

티스토리 뷰
Paper/Conversion
[Paper 리뷰] CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-Spectrogram Conversion
feVeRin 2024. 8. 21. 09:15반응형
CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-Spectrogram Conversion
- Non-parallel voice conversion에서 CycleGAN-VC가 우수한 성능을 보임
- BUT, mel-spectrogram conversion에 대한 ambiguity로 인해 time-frequency structure가 손상됨 - CycleGAN-VC3
- Time-Frequency Adaptive Normalization을 도입하여 time-frequency structure를 반영
- 기존 CycleGAN의 mel-spectrogram conversion 성능을 향상
- 논문 (INTERSPEECH 2020) : Paper Link
1. Introduction
- Voice Conversion (VC)은 linguistic information을 retaining 하면서 non/para-linguistic information을 변환함
- 대부분의 VC method는 parallel corpus를 사용하여 source에서 target speech로의 mapping을 학습함
- BUT, parallel data는 수집하기 어렵다는 한계가 있음 - 한편으로 non-parallel VC는 data 수집 측면에서는 유용하지만, explicit supervision이 존재하지 않으므로 학습이 어렵다는 문제가 있음
- 이를 위해 CycleGAN-VC, StarGAN-VC와 같은 Generative Adversarial Network (GAN)-based 방식을 고려 가능
- BUT, mel-spectrogram conversion 과정에서 ambiguity로 인한 성능의 한계가 존재
- 대부분의 VC method는 parallel corpus를 사용하여 source에서 target speech로의 mapping을 학습함
-> 그래서 기존 CycleGAN-VC/VC2의 한계를 개선한 CycleGAN-VC3를 제안
- CycleGAN-VC3
- Mel-spectrogram의 time-frequency structure를 preserve 하기 위해 Time-Frequency Adaptive Normalization (TFAN)을 도입
- TFAN을 통해 source mel-spectrogram의 time-frequency structure를 반영하면서 converted feature의 scale/bias를 adjust
< Overall of CycleGAN-VC3 >
- CycleGAN-VC2를 기반으로 TFAN을 도입
- 결과적으로 기존 보다 뛰어난 conversion 성능을 달성
2. Conventional CycleGAN-VC/VC2
- Training Objectives
- CycleGAN-VC/VC2는 parallel corpus를 사용하지 않고, source acoustic feature $\mathbf{x}\in X$를 target acoustic feature $\mathbf{y}\in Y$로 변환하는 mapping $G_{X\rightarrow Y}$를 학습하는 것을 목표로 함
- CycleGAN-VC는 adversarial loss, cycle-consistency loss, identity-mapping loss를 사용하여 해당 mapping을 학습하고, CycleGAN-VC2에서는 second adversarial loss를 통해 reconstructed feature의 detail을 개선함
- Adversarial Loss
- Adversarial loss $\mathcal{L}_{adv}^{X\rightarrow Y}$는 converted feature $G_{X\rightarrow Y}(\mathbf{x})$가 target $Y$에 속하도록 함:
(Eq. 1) $\mathcal{L}_{adv}^{X\rightarrow Y}=\mathbb{E}_{\mathbf{y}\sim P_{Y}}[\log D_{Y}(\mathbf{y})] +\mathbb{E}_{\mathbf{x}\sim P_{X}}[\log (1-D_{Y}(G_{X\rightarrow Y}(\mathbf{x})) )]$ - Discriminator $D_{Y}$는 loss를 최대화하여 합성된 $G_{X\rightarrow Y}(\mathbf{x})$와 real $\mathbf{y}$를 distinguish 하고, $G_{X\rightarrow Y}$는 loss를 최소화하여 $D_{Y}$를 deceive 하는 $G_{X\rightarrow Y}(\mathbf{x})$를 합성함
- 마찬가지로 inverse mapping $G_{Y\rightarrow X}$와 discriminator $D_{X}$는 $\mathcal{L}_{adv}^{Y\rightarrow X}$를 통해 adversarially training 됨
- Adversarial loss $\mathcal{L}_{adv}^{X\rightarrow Y}$는 converted feature $G_{X\rightarrow Y}(\mathbf{x})$가 target $Y$에 속하도록 함:
- Cycle-Consistency Loss
- Conversion 과정에서 composition을 preserve 하기 위해 cycle-consistency loss $\mathcal{L}_{cyc}$가 사용됨:
(Eq. 2) $\mathcal{L}_{cyc}=\mathbb{E}_{\mathbf{x}\sim P_{X}}\left[ || G_{Y\rightarrow X}(G_{X\rightarrow Y}(\mathbf{x}))-\mathbf{x}||_{1}\right]+\mathbb{E}_{\mathbf{y}\sim P_{Y}}\left[ || G_{X\rightarrow Y}(G_{Y\rightarrow X}(\mathbf{y}))-\mathbf{y}||_{1}\right]$
- 해당 loss의 relative importance를 control 하기 위해 hyperparameter $\lambda_{cyc}$가 추가됨 - 해당 loss는 $G_{X\rightarrow Y}, G_{Y\rightarrow X}$가 cycle-consistency constraint 하에서 pseudo pair를 identify 하도록 함
- Conversion 과정에서 composition을 preserve 하기 위해 cycle-consistency loss $\mathcal{L}_{cyc}$가 사용됨:
- Identity-Mapping Loss
- Input preservation을 위해, identity-mapping loss $\mathcal{L}_{id}가 사용됨:
(Eq. 3) $\mathcal{L}_{id}=\mathbb{E}_{\mathbf{y}\sim P_{Y}}\left[|| G_{X\rightarrow Y}(\mathbf{y})-\mathbf{y}||_{1}\right]+\mathbb{E}_{\mathbf{x}\sim P_{X}}\left[ || G_{Y\rightarrow X}(\mathbf{x})-\mathbf{x}||_{1}\right]$
- 여기서 importance를 control 하기 위해 hyperparameter $\lambda_{id}$를 사용
- Input preservation을 위해, identity-mapping loss $\mathcal{L}_{id}가 사용됨:
- Second Adversarial Loss
- CycleGAN-VC2에서는 (Eq. 2)의 $L1$ loss로 발생하는 statistical averaging을 완화하기 위해 additional discriminator $D'_{X}$를 도입함
- 이때 second adversarial loss $\mathcal{L}_{adv2}^{X\rightarrow Y\rightarrow X}$는 circularly converted feature에 impose 됨:
(Eq. 4) $\mathcal{L}_{adv2}^{X\rightarrow Y\rightarrow X}=\mathbb{E}_{\mathbf{x}\sim P_{X}}[\log D'_{X}(\mathbf{x})]+\mathbb{E}_{\mathbf{x}\sim P_{X}}\left[\log(1-D'_{X}(G_{Y\rightarrow X}(G_{X\rightarrow Y}(\mathbf{x})) ) )\right]$
- 마찬가지로 discriminator $D'_{Y}$를 도입하여 inverse-forwrd mapping을 위한 $\mathcal{L}_{adv2}^{Y\rightarrow X\rightarrow Y}$를 적용할 수 있음
- Generator Architectures
- CycleGAN-VC는 1D CNN generator를 사용하여 temporal structure를 preserve 하면서 feature direction에 대한 relationship을 capture 함
- 구조적으로는 downsampling, residual, upsampling block으로 구성되어 wide-range temporal relationship을 반영
- Activation으로는 Gated Linear Unit (GLU)를 사용해 sequential, hierarchical structure를 학습 - 한편으로 CycleGAN-VC2에서는 down/upsampling block에서 2D CNN을 사용하고 residual block에서 1D CNN을 사용하는 2-1-2D CNN을 도입
- 여기서 2D CNN은 original structure를 preserve 하면서 time-frequency structure를 추출하고 1D CNN은 dynamic change를 수행
- 구조적으로는 downsampling, residual, upsampling block으로 구성되어 wide-range temporal relationship을 반영
- Discriminator Architectures
- CycleGAN-VC는 2D CNN disciminator를 사용하여 2D spectral texture를 discriminate 함
- 이때 last layer에 fully-connected layer를 적용한 FullGAN을 활용
- BUT, FullGAN은 많은 parameter가 필요하므로 training이 학습에 어려움이 있음 - 한편으로 CycleGAN-VC2는 last layer에 convolution을 적용한 PatchGAN을 사용해 parameter 수를 줄이고 GAN training을 stabilize 함
- 이때 last layer에 fully-connected layer를 적용한 FullGAN을 활용
3. CycleGAN-VC3
- TFAN: Time-Frequency Adaptive Normalization
- CycleGAN-VC/VC2는 conversion 과정에서 preserve 되어야 하는 time-frequency structure를 손상시킬 수 있음
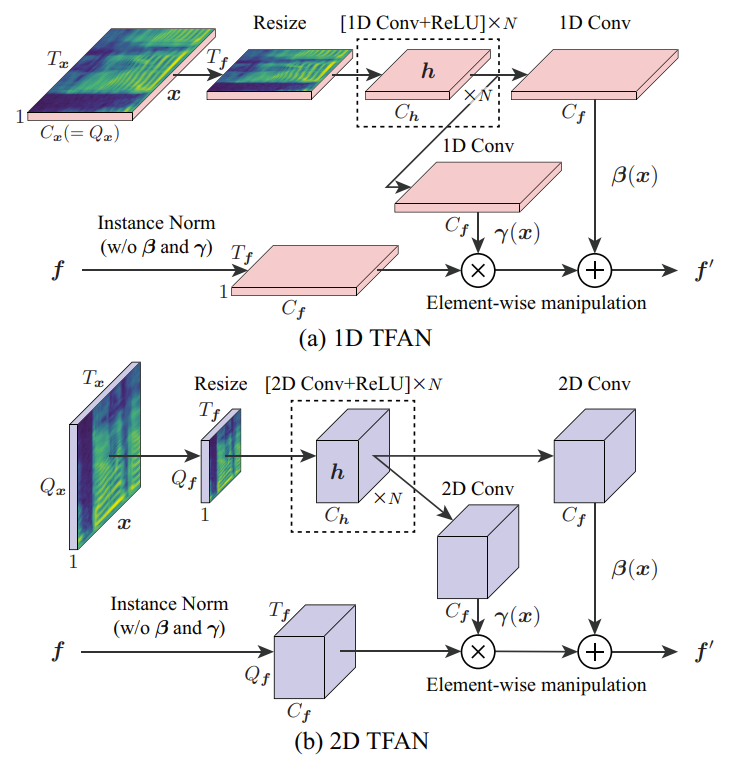
- 따라서 CycleGAN-VC3에서는 time-frequency-wise로 source information $\mathbf{x}$를 반영하면서 converted feature의 scale/bias를 adjust 하기 위해, Instance Normalization (IN)을 확장한 TFAN을 도입
- 특히 2-1-2D CNN의 1D/2D time-frequency feature에 대한 TFAN을 설계함 - 먼저 feature $\mathbf{f}$가 주어지면 TFAN은 IN과 같이 channel-wise normalization을 수행하고, CNN을 통해 $\mathbf{x}$에서 계산된 scale $\gamma(\mathbf{x})$와 bias $\beta(\mathbf{x})$를 사용하여 normalized feature를 element-wise로 modulate 함:
(Eq. 5) $\mathbf{f}'=\gamma(\mathbf{x})\frac{\mathbf{f}-\mu(\mathbf{f})}{ \sigma(\mathbf{f})}+\beta(\mathbf{x})$
- $\mathbf{f}'$ : output feature, $\mu(\mathbf{f}),\sigma(\mathbf{f})$ : 각각 $\mathbf{f}$의 channel-wise 평균/표준편차 - IN에서 $\mathbf{x}$-independent scale $\beta$와 bias $\gamma$는 channel-wise로 적용되지만, TFAN에서 계산된 $\beta(\mathbf{x}),\gamma(\mathbf{x})$는 element-wise로 적용됨
- 이를 통해 TFAN은 time-/frequency-wise로 $\mathbf{x}$를 반영할 수 있고, $\mathbf{f}$의 scale/bias를 adjust 할 수 있음 - 구조적으로 TFAN은 image synthesis에서 활용되는 SPADE와 유사하지만 다음의 차이점을 가짐:
- 이때 SPADE는 2D image feature에 특화되어 있지만 TFAN은 1D, 2D time-frequency feature를 대상으로 함
- SPADE는 one-layer CNN을 사용하지만 TFAN은 dynamic change를 보장하기 위해 multi-layer CNN을 사용
- SPADE는 batch normalization을 사용하지만, TFAN은 IN을 기반으로 함
- 따라서 CycleGAN-VC3에서는 time-frequency-wise로 source information $\mathbf{x}$를 반영하면서 converted feature의 scale/bias를 adjust 하기 위해, Instance Normalization (IN)을 확장한 TFAN을 도입
- Implementation
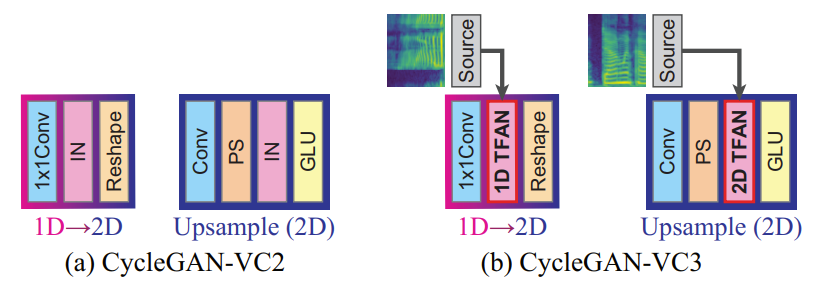
- CycleGAN-VC3는 TFAN을 CycleGAN-VC2 generator에 결합하여 구성됨
- 이때 아래 그림과 같이 1D $\rightarrow$ 2D block의 IN과 upsampling block의 IN을 각각 1D TFAN, 2D TFAN으로 대체함
- Channel size $C_{h}$와 kernel size $h$를 각각 128, 5로 설정 - Discriminator는 CycleGAN-VC2의 PatchGAN을 활용
- 이때 아래 그림과 같이 1D $\rightarrow$ 2D block의 IN과 upsampling block의 IN을 각각 1D TFAN, 2D TFAN으로 대체함
3. Experiments
- Settings
- Dataset : VCC2018
- Comparisons : CycleGAN-VC, CycleGAN-VC2
- Results
- Naturalness, Similarity 측면에서 CycleGAN-VC3의 성능이 가장 뛰어남
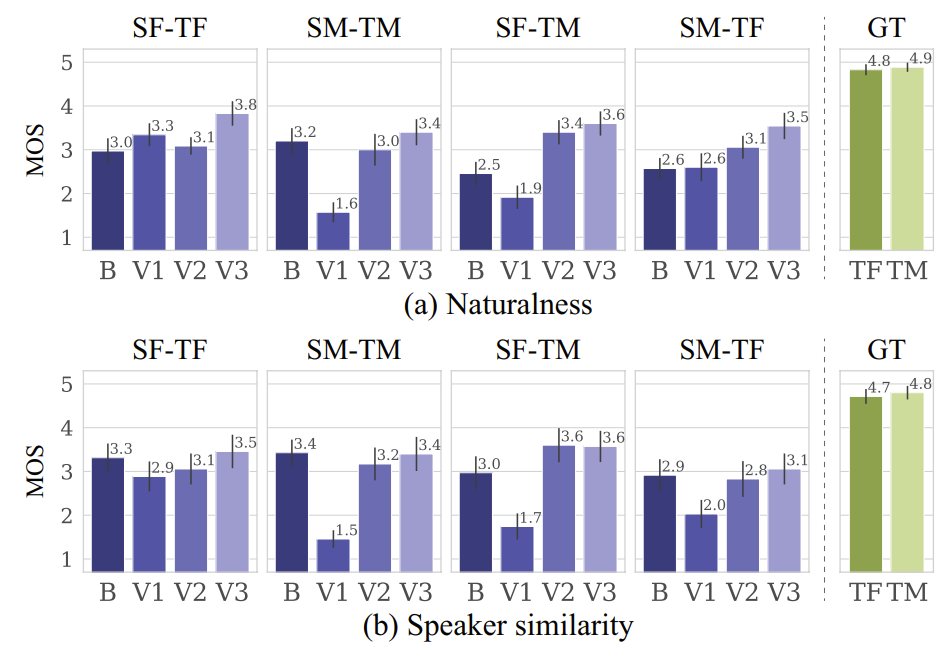
- TFAN depth가 3이고 1D $\rightarrow$ 2D/upsampling에 모두 사용할 때 가장 우수한 성능을 보임

- Mel-spectrogram 측면에서도 CycleGAN-VC3는 ground-truth와 비슷한 결과를 합성함

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글