{src,t}=\left(\frac{1}{2}(Z_{src,r}-\hat{X}_{src,t}) - s_{\theta_{src}}(\hat{X}_{src,t},Z_{src,r},s_{o},t)-s_{\theta_{ftr}}(\hat{X}_{ftr,t},Z_{ftr,r},s_{o},t)\right)\beta_{t}dt+\sqrt{\beta_{t}}d\bar{W}_{t}$
(Eq. 19) $d\hat{X}_{ftr,t}=\left(\frac{1}{2}(Z_{ftr,r}-\hat{X}_{ftr,t})- s_{\theta_{ftr}}(\hat{X}_{ftr,t},Z_{ftr,r},s_{o},t)-s_{\theta_{src}}(\hat{X}_{src,t},Z_{src,r},s_{o},t)\right)\beta_{t}dt+\sqrt{\beta_{t}}d\bar{W}_{t}$
- $s_{o}$ : original speaker style
- 따라서 converted source와 filter는 다음과 같이 randomly selected speaker style $s_{r}$로 얻어짐:
- 결과적으로 Prior Mixup은 model이 source speech를 reconstructing 할 때도 converted speech를 source speech로 convert 하도록 training 하기 때문에 training-inference mismatch 문제를 완화할 수 있음
- 특히 source-filter encoder가 추론 중에 VC를 효과적으로 수행하지 못하더라도 voice style을 source-filter decoder에 conditioning 할 수 있음 - Style encoder, source-filter encoder, pre-trained XLS-R와 $F0$ VQ-VQE가 없는 decoder를 포함하는 전체 model은 각 attribute에 대해 (Eq. 8), (Eq. 9)를 사용하여 end-to-end로 jointly train 됨
5. Experiments
- Settings
- Dataset : LibriTTS, VCTK
- Comparisons : AutoVC, DiffVC, VoiceMixer, SR
- Results
- Many-to-Many Voice Conversion
- 전체적으로 DDDM-VC가 가장 우수한 성능을 보임
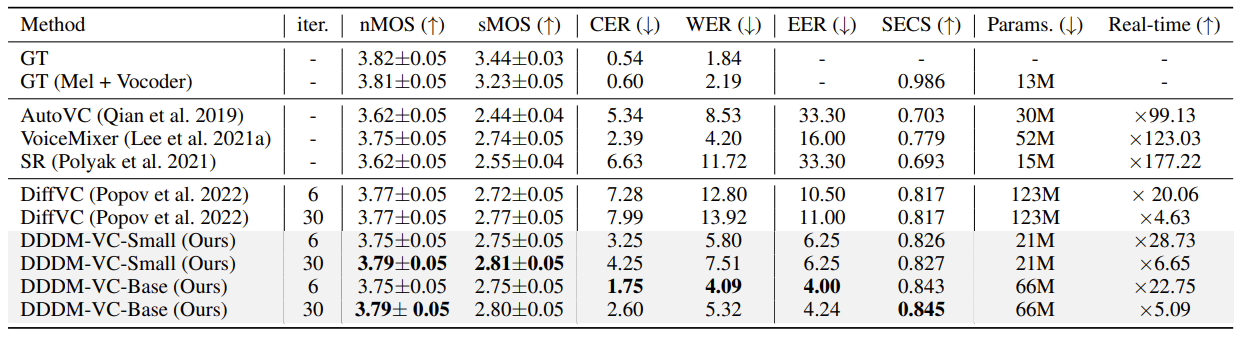
- Zero-Shot/One-Shot Voice Conversion
- Zero-shot, One-shot 설정의 경우에도 DDDM-VC의 성능이 가장 뛰어남
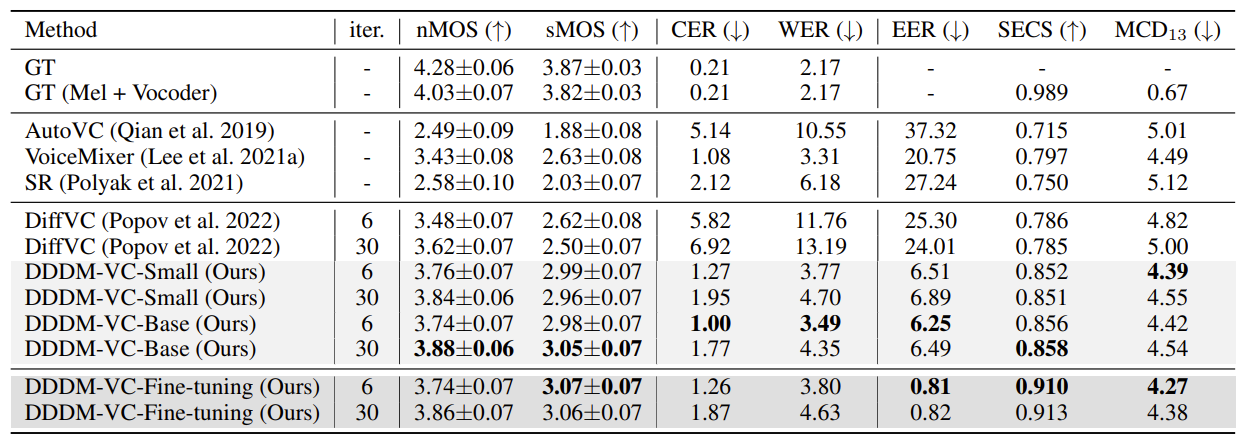
- Ablation Study
- Ablation study 측면에서 각 component가 제거되는 경우 성능 저하가 발생함

- Prior Mixup
- Prior Mixup이 적용되는 경우 더 나은 speaker adapatation을 제공하여 generalization을 향상할 수 있음
- 특히 prior mixup으로 training 된 diffusion decoder는 target voic style을 conditioning 하여 wrong prior에 대해서도 변환을 수행할 수 있음

- Prior Mixup이 없는 경우, large-scale model은 noisy sample에서 conditioning을 무시하고 random noise를 추정할 수 있음
- 이때 piror mixup을 적용하면 large-scale model에 대해서도 안정적인 성능을 달성 가능

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글