

티스토리 뷰
Paper/TTS
[Paper 리뷰] Spotlight-TTS: Spotlighting the Style via Voiced-Aware Style Extraction and Style Direction Adjustment for Expressive Text-to-Speech
feVeRin 2025. 7. 8. 17:00반응형
Spotlight-TTS: Spotlighting the Style via Voiced-Aware Style Extraction and Style Direction Adjustment for Expressive Text-to-Speech
- Expressive Text-to-Speech는 여전히 한계가 있음
- Spotlight-TTS
- 서로 다른 speech region의 continuity를 maintain 하는 Voiced-Aware Style Extraction을 도입
- 추가적으로 추출된 style의 direction을 adjust 하여 speech quality를 향상
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 input text에서 speech를 synthesize 하는 것을 목표로 함
- 특히 expressive TTS를 위해서는 style-annotated dataset이나 text-speech data pair를 요구하지 않는 style transfer TTS가 주로 활용됨
- 대표적으로 Meta-StyleSpeech는 pooling operation을 통해 sentence-level style을 반영하고 GenerSpeech는 frame-level style을 추출하여 fine-grained style을 반영함
- 한편으로 TSP-TTS, TCSinger와 같이 Residual Vector Quantization (RVQ)와 Clustering Style Encoder (CSE)를 활용할 수도 있음
- BUT, codebook 기반의 style extraction method는 다음의 한계점이 있음:
- 모든 temporal segment를 equally treat 하고 speaking style 추출 시 서로 다른 speech region의 importance를 capture 하지 못함
- Backpropagation에서 사용되는 straight-through estimator는 각 codebook region 내에서 encoded feature의 relative positioning을 disregrad 하므로 fine-grained style detail을 학습하기 어려움
- 추출된 style embedding이 content와 independent 하다는 것을 보장할 수 없으므로 style transfer 시 content leakage가 발생할 수 있음
- 특히 expressive TTS를 위해서는 style-annotated dataset이나 text-speech data pair를 요구하지 않는 style transfer TTS가 주로 활용됨
-> 그래서 expressive TTS를 위해 codebook-based style extraction을 개선한 Spotlight-TTS를 제안
- Spotlight-TTS
- Rich acoustic information을 포함하는 voiced region에 대해, Voiced-Aware Style Extraction을 적용
- Compact representation을 기반으로 effective quantization을 지원하여 finer granularity로 style-related feature preservation을 향상함 - Quantization process에서 straight-through estimator를 rotation trick으로 replace 하여 voiced region에서 precise style extraction을 지원
- 추가적으로 Style Direction Adjustment를 통해 embedding space에서 content, prosody vector를 사용하여 extracted style의 angle을 modify
- Rich acoustic information을 포함하는 voiced region에 대해, Voiced-Aware Style Extraction을 적용
< Overall of Spotlight-TTS >
- Voiced-Aware Style Extraction, Style Direction Adjsutment를 활용한 expressive TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- Spotlight-TTS는 style direction을 adjust 하면서 서로 다른 mel-spectrogram region의 importance를 고려하여 style을 추출하는 것을 목표로 함
- 이를 위해 논문은 Voiced-Aware Style Extraction과 Style Direction Adjustment를 도입함
- Voiced-Aware Style Extraction
- Codebook learning을 통한 style extraction은 speaking style에 unequally contribute 하는 다양한 mel-spectrogram을 반영하여 개선될 수 있음
- 특히 voiced region은 speaking style과 highly correlate 된 harmonics로 구성되고, unvoiced region은 style과 less relevant 한 simple repetitive pattern을 가짐
- 따라서 논문은 voiced region에 focus 하고 unvoiced region을 unvoiced filler (UF) module로 filling 하는 Voiced-Aware Style Extraction을 도입함
- Voiced Frame Processing
- 논문은 detailed style embedding을 추출하기 위해 RVQ module을 사용함
- Unvoiced region은 voiced region에 비해 less-relevant 하므로 Voiced Extraction (VE)를 통해 RVQ processing을 voiced frame에 focus 함 - 먼저 RVQ module의 input으로는, intermediate feature로부터 voiced frame만 aggregate 할 수 있는 pre-extracted Voiced and Unvoiced (V/UV) flag를 사용함
- Quantization 시에는 quantization layer를 통한 gradient flow를 개선하기 위해 straight-through estimator 대신 Rotation Trick (RT)를 채택함
- RT는 backpropagation 동안 loss gradient와 codebook vector 간의 angle을 preserve 할 수 있음 - 이때 RT는:
(Eq. 1) $ \tilde{q}=\text{sg}\left[\frac{||q||}{||e||}R\right]e$
- $R$ : input feature $e$를 closest codebook vector $q$에 align 하는 rotation transformation
- $\frac{||q||}{||e||}$ : $q$의 magnitude로 $e$를 rescale 하는 역할, $\text{sg}[\cdot]$ : stop-gradient operation
- Quantization 시에는 quantization layer를 통한 gradient flow를 개선하기 위해 straight-through estimator 대신 Rotation Trick (RT)를 채택함
- Forward pass에서는 quantized vector 대신 transformed input feature $\tilde{q}$를 사용함
- $\tilde{q}$는 forward pass에서 $q$와 identical 하고 RVQ output이 unchange 하도록 보장함 - Backward pass에서는 $q$를 $e$에 대해 rewrite 함으로써 gradient를 rotate 하고 codebook 내에서 $e$의 relative position을 capture 함
- 논문은 detailed style embedding을 추출하기 위해 RVQ module을 사용함
- Unvoiced Filler Module
- 서로 다른 region 간의 style continuity를 개선하기 위해 논문은 UF module을 도입함
- Quantization 이후 uniform random initialization으로 learnable mask code embedding을 생성하고, 해당 positional information을 기반으로 unvoiced position에 insert 함
- 다음으로 UF module은 해당 embedding을 meaningful acoustic information으로 filling 함 - 구조적으로 UF module은 $N$ identical sub-module로 구성되고, 각 sub-module은 ConvNeXt block과 biased self-attention을 가짐
- Biased self-attention은 non-masked region에서 mask code region으로 information flow를 enable 하면서 opposite direction은 blocking 하는 역할을 함
- 해당 asymmetric information flow를 통해 model은 mask code region이 non-masked region에 negatively affecting 하지 않으면서 non-masked region을 사용할 수 있음 - 여기서 biased self-attention은:
(Eq. 2) $\text{Attention}(q,k,v)=\left(\text{SoftMax}\left(\frac{qk^{\top}}{\sqrt{d}}\right)\odot \beta\right)v$
- $\beta$ : Attention Reweighting (AR) coefficient
- 논문은 asymmetric information flow를 위해 mask position에서는 $\beta=0.2$, non-masked position에서는 $\beta=1$로 설정함
- Biased self-attention은 non-masked region에서 mask code region으로 information flow를 enable 하면서 opposite direction은 blocking 하는 역할을 함

- Style Direction Adjustment
- Style 추출 이후, 논문은 content information을 remove 하기 위해 style의 directionality를 adjust 함
- 이를 위해 2가지의 complementary loss를 도입함
- Style Disentanglement (SD) loss는 style, content 간의 orthogonality를 encourage 하고 Style Preserving (SP) loss는 style을 prosody와 align 함
- Style Disentanglement Loss
- 먼저 style, content information을 disentangle 하기 위해 orthogonality loss를 사용함
- Style embedding 내의 content information이 content embedding learning을 interfere 할 수 있으므로, training 시 content embedding을 detach 하는 것을 목표로 함 - 여기서 SD loss $\mathcal{L}_{sd}$는:
(Eq. 3) $ \mathcal{L}_{sd}=\left|\left| \text{sg}[E_{c}]E_{s}^{\top}\right|\right|_{F}^{2}$
- $E_{c}, E_{s}$ : 각각 content, style embedding, $||\cdot ||_{F}^{2}$ : Frobenius norm
- 먼저 style, content information을 disentangle 하기 위해 orthogonality loss를 사용함
- Style Preserving Loss
- Style learning의 stability를 향상하고 $F0$, V/UV prediction error를 mitigate 하기 위해 SP loss를 도입함
- SP loss는 low-frequency prosody embedding 과의 similarity를 increase 하여 extracted style embedding을 refine 함 - 이때 mel-spectrogram의 lower 20 bin과 style embedding에서 prosody embedding을 추출하기 위해 2개의 separate MLP block을 사용함
- 이후 해당 embedding 간의 cosine-similarity를 increase 하여 style embedding 내의 prosody information을 refine 함 - SP loss $\mathcal{L}_{sp}$는 다음과 같이 정의됨:
(Eq. 4) $\mathcal{L}_{sp}=-\sum_{i=1}^{t}\text{cos\_sim}(p_{i},\tilde{s}_{i})$
- $t$ : timestep 수, $p_{i}$ : low-band mel-spectrogram에서 추출된 prosody vector, $\tilde{s}_{i}$ : projected style vector
- Style learning의 stability를 향상하고 $F0$, V/UV prediction error를 mitigate 하기 위해 SP loss를 도입함
- Training Stage of Spotlight-TTS
- Spotlight-TTS는 text encoder, variance adaptor, decoder, discriminator, style encoder, MLP block으로 구성됨
- 여기서 MLP block과 discriminator는 training phase에서만 사용됨
- 한편으로 mel-spectrogram synthesize를 위해 논문은 FastSpeech2의 objective function $\mathcal{L}_{fs2}$를 사용하고, RVQ module training에는 $\mathcal{L}_{rvq}$를 사용함
- 결과적으로 얻어지는 total loss는:
(Eq. 5) $\mathcal{L}_{total}=\mathcal{L}_{fs2}+\lambda_{rvq}\mathcal{L}_{rvq}+\lambda_{adv}\mathcal{L}_{adv}+\lambda_{sd}\mathcal{L}_{sd}+\lambda_{sp}\mathcal{L}_{sp}$
- $\lambda_{rvq}=1.0,\lambda_{adv}=0.05,\lambda_{sd}=0.02,\lambda_{sp}=0.02$ : weights
3. Experiments
- Settings
- Dataset : Emotional Speech Dataset (ESD)
- Comparisons : FastSpeech2, StyleSpeech, GenerSpeech
- Results
- 전체적으로 Spotlight-TTS의 성능이 가장 우수함

- AXY test 측면에서도 Spotlight-TTS가 가장 선호됨

- Voiced-Aware Style Extraction
- RT, UF, VE 모두 style extraction에 중요한 영향을 미침
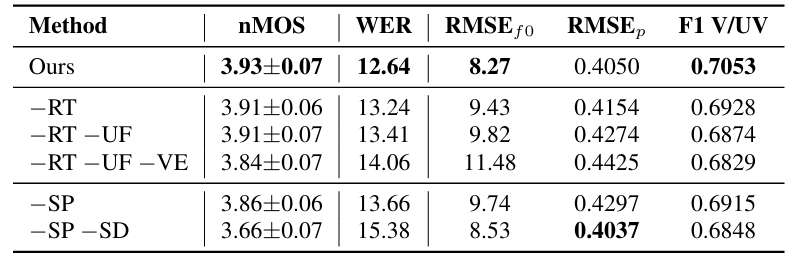
- Biased Self-Attention
- Biased Self-Attention을 사용하면 simple Binary Mask (BM) 보다 더 나은 성능을 달성할 수 있음

반응형
'Paper > TTS' 카테고리의 다른 글
댓글