

티스토리 뷰
Paper/TTS
[Paper 리뷰] TSP-TTS: Text-based Style Predictor with Residual Vector Quantization for Expressive Text-to-Speech
feVeRin 2024. 12. 22. 09:06반응형
TSP-TTS: Text-based Style Predictor with Residual Vector Quantization for Expressive Text-to-Speech
- Expressive text-to-speech는 다양한 speech style, emotion이 반영된 음성을 합성하는 것을 목표로 함
- TSP-TTS
- Text 자체에서 추출한 style representation을 기반으로 condition 된 expressive text-to-speech model
- Text-based style predictor를 위해 Residual Vector Quantization을 도입하고 mel-decoder에 Style-Text Alignment와 Style Hierarchical Layer Normalization을 적용
- 논문 (INTERSPEECH 2024) : Paper Link
1. Introduction
- Expressive Text-to-Speech (TTS)는 intensity, emotion, tone과 같은 style element를 speech에 반영할 수 있어야 함
- 이를 위해 기존의 expressive TTS model은 reference speech를 사용해 style을 conditioning 함
- 대표적으로 Global Style Token (GST)는 unsupervised learning을 사용하여 specific speech style을 추출함
- Meta-StyleSpeech의 경우 reference speech에서 style embedding을 추출하여 text encoder와 decoder에 conditioning 하는 방식을 사용함
- 특히 conditioning 과정에서 Style Adaptive Layer Norm (SALN)을 활용
- BUT, reference speech에 의존하는 expressive TTS model은 다음의 단점이 있음:
- 합성 품질이 inconsistent 하고 reference speech에 따라 달라짐
- 예상하지 못하는 다른 style을 적용하거나 완전히 다른 speaker를 반영할 수 있음 - Reference speech에 대한 sample을 준비하는 것이 번거로움
- 특히 GST의 경우 token을 clustering을 통해 학습하므로 어떤 style을 학습하는지 이해하기 어려움
- 합성 품질이 inconsistent 하고 reference speech에 따라 달라짐
- 이를 위해 기존의 expressive TTS model은 reference speech를 사용해 style을 conditioning 함
-> 그래서 expressive TTS에서 reference speech 의존성 문제를 해결한 TSP-TTS를 제안
- TSP-TTS
- Style module architecture를 text-based style predictor와 style extractor로 구성
- Text-based style predictor를 통해 reference speech 없이도 consistent 한 expressive speech를 합성 가능
- 추가적으로 emotion에 대한 style tag를 활용하여 accurate style prediction을 지원 - Style extraction을 위해 Residual Vector Quantization (RVQ)를 도입
- 해당 RVQ process를 repeating 함으로써 style information loss를 최소화해 style tag를 represent 함
- Text-based style predictor를 통해 reference speech 없이도 consistent 한 expressive speech를 합성 가능
- Mel decoder에는 style-text alignment와 Style Hierarchical Layer Normalization (SHLN)을 적용하여 style representation을 향상
- Style module architecture를 text-based style predictor와 style extractor로 구성
< Overall of TSP-TTS >
- Text 자체에서 추출한 style representation을 활용하는 expressive TTS model
- 결과적으로 reference speech 없이 text에 기반하여 기존보다 뛰어난 expressive speech를 생성
2. Method
- TSP-TTS는 text encoder, style module architecture, style-to-text alignment, variance adaptor, mel decoder with SHLN, post-net으로 구성됨

- Baseline TTS Model
- Baseline model로써 논문은 non-autoregressive model인 FastSpeech2 (FS2)를 채택함
- 구조적으로 FS2는 text encoder, mel decoder, pitch/energy/duration predictor로 구성됨
- 여기서 text encoder는 phoneme token을 처리하여 hidden state $h_{p}$를 생성하고, pitch $\hat{p}$, energy $\hat{e}$, duration $\hat{d}$를 예측함
- Pitch $p$는 PyWorld를 통해 derive 되고 duration $d$는 Montreal Forced Aligner (MFA)를 통해 얻어짐
- Mel decoder는 해당 frame-level representation을 mel-spectrogram $\hat{y}$로 변환함
- 결과적으로 baseline TTS loss $\mathcal{L}_{fs2}$는 ground-truth와 predicted value 간의 $L1, L2$ loss로 구성됨:
(Eq. 1) $\mathcal{L}_{fs2} = || y-\hat{y}||_{1}+ ||d-\hat{d}||_{2}+|| p-\hat{p}||_{2}+||e-\hat{e}||_{2}$
- $||\cdot ||_{1}, || \cdot ||_{2}$ : 각각 $L1, L2$ loss
- 구조적으로 FS2는 text encoder, mel decoder, pitch/energy/duration predictor로 구성됨
- Style Module Architecture
- Style Extractor
- Style extractor는 reference encoder와 RVQ로 구성됨
- Reference encoder는 RNN 기반의 convolution stack으로 구성되어 mel-spectrogram을 6개의 convolution layer를 통해 처리함
- Reshaping 이후 128-unit unidirectional Gated Recurrent Unit (GRU)을 통해 reference embedding을 생성하고, RVQ에 전달함 - RVQ는 style tag에 해당하는 codebook style embedding을 추출하는데 사용되고, codebook은 서로 다른 style을 represent 하는 distinct vector set을 의미함
- Reference encoder는 RNN 기반의 convolution stack으로 구성되어 mel-spectrogram을 6개의 convolution layer를 통해 처리함
- 이때 RVQ는 다음과 같이 style tag를 codebook 내의 most similar codebook vector에 mapping 함:
(Eq. 2) $q_{d}(r_{d})=s_{d}=e_{dj},\,\,\, \text{where}\,\,\, j=\arg\min_{k}|| r_{d}-e_{dk}||$
(Eq. 3) $r_{d}=r_{d-1}-q_{d-1}(r_{d-1})$
- $q_{d}(\cdot)$ : $d$-th residual vector $r_{d}$로 quantize 된 $d$-th RVQ - Residual vector는 quantization 이후 residual을 계산하여 얻어짐
- 이때 $r_{1}$는 reference encoder output이고 $e_{dk}$는 $d$-th codebook의 $k$-th embedding vector
- 따라서 $r_{d}$에 대한 closest embedding vector $e_{dj}$는 $d$-th style vetor $s_{d}$가 됨 - 7개의 style tag와 동일한 수의 codebook vector를 사용하고, style representation은 style tag와 codebook vector 간의 distance를 게산하고 style을 가장 잘 encapsulate 하는 codebook vector를 selecting 하여 얻어짐
- 결과적으로 RVQ는 hierarchical quantization을 통해 finer variation을 capture 하여 vector quantization 보다 더 precise 한 prediction이 가능함
- 이때 $r_{1}$는 reference encoder output이고 $e_{dk}$는 $d$-th codebook의 $k$-th embedding vector
- Codebook loss, commitment loss를 포함한 RVQ loss $\mathcal{L}_{rvq}$는:
(Eq. 4) $\mathcal{L}_{rvq}=|| \text{sg}[r_{d}]-q_{d}(r_{d})||_{2}^{2}+\beta || r_{d}-\text{sg}[q_{d}(r_{d})]||^{2}_{2}$
- $r_{d}$ : $d$-th residual vector
- $q_{d}(\cdot)$ : $d$-th residual vector에 대한 quantization process
- $\text{sg}[\cdot]$ : stop-gradient operation
- $\beta=0.2$ : commitment loss에 대한 weight
- Style extractor는 reference encoder와 RVQ로 구성됨
- Style Predictor
- Text-based style predictor는 reference speech를 사용하지 않고 style을 예측함
- 여기서 scaled dot-product attention에 기반한 cross-attention은 style tag를 query, $h_{p}$를 key, value로 사용하여 text를 style tag과 aligning 한 다음, style predictor의 input으로 사용함 - Style predictor는 style encoder와 마찬가지로 residual connection, multi-head attention, temporally average pooling을 포함한 CNN으로 구성됨
- 이때 input으로 mel-spectrogram 대신 phoneme embedding을 사용하고, phoneme embedding과 style tag는 sequential information을 capture 하기 위한 input으로 사용됨
- 추가적으로 global information을 반영하기 위해 multi-haed self-attention을 적용하고, temporally average pooling을 통해 self-attention mechanism의 output을 1D style vector로 condense 함
- Style predictor training을 위해 predicted style embedding $\hat{s}$와 reference style embedding $s$ 간의 $L1$ loss를 사용함:
(Eq. 5) $\mathcal{L}_{style}=|| s-\hat{s}||_{1}$
- Text-based style predictor는 reference speech를 사용하지 않고 style을 예측함
- Style-to-Text Alignment
- Alignment module은 text에 해당하는 style을 associate 하는 역할을 수행함
- 이때 TSP-TTS는 alignment module로써 dot-product attention mechanism을 채택함
- 즉, Style embedding을 $S$를 query, phoneme embedding $h_{p}$를 key/value, key dimension을 $d$라고 하면:
(Eq. 6) $\text{Attention}(Q,K,V)=\text{Attention}(S,h_{p},h_{p})=\text{Softmax}\left( \frac{S\cdot h_{p}^{T}}{\sqrt{d}}\right)h_{p}$
- 여기서 text, speech 모두 sequential 하므로 attention module 이전에 style representation에 positional encoding embedding을 적용함 - 결과적으로 style representation을 text에 aligning 하면 각 emotional expression의 nuance를 효과적으로 capture 할 수 있음
- 이때 TSP-TTS는 alignment module로써 dot-product attention mechanism을 채택함
- Mel Decoder with SHLN
- Mel Decoder는 multi-head attention과 layer normalization으로 구성된 feed-forward transformer (FFT)를 기반으로 함
- 이때 Style Adaptive Layer Normalization (SALN)은 layer normalization에서 style vector를 gain/bias로 사용하여 다양한 style의 mel-representation을 생성할 수 있음
- 이와 비슷하게 논문은 RVQ에서 derive 된 style vector를 integrate 하기 위해 Style Hierarchical Layer Nomalization (SHLN)을 도입함
- SHLN은 $s_{1},s_{2},s_{3},s$ 순으로 4개의 transformer layer에 hierarchically apply 됨
- 이를 통해 SHLN은 SALN 보다 더 extensive 한 style을 생성할 수 있음
- Training Stage of TSP-TTS
- TSP-TTS는 text encoder, variance adaptor, mel-decoder with SHLN, style module로 구성됨
- 이때 style module 내의 style extractor는 training phase에서만 사용됨
- 그러면 style loss $\mathcal{L}_{style}$은 style predictor를 학습하는데 사용되고 RVQ loss $\mathcal{L}_{rvq}$는 codebook style embedding을 학습하는데 사용됨
- Emotion classification loss $\mathcal{L}_{cls}$는 RVQ의 first output인 predicted style label과 style tag 간의 cross-entropy loss를 통해 계산됨
- 추가적으로 text에서 mel-spectrogram을 합성하기 위해 $\mathcal{L}_{fs2}$를 사용함
- 결과적으로 TSP-TTS의 total loss는:
(Eq. 7) $\mathcal{L}_{total} = \mathcal{L}_{fs2} +\lambda_{style}\mathcal{L}_{style}+\mathcal{L}_{rvq} +\mathcal{L}_{cls}$
- $\lambda_{style}=2$ : style loss의 scaling factor
- 이때 style module 내의 style extractor는 training phase에서만 사용됨
3. Experiments
- Settings
- Dataset : Korean Emotional Speech Dataset
- Comparisons : Tacotron2, StyleSpeech, Meta-StyleSpeech, FastSpeech2
- Results
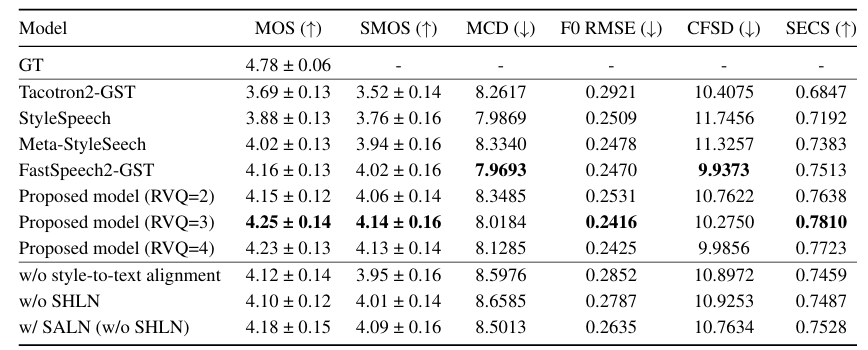
- 전체적으로 TSP-TTS가 가장 뛰어난 합성 품질을 보임
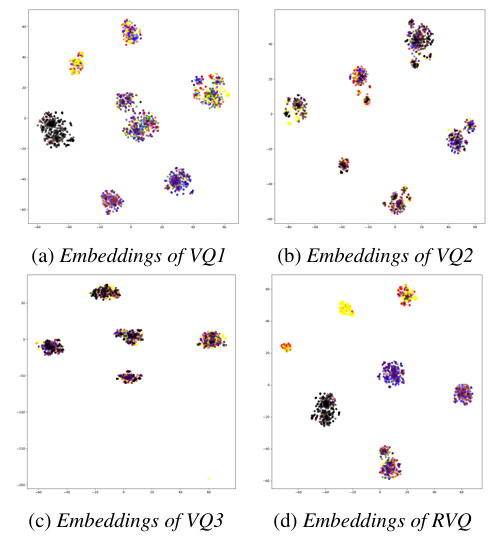
- Effect of Residual Vector Quantization
- RVQ의 효과를 확인하기 위해 $t$-SNE를 적용해 보면, (a)와 같이 서로 다른 emotion에 해당하는 distinct cluster가 나타남
- 특히 (d)와 같이 RVQ embedding과 결합해서 사용하는 경우, well-defined emotion classification result를 얻을 수 있음
- Unseen Data
- Unseen data에 대해서도 TSP-TTS가 가장 뛰어난 합성 품질을 보임

반응형
'Paper > TTS' 카테고리의 다른 글
댓글