
티스토리 뷰
Paper/TTS
[Paper 리뷰] GenerSpeech: Toward Style Transfer for Generalizable Out-of-Domain Text-to-Speech
feVeRin 2024. 1. 30. 15:07반응형
GenerSpeech: Towards Style Transfer for Generalizble Out-of-Domain Text-to-Speech
- Out-of-Domain 음성 합성을 위해 style transfer를 활용할 수 있지만 몇 가지 한계가 존재함
- Expressive voice의 dynamic style feature는 모델링과 transfer가 어려움
- Text-to-Speech 모델은 source data와 다른 Out-of-Domain condition을 handle 할 수 있을 만큼 robust 해야 함 - GenerSpeech
- Out-of-Domain custom voice에 대해 high-fidelity zero-shot style transfer를 가능하게 하는 text-to-speech 모델
- 광범위한 style condition을 모델링하는 Multi-level Style Adaptor의 도입
- Linguistic content representation에서 style information을 제거하여 generalization을 향상하는 Mix-Style Layer Normalization
- 논문 (NeurIPS 2022) : Paper Link
1. Introduction
- Text-to-Speech (TTS)는 expressive 하고 다양한 음성 생성을 위해 multiple speaker, emotion, style 등을 포함하는 복잡한 환경으로 확장되고 있음
- 하지만 domain shift와 관련한 unseen scenario에서 TTS 모델의 사용은 여전히 어려움이 있음
- 특히 generalizable Out-of-Domain (OOD) TTS는 custom voice와 같은 acoustic reference에서 파생된 unseen style (timbre, emotion 등)을 사용하여 고품질의 음성 sample을 합성하는 것을 목표로 함 - 이러한 OOD TTS 작업에는 2가지 한계가 있음
- Style modelling and Transferring
- Expressive voice의 high dynamic range는 control과 transfer가 어려움
- 대부분의 TTS 모델의 경우 평균적인 분포만 학습하기 때문에 sample에 대한 fine-grained control이 어려움 - Model Generalization
- Custom voice와 training data가 다를 때, 분포의 차이로 인해 합성 품질이 저하됨
- Style modelling and Transferring
- 위의 OOD TTS 문제를 해결하기 위한 여러 방법들이 제시되었지만, 완전히 해결된 것은 아님
- Style Modelling and Transferring
- Global Style Token의 활용 : GST를 통해 음성의 global scale style feature를 memorize 하고 reporduce 하는 방식
- Fine-grained latent variable의 활용 : global utterance-level과 local quasi-phoneme-level style을 모두 활용하는 방식
-> BUT, 여전히 서로 다른 style characteristic을 제한적으로 capture 하고 speaker identity, emotion, prosody range를 올바르게 반영하지 못함 - Model Generalization
- Data-driven Method : 대규모의 dataset에서 pre-train 하여 data 분포를 확장하는 방법
- Style Adaptation : fine-tuning, meta-learning 등을 활용하는 방법
-> BUT, 대규모 dataset은 많은 비용이 필요하고, style adaptation은 target voice가 accessible 하다는 가정이 실제로는 불가능한 경우가 많음
- Style Modelling and Transferring
- 이때 더 나은 generalization을 위해, disentangled representation learning을 활용할 수 있음
- 모델을 domain-agnostic과 domain-specific part로 decompose 하는 방식
- 하지만 domain shift와 관련한 unseen scenario에서 TTS 모델의 사용은 여전히 어려움이 있음
-> 그래서 OOD TTS의 style transfer 문제를 해결하기 위해, 음성 variation을 style-agnostic과 style-specific part로 decompose 하는 GenerSpeech를 제안
- GenerSpeech
- Style-agnostic (linguistic content)와 Style-specific (speaker identity, emotion, prosody) variation을 개별적으로 모델링하고 제어
- Multi-level Style Adaptor는 custom utterance의 global/local stylization을 위해 사용됨
- Downstream wav2vec 2.0 encoder를 통하여 speaker와 emotion representation을 제어할 수 있는 latent representation을 생성
- 3개의 local style encoder는 explicit label 없이 fine-grained frame, phoneme, word-level prosody를 모델링 - Mix-Style Layer Noramlization (MSLN)을 채택하여 generalization을 향상
- MSLN은 linguistic content representation에서 style attribute를 제거하고 style-agnostic variation을 예측
< Overall of GenerSpeech >
- 광범위한 style condition을 모델링하는 Multi-level Style Adaptor의 도입
- Linguistic content representation에서 style information을 제거하고 generalization을 향상하는 MSLN의 사용
- 결과적으로 OOD TTS를 위한 zero-shot style transfer 작업에서 GenerSpeech가 가장 우수한 성능을 달성
2. GenerSpeech
- Problem Formulation
- OOD custom voice에 대한 style transfer는,
- Training data와는 다른 acoustic condition을 가지는 reference utterance에서 파생된 unseen style (speaker identity, emotion, prosody)를 사용하여 고품질의 음성 sample을 생성하는 것을 목표로 함
- Overview
- GenerSpeech는 FastSpeech2를 backbone으로 활용함
- Disentangled representation learning을 통해 TTS 모델을 domain-agnostic, domain-specific part로 decompose 함으로써 generalization을 향상할 수 있음
- 따라서 GenerSpeech는 style-agnositc (linguistic content)과 style-specific (speaker identity, emotion, prosody)를 개별적으로 모델링할 수 있어야 함
- 이를 위해,
- Linguistic content representation에서 style information을 제거하는 Mix-Style Layer Normalization (MSLN)을 채택하여 generalization을 향상
- 3개의 local encoder (frame, phoneme, word-level)로 구성된 Multi-level Style Adaptor를 통해 style attribute transferring을 향상
- Sample의 detail을 reconstruct 하는 Flow-based Post-net을 사용하여 fine-grained mel-spectrogram을 생성
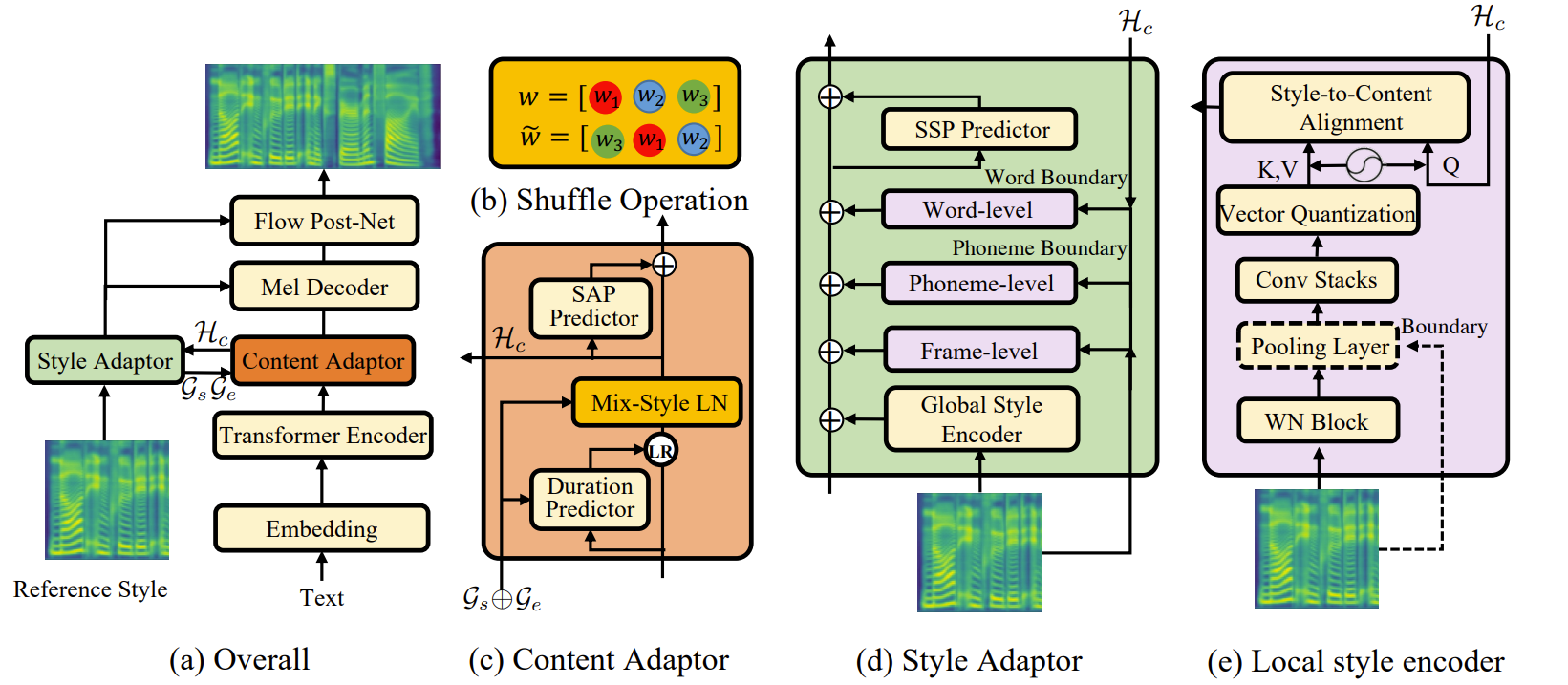
- Generalizable Content Adaptor
- OOD custom voice를 통한 style transfer의 품질 저하를 방지하기 위해,
- Mix-Style Layer Normalization을 사용하여 phonetic sequence의 style information을 제거하고 style-agnoistic prosodic variation을 예측
- Mix-Style Layer Normalization
- Layer Normalization은 lightweight learnable sacle vector $\gamma$, bias vector $\beta$를 사용하여 hidden activation과 최종 예측에 큰 영향을 미칠 수 있음:
$LN(x) = \gamma \frac{x-\mu}{\sigma} + \beta$
- $\mu, \sigma$ : 각각 hidden vector $x$의 평균, 분산 - 추가적으로 speaker adaptation을 위한 conditional layer noramlization은, style embedding을 기반으로 normalized input feature의 shifting과 scaling을 수행할 수 있음:
$CLN(x,w) = \gamma(w) \frac{x-\mu}{\sigma}+\beta(w)$
- 이때 2개의 simple linear layer $E^{\gamma}, E^{\delta}$는 style embedding $w$를 input으로 사용하여 각각 scale과 bias vector를 output:
(Eq. 1) $\gamma(w) = E^{\gamma}*w, \,\,\,\, \beta(w) = E^{\delta} * w$ - Source와 target domain 간의 discrepancy는 TTS 모델의 generalization을 방해함
- Style information을 disentangle 하고 style-agnostic representation을 학습하기 위해서는 mismatch style information에 따라 sequence를 refine 해야 함
- 구조적으로는, 모델이 style과 match 하는 representation을 생성하지 못하도록 noise를 injection 하는 것 - 따라서 training sample의 style information을 perturbing 하여 TTS 모델을 regularize 하는 Mix-Style Layer Normalization (MSLN)을 설계:
(Eq. 2) $\gamma_{mix}(w) = \lambda \gamma(w) + (1-\lambda)\gamma(\tilde{w}), \,\,\,\, \beta_{mix} = \lambda \beta(w) + (1-\lambda) \beta(\tilde{w})$
- $w$ : style vector, $\tilde{w}$ : $\tilde{w} = Shuffle(w)$로 얻어짐
- $\lambda \in \mathbb{R}^{B}$ : Beta 분포에서 sampling, $B$ : batch size
- $\lambda \sim Beta(\alpha, \alpha), \alpha \in (0, \infty)$는 original style과 shuffle style의 trade-off를 나타냄 - 최종적으로 generalizable style-agnostic hidden representation은:
(Eq. 3) $MixStyleLN(x,w) = \gamma_{min}(w) \frac{x-\mu}{\sigma} + \beta_{min}(w)$
- Layer Normalization은 lightweight learnable sacle vector $\gamma$, bias vector $\beta$를 사용하여 hidden activation과 최종 예측에 큰 영향을 미칠 수 있음:
- MSLN을 통해 결과적으로 모델은 perturbed style로 regularize 된 input feature를 refine 하고 generalizable style-invariant content representation을 학습
- Over-fitting을 방지하고 diversity를 보장하기 위해 shuffle vector를 Beta 분포에서 sampling 한 shuffle rate $\lambda$와 random mix 하여 style information을 perturb
- 이때 style-agnostic prosodic variation을 생성하기 위해 pitch predictor를 채택
- Generalizable content adaptor에서 MLSN을 활용함으로써 linguistic content-related variation을 global style attribute와 disentangle 할 수 있음
- 결과적으로 OOD custom style에 대해 TTS 모델의 generalization을 향상

- Multi-level Style Adaptor
- OOD custom voice에는 high dynamic style attribute (speaker identity, prosody, emotion)이 포함되어 있어 TTS 모델링과 transfer를 어렵게 함
- GenerSpeech는 global, local stylization을 위해 Multi-level Style Adaptor를 도입
- Global Representation
- Generalizable wav2vec 2.0 모델을 사용하여 speaker와 emotion acoustic condition을 포함한 global style characcteristic을 capture
- 이때 wav2vec 2.0 encoder 상단에 average pooling layer와 fully-connected layer를 추가하여 emotion classification으로의 fine-tuning이 가능
- AM softmax criteria는 downstream classification을 위한 loss function으로써 사용됨 - 결론적으로 fine-tuned wav2vec 2.0 모델은,
- Discriminative global representation $\mathcal{G}_{s}$와 $\mathcal{G}_{e}$를 생성하여 speaker와 emotion characteristic을 각각 모델링함
- Generalizable wav2vec 2.0 모델을 사용하여 speaker와 emotion acoustic condition을 포함한 global style characcteristic을 capture
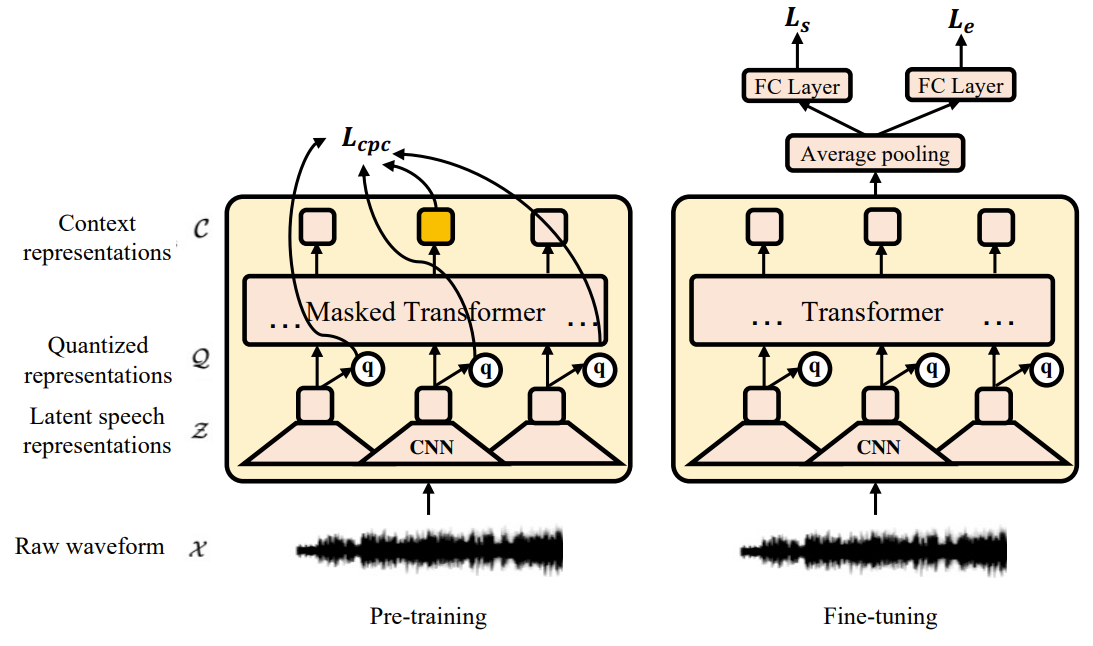
- Local Representation
- Fine-grained prosodic detail을 얻기 위해서 frame, phoneme, word-level의 3가지 acoustic condition을 고려
- 이러한 multi-level style encoder는 공통된 architecture를 사용
- Input sequence는 여러 convolutional layer를 통과하여 refine 됨
- 이때 다양한 level의 stylization을 위해 refined series에 대한 pooling operation을 수행
- Pooling operation은 input boundary에 따라 각 representation 내부의 hidden state를 평균화함 - 최종적으로 refined sequence는 bottleneck을 통해 vector quantization에 제공되어 non-prosodic information을 제거함
- 여기서 3-level prosodic condition은 다음과 같이 얻어짐:
- Frame level
- Frame-level latent representation $\mathcal{S}_{p}$를 capture 하기 위해 local style encoder에서 pooling layer를 제거 - Phoneme level
- Phoneme-level style latent representation $S_{p}$를 capture 하기 위해 phoneme boundary를 extra input으로 사용하고,
- Vector quantization layer 이전에 refined sequence에 대해서 pooling을 적용 - Word level
- Phoneme-level과 유사하게 word-level style latent representation $S_{w}$는 word boundary를 extra input으로 사용하고, pooling을 적용하여 sequence를 refine
- Frame level
- Vector Quantization block에서 refined sequence는 bottleneck을 통해 vector quantization에 제공되어 non-style information을 제거함
- 이때 vector quantization block의 bottleneck design은:
- Latent embedding space $e \in \mathbb{R}^{K \times D}$를 정의하자
- $K$ : discrete latent space size, $D$ : 각 latent embedding vector $e_{i}$의 dimension
- $K$개의 embedding vector $e_{i} \in \mathbb{R}^{D}, \, i \in 1, 2, ..., K$ - 이때 representation sequence가 embedding에 commit 되고 output이 증가하지 않도록 하기 위해서, commitment loss를 추가:
(Eq. 4) $\mathcal{L}_{c} = || z_{e}(x) - sg[e]||_{2}^{2}$
- $z_{e}(x)$ : vector quantization block, $sg$ : stop gradient operator
- Latent embedding space $e \in \mathbb{R}^{K \times D}$를 정의하자
- Style-to-Content Alignment Layer
- Variable-length local style representation을 phonetic representation $\mathcal{H}_{c}$와 align 하기 위해, Style-to-Content Alignment Layer를 도입하여 style과 content 사이의 alignment를 학습
- 이를 위해 Scaled Dot-Product Attention을 attention module로 활용
- Frame-level style encoder를 예시로 들면, $\mathcal{H}_{c}$가 query로 사용되고 $\mathcal{S}_{u}$가 key, value로 사용됨:
(Eq. 5) $Attention(Q,K,V) = Attention(\mathcal{H}_{c}, \mathcal{S}_{u}, \mathcal{S}_{u}) = Softmax \left( \frac{\mathcal{H}_{c}\mathcal{S}_{u}^{T}} {\sqrt{d}} \right) \mathcal{S}_{u}$ - Attention module에 입력되기 전에 style representation에 positional embedding을 추가함
- 추가적으로 residual connection을 사용하여 $\mathcal{H}_{c}$를 반영하고,
- Aligned representation이 linguistic content representation에서 그대로 copy 되는 것을 방지하기 위해 dropout이 적용됨 - 성능 향상을 위해 style-to-content alignment layer를 stack 하여 query를 점진적으로 stylize 함
- 결과적으로 style-specific prosodic variation을 생성하기 위해 pitch predictor를 도입
- Flow-based Post-Net
- Expressive custom voice에는 high dynamic variation이 포함되어 있지만, 일반적으로 사용되는 transformer decoder는 그러한 detailed mel-spectrogram sample을 생성하기 어려움
- 이를 위해 GenerSpeech는 Flow-based Post-net을 도입
- 합성된 mel-spectrogram의 품질과 similarity를 향상하고 mel-spectrogram decoder의 coarse-grained ouptut을 refine - Post-net architecture는 coarse-grained spectrogram과 mel decoder input을 condition으로 하는 Glow를 따름
- 학습과정에서 flow post-net은 합성된 mel-spectrogram을 Gaussian prior 분포로 변환하고, data의 exact log-likelihood를 계산
- 추론과정에서는 prior 분포에서 latent variable을 sampling 하고 post-net에 역으로 전달하여 expressive mel-spectrogram을 생성
- 이를 위해 GenerSpeech는 Flow-based Post-net을 도입
- Pre-training, Training and Inference Procedures
- Pre-training and Training
- GenerSpeech의 pre-training 단계에서는,
- AM softmax loss objective를 사용하여 global style encoder wav2vec 2.0 모델을 downstream task로 fine-tuning
- 이때 모든 parameter는 adjustable 하고 이후 discriminatively-trained wav2vec 2.0 모델에 대한 knowledge를 transfer 하여 global style feature를 생성 - GenerSpeech의 training 단계에서는,
- Reference와 target speech는 동일하게 유지됨
- 이때 최종적인 loss term은 다음과 같이 구성됨:- Duration prediction loss $\mathcal{L}_{dur}$ : log-scale에서 ground-truth phoneme-level duration과 예측값 사이의 MSE
- Mel-reconstruction loss $\mathcal{L}_{mel}$ : ground-truth mel-spectrogram과 transformer decoder에 의해 생성된 spectrogram 간의 MAE
- Pitch reconstruction loss $\mathcal{L}_{p}$ : ground-truth와 style-agnostic, style-specific pitch predictor에 의해 예측된 joint pitch spectrogram 간의 MSE
- Post-net의 negative log-likelihood $\mathcal{L}_{pn}$
- Commit loss $\mathcal{L}_{c}$ : (Eq. 4)에 따라 vector quantization layer를 제약하는 objective
- GenerSpeech의 pre-training 단계에서는,
- Inference
- GenerSpeech는 아래의 pipeline으로 OOD TTS를 위한 custom voice style transfer를 수행
- Text encoder는 phoneme sequence를 encoding 하고 expanded representation $\mathcal{H}_{c}$는 inference duraion에 따라 얻어짐
- Style-Agnostic Pitch (ASP) predictor는 custom style과 invariant 한 linguistic content speech variation을 생성 - Reference speech sample이 주어지면, forced alignment를 통해 word, phoneme boundary를 얻을 수 있고, 이는 style latent representation을 모델링하기 위해 Multi-level style adaptor에 제공됨
- Wav2vec 2.0 모델은 speaker $\mathcal{G}_{s}$, emotion $\mathcal{G}_{e}$ representation을 생성하여 global style을 제어
- Local style encoder는 frame, phoneme, word-level fine-grained style representation $\mathcal{S}_{u}, \mathcal{S}_{p}, \mathcal{S}_{w}$를 각각 capture
- 이후 Style-Specific Pitch (SSP) predictor가 style-sensitive variation을 생성 - Mel decoder는 coarse-grained mel-spectrogram $\tilde{M}$을 생성하고,
- Flow-based Post-net은 random sampled latent variable을 $\tilde{M}$과 mel decoder input에 따라 condition 된 fine-grained mel-spectrogram $M$으로 변환
- Text encoder는 phoneme sequence를 encoding 하고 expanded representation $\mathcal{H}_{c}$는 inference duraion에 따라 얻어짐
- GenerSpeech는 아래의 pipeline으로 OOD TTS를 위한 custom voice style transfer를 수행

3. Experiments
- Settings
- Dataset
- Pre-training : IEMOCAP, VoxCeleb1
- Training : LibriTTS
- Evaluation : ESD, VCTK - Comparisons : Mellotron, FG-TransformerTTS, Expressive FS2, Meta-StyleSpeech, STYLER
- Results
- Parallel Style Transfer
- Text가 reference utterance에서 변경되지 않은 경우에 대해 실험 결과를 비교
- 품질 측면에서 GenerSpeech는 VCTK에서 4.06, ESD에서 4.11의 MOS를 달성하여 가장 우수한 성능을 보임
- Style similarity 측면에서 GenerSpeech는 VCTK에서 4.01, ESD에서 4.20의 SMOS를 달성하여 마찬가지로 가장 우수한 성능을 보임
- Cos, FFE에 대한 정량적인 측면에서도 GenerSpeech의 custom voice style transfer 성능은 가장 우수한 것으로 나타남
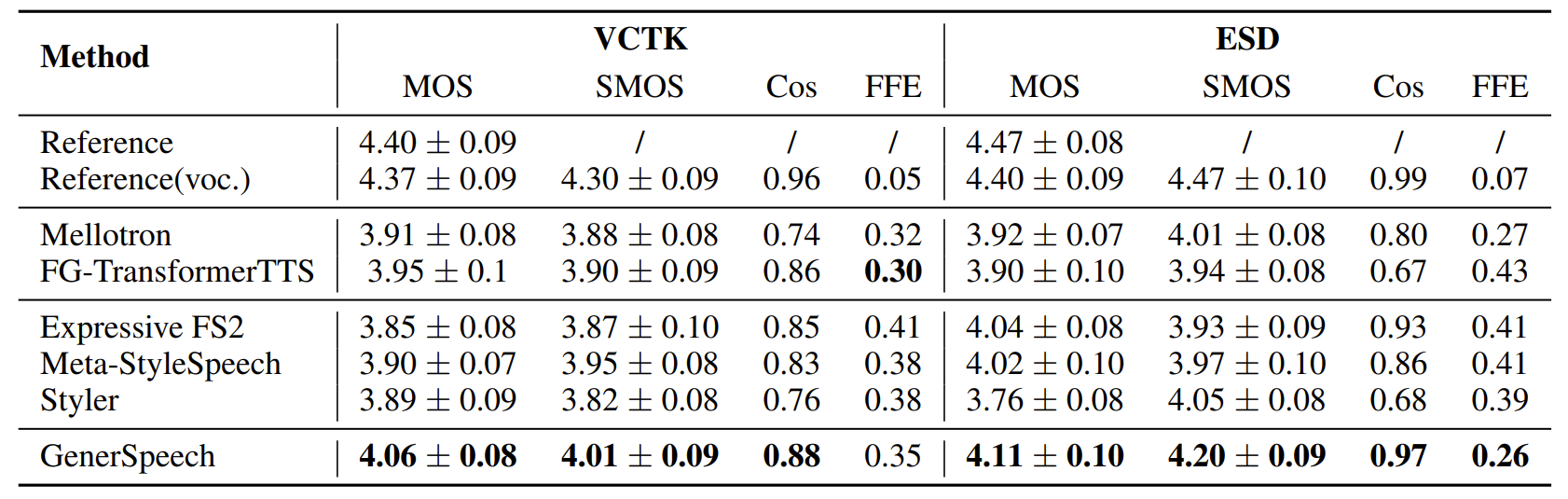
- Non-Parallel Style Transfer
- TTS 모델이 reference signal의 prosodic style로 다양한 text를 합성하는 non-parallel style tranfer에 대한 성능을 비교
- 결과적으로 GenerSpeech의 합성 sample이 다른 모델의 sample들에 비해 가장 선호되는 것으로 나타남
- 추가적으로 생성된 mel-spectrogram을 비교해 봤을 때,
- GenerSpeech는 adjacent harmonics, unvoiced frame, high-frequecny part에 대해 detail이 풍부한 mel-spectrogram을 생성함
- GenerSpeech는 reference signal의 prosodic style과 time-aligned 되는 pitch contour를 보임


- Ablation Study
- Multi-level Style Encoder, MSLN, Flow-based Post-net 모두 각각 제거했을 때 품질 저하가 발생함
- 결과적으로 GenerSpeech에서 채택한 방법들은 모두 품질 향상에 중요함

- Style Adaptation
- GenerSpeech는 adaptation data의 양이 늘어남에 따라 더 나은 성능을 발휘함
- 결과적으로 few-shot, zero-shot 환경에서도 GenerSpeech는 adaptive style transfer에 대한 우수한 성능을 발휘 가능

반응형
'Paper > TTS' 카테고리의 다른 글
댓글