

티스토리 뷰
Paper/TTS
[Paper 리뷰] DiEmo-TTS: Disentangled Emotion Representations via Self-Supervised Distillation for Cross-Speaker Emotion Transfer in Text-to-Speech
feVeRin 2025. 7. 6. 07:38반응형
DiEmo-TTS: Disentangled Emotion Representations via Self-Supervised Distillation for Cross-Speaker Emotion Transfer in Text-to-Speech
- 기존의 emotional Text-to-Speech model은 speaker, emotion characteristic을 fully separate 하지 못함
- DiEmo-TTS
- Emotional attribute prediction과 speaker embedding을 사용한 emotion clustering을 도입
- Style feature를 integrate하는 dual conditioning Transformer를 활용
- 논문 (INTERSPEECH 2025) : Paper Link
1. Introduction
- Cross-speaker scenario의 emotional speech synthesis는 reference에서 다른 target speaker로 emotion을 transfer 하는 것을 목표로 함
- 이를 위해 reference-based style transfer를 활용할 수 있지만, prosodic feature는 speaker identity와 inherently associate되어 있으므로 complete disentanglement를 달성하기 어려움
- 즉, target speaker timbre를 compromising하지 않으면서 accurate emotional transfer를 달성하기 위해서는 speaker identity와 emotion-related prosodic feature를 adequately separate 할 수 있어야 함
- BUT, Gradient Reversal Layer (GRL)을 통한 explicit speaker label disentanglement method는 speaker identity separation과 emotion preserving 간에 trade-off가 존재함
- 따라서 hyperparameter optimization의 어려움으로 인해 synthesis quality의 한계가 있음 - Vector Quantization (VQ) 방식 역시 information loss와 optimization의 어려움이 있음
- BUT, Gradient Reversal Layer (GRL)을 통한 explicit speaker label disentanglement method는 speaker identity separation과 emotion preserving 간에 trade-off가 존재함
- 특히 이러한 기존 strategy들은 주로 prosody에 대해 acoustic model을 conditioning하므로, style을 obscure 하고 complex variation을 modeling 하기 어렵게 만듦
- 결과적으로 synthesized speech는 style과 quality가 inconsistent함
-> 그래서 더 나은 emotional naturalness, intonation, speaker-specific pronunciation을 반영할 수 있는 DiEmo-TTS를 제안
- DiEmo-TTS
- Distillation with No Labels (DINO) strategy에 기반한 teacher-student emotion encoder를 통해 Self-Supervised Learning (SSL) representation을 반영
- Emotional information loss를 minimize 하고 expressiveness를 개선하기 위해 cluster-driven sampling을 도입
- 추가적으로 emotion, speaker characteristic에 대한 adaptability를 향상하기 위해 style-adaptive condition module을 적용
< Overall of DiEmo-TTS >
- Self-Supervised distillation strategy를 활용한 cross-speaker emotional TTS model
- 결과적으로 기존보다 우수한 성능을 달성
2. Method
- DiEmo-TTS는 self-supervised distillation을 통해 emotional embedding을 추출하여 emotional expressiveness를 향상하는 것을 목표로 함
- Disentanglement of Emotion Representation via Self-Supervised Distillation
- Clustering and Matching of Emotion
- Speaker embedding은 각 speaker의 embedding space 내에서 서로 다른 emotional state를 따라 cluster 됨
- BUT, emotion category와 intra-speaker cluster 간의 mapping은 speech signal의 variation으로 인해 한계가 있음 - 이를 위해 논문은 emotional attribute prediction을 활용한 emotion dimension pseudo-label을 도입함
- 특히 neutral emotion cluster $p_{n}$을 center로 한 region을 정의하기 위해, 각각의 cluster에 대해 predict 된 emotional attribute의 central point에 Convex Hull algorithm을 적용함:
(Eq. 1) $ p_{n}=\arg\max_{p_{i}\in S}\text{Area}\left(\text{ConvexHull}\left(S \backslash \{p_{i}\} \right)\right)$
- $S=\{p_{1},p_{2},...,p_{M}\}$ : mean predicted emotional dimension set
- $p_{i}$ : $i$-th cluster의 mean value, $M$ : total cluster 수
- $S \backslash \{p_{i}\}$ : set difference로써, element $\{p_{i}\}$를 exclude 한 set $S$를 의미 - 이후 EmoSphere-TTS와 같이 neutral emotion cluster $p_{n}$을 중심으로 spherical coordinate transformation을 적용하여 각 clsuter에 대한 relative positional information인 azimuth, elevation angle을 추출함
- 최종적으로는 azimuth, elevation angle의 relative positional information을 사용하여 각 speaker 내의 cluster를 same emotion으로 align 함
- 이는 $k$-assignment problem에 대한 multiple Hungarian method를 통해 수행됨
- 특히 neutral emotion cluster $p_{n}$을 center로 한 region을 정의하기 위해, 각각의 cluster에 대해 predict 된 emotional attribute의 central point에 Convex Hull algorithm을 적용함:
- Speaker embedding은 각 speaker의 embedding space 내에서 서로 다른 emotional state를 따라 cluster 됨
- Emotion Disentanglement DINO
- 논문은 다음의 approach를 반영한 emotion disentanglement DINO를 도입함:
- Same cluster 내의 emotion은 same identity를 share 한다고 가정하여 cluster-driven sampling을 적용함
- 해당 cluster-based random cropping을 통해 same emotion 내에서 content, speaker에 대한 variation을 얻을 수 있음 - Information Perturbation (IP)를 통해 emotional expression을 preserve 하고 speaker information을 distort 함
- 특히 speaker timbre, speech formant 간의 correlation을 활용하여 formant perturbation이 speaker identity를 distrot 할 수 있도록 함 - Cosine similarity를 DINO loss에 추가하여 emotion embedding을 suitable space로 encode 함
- Same cluster 내의 emotion은 same identity를 share 한다고 가정하여 cluster-driven sampling을 적용함
- 모든 crop $N$은 student encoder를 통과하고 long crop $L$은 teacher encoder를 통과하여 expressivity embedding $e_{s},e_{t}$를 추출함
- 이때 embedding 간의 cosine similarity를 maximize 함으로써 emotion loss를 reduce 하고 clustering에 suitable 한 high-quality embedding space를 생성할 수 있음
- 이후 DINO loss는 head output $h_{s}, h_{t}$ 간의 cross-entropy loss로 compute 됨
- 결과적으로 얻어지는 formulation은:
(Eq. 2) $ \mathcal{L}_{DINO}=\frac{1}{L\cdot (N-1)}\sum_{l=1}^{L}\sum_{m=1,m\neq 1}^{N} \left[\text{CE}\left(h_{t}^{l},h_{s}^{m}\right)+\text{CS}\left(e_{t}^{l},e_{s}^{m}\right)\right]$
- $l,m$ : $l$-th long crop, $m$-th all crop, $s,t$ : student, teacher embedding
- $\text{CE}(a,b)=-a\log b, \text{CS}(a,b)=1-\cos (a,b)$ : cross-entropy loss, cosine similarity loss
- 논문은 다음의 approach를 반영한 emotion disentanglement DINO를 도입함:
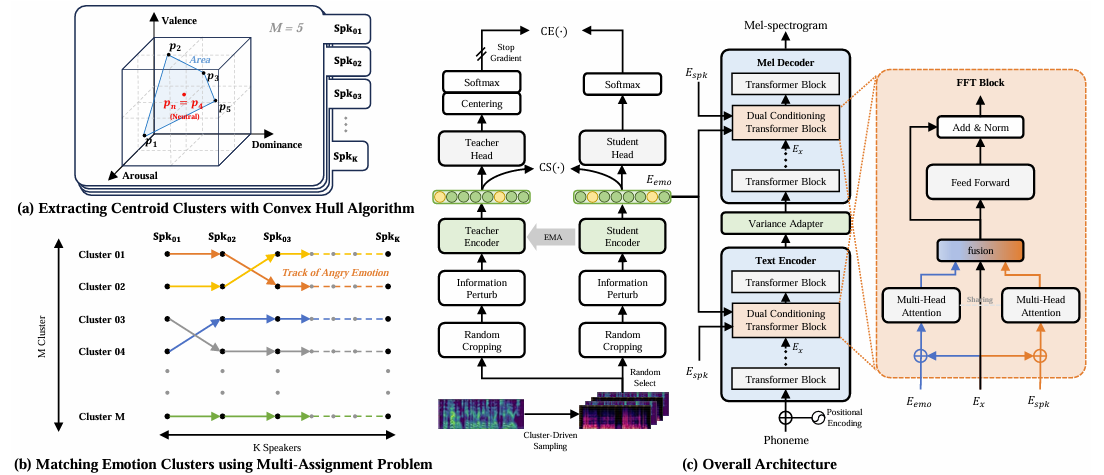
- Style-Adaptive Condition Modules
- High-quality synthesis를 위해서는 naturalness 뿐만 아니라 stylistic consistency를 maintain 해야 함
- 이를 위해 논문은 VITS2를 따라 encoder/decoder의 intermediate feature에 multiple factor를 fuse 하는 Dual Conditioning Transformer (DCT) block을 도입함
- 즉, Transformer block의 각 style information type에 대해 weight-sharing multi-head attention conditioning을 적용함
- 이후 attention output은 multi-layer perceptron에 의해 fuse 되어 multiple speech feature를 integrate 함
- TTS Model
- 논문은 FastSpeech2를 기반으로 speaker-disentangled emotional state를 제공하는 emotion embedding $E_{emo}$와 objective function $\mathcal{L}_{DINO}$를 integrate 함
- $E_{emo}$는 text에 해당하는 reference mel-spectrogram의 short corp으로 fix 되고 student encoder output을 사용하여 얻어짐
- Speaker label은 서로 다른 speaker characteristic을 represent 하기 위해 embedding $E_{spk}$로 mapping 됨
- 추론 시에는 desired emotional reference mel-spectrogram을 student encoder에 전달하여 emotion embedding을 추출한 다음, speech synthesis를 수행함
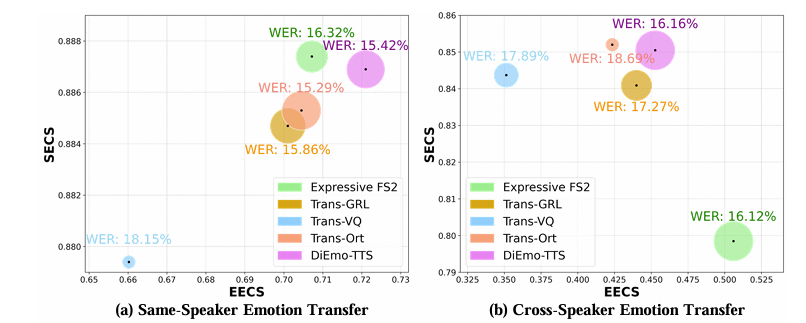
3. Experiments
- Settings
- Dataset : Emotional Speech Dataset (ESD)
- Comparisons : Trans-GRL, Trans-VQ, Trans-Ort
- Results
- 전체적으로 DiEmo-TTS의 성능이 가장 우수함

- Speaker, emotion similarity 측면에서도 DiEmo-TTS가 가장 뛰어남
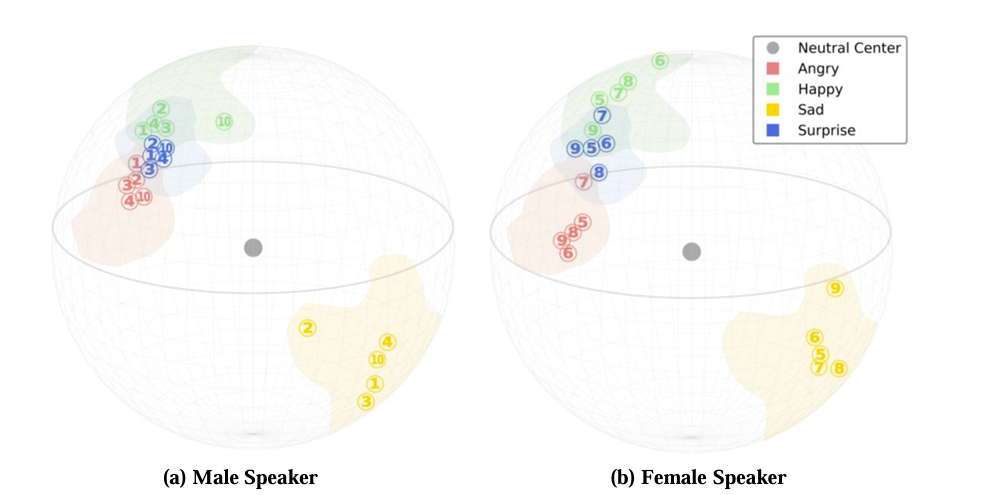
- Analysis of Emotion Clustering and Matching
- DiEmo-TTS의 emotion cluster는 clearly separete 되어있음

- Relative positional information 역시 speaker의 emotion에 따라 grouping 되어 있음
- Ablation Study
- 각 component를 제거하는 경우 성능 저하가 발생함

반응형
'Paper > TTS' 카테고리의 다른 글
댓글