

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] FlowDec: A Flow-Based Full-Band General Audio Codec with High Perceptual Quality
feVeRin 2025. 4. 12. 12:12반응형
FlowDec: A Flow-Based Full-Band General Audio Codec with High Perceptual Quality
- Lower bitrate에서도 동작하는 general full-band audio codec이 필요함
- FlowDec
- Non-adversarial codec training과 conditional flow matching에 기반한 stochastic postfilter를 활용
- Fine-tuning이나 distillation 없이 required postfilter evaluation을 절감
- 논문 (ICLR 2025) : Paper Link
1. Introduction
- Audio codec은 audio waveform을 compact, quantized representation으로 compress 하고, 해당 representation을 기반으로 audio waveform을 faithfully reconstruct 하는 것을 목표로 함
- BUT, 기존 codec은 ad-hoc design과 extensive manual effort가 필요하므로 12kbit/s 이하의 lower bitrate에서 high-fidelity audio coding을 위한 end-to-end optimization이 어려움
- 한편으로 SoundStream, DAC, AudioDec, EnCodec과 같은 End-to-End (E2E) Neural Codec은 8kbit의 lower bitrate에서도 우수한 audio quality를 달성함 - 특히 ScoreDec과 같이 score-based diffusion이나 flow-based generative model을 도입하여 reconstruction quality를 개선할 수 있음
- BUT, ScoreDec은 high-bitrate인 24kbit/s에서만 동작 가능하고 DNN evaluation으로 인한 Real-Time-Factor (RTF) 저하 문제가 있음
- BUT, 기존 codec은 ad-hoc design과 extensive manual effort가 필요하므로 12kbit/s 이하의 lower bitrate에서 high-fidelity audio coding을 위한 end-to-end optimization이 어려움
-> 그래서 lower bitrate에서도 효과적으로 동작하는 flow-based neural codec인 FlowDec을 제안
- FlowDec
- 기존 score-based method를 Conditional Flow Matching (CFM) method로 확장
- Fine-tuning, distillation 없이 DNN evaluation을 줄여 lower-bitrate, general full-band audio coding을 지원
< Overall of FlowDec >
- CFM에 기반한 full-band neural auido codec
- 결과적으로 RTF를 크게 개선하고 lower-bitrate에서 high-fidelity perceptual quality를 달성
2. Method
- 논문은 code $c:=E(x^{*})$가 주어진 clean audio $x^{*}\in\mathbb{R}^{L}$의 estimate $\hat{x}\in\mathbb{R}^{L}$을 reconstruct 하는 stochastic inference problem을 고려함
- 이때 model은 distribution에서 sampling을 통해 clean audio estimate $\hat{x}$를 제공하는 것을 목표로 함:
(Eq. 1) $\hat{x}\sim p_{\text{data}}(\hat{x}|c),\,\,\,c=E(x^{*})\in\mathbb{Z}^{\ell},\,\,\,\ell\ll L$
- $p_{\text{data}}(\cdot | c)$ : code $c$가 주어졌을 때 clean audio의 conditional distribution - $x^{*}\in\mathbb{R}^{L}$을 lower-dimensional discrete representation $c$로 mapping 하는 모든 encoder $E$는 many-to-one mapping이므로 multiple $x^{*}$은 same code $c$를 가짐
- 따라서 $D$가 one-to-one mapping인 경우 ideal property $D(E(x^{*}))=x^{*}$를 fullfilling 하는 것이 formally impossible 함
- 대신 (Eq. 2)를 minimizing 하여 $D$를 optimal estimator로 구성할 수 있음:
(Eq. 2) $\min_{D}\mathbb{E}_{x^{*}}\left[\text{dist}(D(E(x^{*})),x^{*})\right]$
- $\text{dist}$ : $L^{2},L^{1}$ distance와 같은 pairwise distance - BUT, 해당 방식으로 training 되는 경우 domain-specific loss가 있더라도 perceptually pleasing signal을 생성하지 못함
- 이를 해결하기 위해 SoundStream, EnCodec, DAC 등은 adversarial training loss를 도입하여 decoded signal distribution을 natural signal에 close 하도록 유도함
- BUT, adversarial training은 interpretability가 부족하고 $p(\hat{x}),p(x^{*})$ 간의 distance를 properly minimize 하지 못함 - 따라서 논문은 ScoreDec과 같이 $D$를 one-to-many mapping으로 구성함
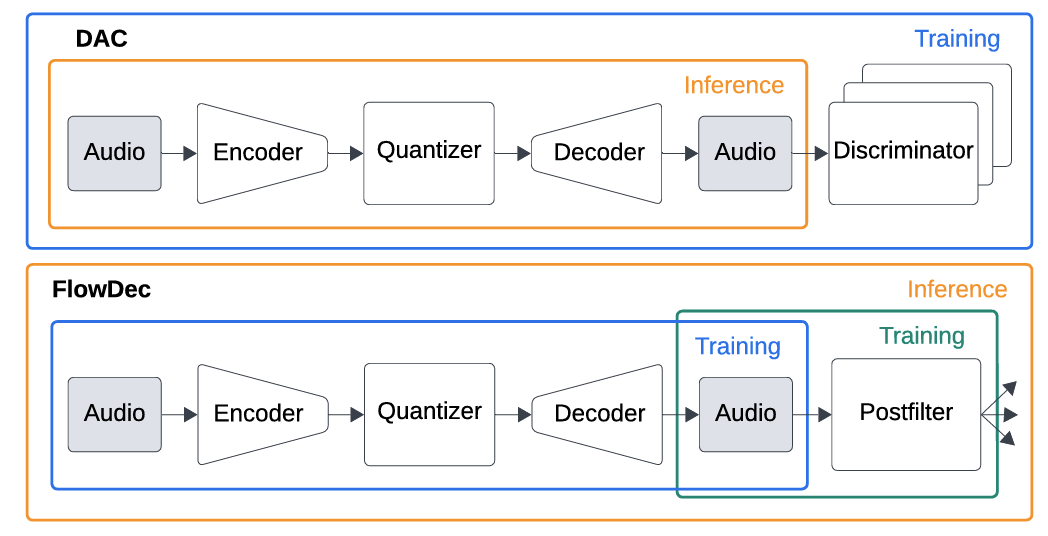
- 즉, FlowDec은 deterministic pre-trained initial decoder $D_{0}$와 stochastic postfilter $\Omega$를 combining 한 stochastic decoder $D_{s}(c)=\Omega(D_{0}(c))$의 형태로 구성됨
- 여기서 $y:=D_{0}(c)$라고 하면 $\Omega$는 learned distribution $p_{\Omega}(\cdot | y)$로부터 conditional sample $\hat{x}\sim p_{\Omega}(\hat{x}|y)$를 생성함
- 해당 sample은 statistical divergence $\mathcal{D}$를 mimimize 하여 intractable distribution $p_{\text{data}}(\cdot | y)$를 approximate 함
- 이때 model은 distribution에서 sampling을 통해 clean audio estimate $\hat{x}$를 제공하는 것을 목표로 함:
- Flow Matching
- Flow Matching은 tractable dsitribution $q_{0}(x_{0})$에서 intractable data distribution $q_{1}(x_{1})=p_{\text{data}}$로 sample을 transport 하는 model을 학습하는 것을 목표로 함
- 이때 Flow Matching은 sample $x_{0}\sim q_{0}$에서 시작하여 다음의 Ordinary Differential Equation (ODE)를 solve 함:
(Eq. 4) $\frac{d}{dt}\phi_{t}(x)=u_{t}(\phi_{t}(x)),\,\,\,\phi_{0}(x)=x_{0}$ - 여기서 $\phi_{t}:[0,1]\times \mathbb{R}^{N}\rightarrow \mathbb{R}^{N}$를 flow라 하고, time-dependent vector field $u_{t}:[0,1]\times \mathbb{R}^{N}\rightarrow \mathbb{R}^{N}$를 통해 $p_{t=0}=q_{0}, p_{t=1}=q_{1}$인 probability density path $p_{t}:\mathbb{R}^{N}\rightarrow \mathbb{R}_{>0}$을 생성함
- 그러면 $v_{\theta}$는 다음의 CFM training loss를 통해 학습됨:
(Eq. 5) $\mathcal{L}_{\text{CFM}}:=\mathbb{E}_{x,t,p_{t}(x|x_{1})}\left[|| v_{\theta}(x,t)-u_{t}(x|x_{1})||_{2}^{2}\right]$
- $x_{1}\sim q_{1}$
- 특히 conditional (Eq. 5)는 intractable unconditional flow matching objective와 동일한 gradient를 가지고 correct unconditional probability path $p_{t}(x)$와 flow field $u_{t}(x)$를 marginalize 함
- 이때 Flow Matching은 sample $x_{0}\sim q_{0}$에서 시작하여 다음의 Ordinary Differential Equation (ODE)를 solve 함:
- Joint Flow Matching for Signal Enhancement
- Original flow matching formulation에서 $x_{0},x_{1}$은 zero-mean Gaussian $q_{0}=\mathcal{N}(0,\sigma^{2}I)$에서 independently sampling 됨
- $q_{0}$가 standard Gaussian인 경우 conditional path $p_{t}(x|x_{1})$은 $q_{0}$에서 $q_{1}$으로의 Optimal Transport (OT)를 fulfill 하지만 modeled marginal probabilitiy path $p_{t}(x)$는 OT를 fulfill 하지 않음
- 결과적으로 learned marginal flow field $v_{\theta}$에서 high-variance training과 lower-straightness가 발생하므로 inefficient inference와 suboptimal sample quality가 나타남
- 이를 해결하기 위해 각 training batch $\{(x_{b,0},x_{b,1})\}_{b=1}^{B}$에서 pairing을 reorder 하고 각 batch에서 OT algorithm을 통해 optimal coupling을 결정하는 per-batch approximation을 도입할 수 있음
- 즉, $(x_{0},x_{1})\sim q(x_{0},x_{1})$을 independently sample 하지 않고 jointly sampling 함
- 특히 $(x_{0},x_{1})$를 jointly sampling 하면 OT solver나 extra computation이 필요하지 않음
- 이때 initial estimate $y=D_{0}(c)=D_{0}(E(x^{*}))$에 access 할 수 있으므로, 논문은 다음의 probability path를 choice 함:
(Eq. 6) $p_{t}(x_{t}|x_{1},y)=\mathcal{N}(x_{t};\mu_{t},\sigma_{t}):=\mathcal{N}( x_{t};y+t(x_{1}-y),(1-t)^{2}\Sigma_{y})$
- $\Sigma_{y}=\text{diag}(\sigma^{2}_{y})$ : diagonal covariance matrix - 해당 probability path는 $y, x_{1}$ 간의 linear interpolation에 해당하고, noise는 $\sigma_{y}$에서 $0$으로 linearly decrease 하므로 $x_{0},x_{1}$ 간에 $y$를 통한 coupling이 나타남
- 즉, $q_{0}(x_{0}|x_{1},y)=\mathcal{N}(x;y,\Sigma_{y})$인 경우 $x_{0}$의 mean은 $0$에서 $y$로 shift 됨
- 그러면 marginalized $q_{0}(x_{0})$는 아래 그림과 같이 variance가 $\sigma_{y}^{2}$이고 training data에 centered 된 Gaussian mixture로 볼 수 있음
- 이때 $\sigma_{y}$가 well-chosen 되어 Gaussian이 negligible overlap 되면 per-batch coupling을 통해 optimal 하다고 가정할 수 있으므로, mini-batch OT가 필요하지 않음
- 따라서 $\sigma_{y}$의 choice는 output quality에 큰 영향을 미침
- $q_{0}$가 standard Gaussian인 경우 conditional path $p_{t}(x|x_{1})$은 $q_{0}$에서 $q_{1}$으로의 Optimal Transport (OT)를 fulfill 하지만 modeled marginal probabilitiy path $p_{t}(x)$는 OT를 fulfill 하지 않음

- 결과적으로 conditional $u_{t}$는,
- Flow Matching을 따라 다음과 같이 derive 됨:
(Eq. 7) $u_{t}(x|x_{1},y)=\frac{x_{1}-x_{t}}{1-t}$ - $x_{t}$는 $x_{0}$를 통해 나타낼 수 있으므로:
(Eq. 8) $x_{t}=tx_{1}+(1-t)x_{0},\,\,\,x_{0}\sim\mathcal{N}(x_{0};y,\Sigma_{y})$
(Eq. 9) $\,\,\,\,\,\,\,=tx_{1}+(1-t)y+(1-t)\sigma_{t}\epsilon, \,\,\,\epsilon\sim\mathcal{N}(0,I)$
(Eq. 10) $x_{0}=y+\sigma_{y}\epsilon, \,\,\,\epsilon\sim\mathcal{N}(0,I)$ - (Eq. 6)을 따라 $x_{1}=x^{*}$을 대입하면 simple joint flow matching loss를 얻을 수 있음:
(Eq. 11) $\mathcal{L}_{\text{JFM}}:=\mathbb{E}_{t\sim\mathcal{U}(0,1), (x^{*},y)\sim\mathfrak{D}, \epsilon\sim\mathcal{N}(0,I), x_{t}\sim p_{t}(x_{t}|x_{0})}\left[\left|\left| v_{\theta}(x_{t},t,y)- ( \underset{=x_{1}}{\underbrace{x^{*}}}-\underset{=x_{0}}{\underbrace{(y+\sigma_{y}\epsilon)}} ) \right|\right|_{2}^{2}\right]$
- $\mathfrak{D}$ : training dataset - 해당 loss는 $x_{0},x_{1}$에 대해 reparameterize 함으로써 (Eq. 7)의 $t\approx 1$ 주변의 numerical stability를 제거함
- 특히 $\sigma_{y}>0$을 choice 하면 flow field가 contractive mapping이 되도록 force 할 수 있음
- 이를 통해 inference를 위한 ODE는 numerically stable 하고 locally converge 됨 - $p_{t}$에 대한 choice는 trajectory가 $x^{*}$에 exactly reach 하도록 하여 SGMSE를 개선함
- 기존 SGMSE는 correct $q_{0}$를 modeling 하지 않으므로 fail 할 수 있음
- 특히 $\sigma_{y}>0$을 choice 하면 flow field가 contractive mapping이 되도록 force 할 수 있음
- 추가적으로 논문은 multiple hyperparameter를 가지는 Stochastic Differential Equation (SDE) 대신, 하나의 hyperparameter $\sigma_{y}$ 만을 사용하는 data-based heuristic을 도입함:
(Eq. 12) $\sigma_{y}=\frac{1}{3}\sqrt{Q(|\mathbf{X}^{*}-\mathbf{Y} |^{2},0.997)}$
- $Q$ : quantile operation - 한편으로 independent CFM formulation을 사용하여 constant $\sigma_{t}=\sigma$를 얻고 sampled noise에 대해 target flow field $u_{t}$가 independent 하도록 할 수 있음
- BUT, 해당 방식은 $\sigma_{1}=\sigma>0$ 이므로 아래 그림과 같이 non-contractive flow field와 estimate에 residual noise가 나타남
- 반면 FlowDec은 $\sigma_{1}=0$이므로 postfiltering task에서 더 나은 quality를 달성할 수 있음
- Flow Matching을 따라 다음과 같이 derive 됨:

- FlowDec은 $x^{*},y$를 invertible feature extractor $\Phi$의 feature representation $\mathbf{X}^{*}, \mathbf{Y}$로 replace 하여 feature domain의 flow를 학습함
- 이때 $\Phi$는 compression exponent $\alpha=0.3$의 amplitude-compressed complex STFT를 채택함
- 추가적으로 input에서 channel-wise concatenate를 통해 $\mathbf{Y}$에 $v_{\theta}$의 conditioning을 제공함 - Training 이후 flow model $v_{\theta}$는 (Eq. 4)의 ODE와 함께 conditional distribution $p_{\Omega}(\mathbf{X}^{*}|\mathbf{Y})$를 modeling 함
- 이때 clean feature estimate $\hat{\mathbf{X}}\sim p_{\Omega}$를 생성하기 위해, initial state (latent) $\mathbf{X}_{0}\sim q_{0}(\mathbf{X}_{0}|\mathbf{Y})$를 sample 함
- 이후 $t=0$에서 $t=1$ 까지 $v_{\theta}$를 사용하여 numerical ODE solver를 통해 flow (Eq. 4)를 solve 하여 $\hat{\mathbf{X}}_{1}$을 구함
- 논문은 3-step Mid-point Solver ($\text{NFE}=6$)를 사용 - 최종적으로 feature extractor $\Phi$의 inverse를 사용하여 waveform estimate $\hat{x}=\Phi^{-1}(\hat{\mathbf{X}}_{1})$을 생성함
- 이때 $\Phi$는 compression exponent $\alpha=0.3$의 amplitude-compressed complex STFT를 채택함
- Non-Adversarial Codec Training
- Effective phase loss 없이 spectral loss 만으로 training 된 NAR audio generative model은 unsynchronized phase로 인한 buzzy noise가 발생함
- 이때 adversarial training을 도입하면 해당 문제를 해결하고 natural-sounding audio를 얻을 수 있음
- BUT, unstable training, mode-collapse, handcrafted multi-discriminator design 등의 문제가 발생함 - 따라서 논문은 adversarial training을 제거하는 대신 generative postfilter를 도입함
- 즉, adversarial loss 없이 deterministic neural codec을 initial decoder $D_{0}$로 training 하고 stochastic postfiler $\Omega$를 통해 output audio와 clean audio의 distribution을 matching 함
- 구조적으로는 DAC와 같은 neural codec을 $D_{0}$로 채택하고 adversarial loss term과 관련된 모든 component를 제거하여 사용함
- 이때 adversarial training을 도입하면 해당 문제를 해결하고 natural-sounding audio를 얻을 수 있음
- Underlying Codec: Improved Non-Adversarial DAC
- FlowDec의 stochastic postfilter는 ScoreDec과 같이 any underlying codec에 대해 training 되어 waveform estimate를 향상함
- 이때 다른 sampling rate, bitrate에 대한 adaptibility가 우수한 DAC를 underlying codec의 basis로 채택함
- 추가적으로 adversarial loss를 제거하고 아래 표와 같이 configuration을 modify 함 - 한편으로 해당 non-adversarial loss를 training 할 때 $-30\text{dB}$의 Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) value가 발생하는 경우가 있음
- 이는 low-frequency ($\leq 2\text{kHz}$)가 badly modeling 되기 때문으로, 논문은 Multiscale Constant-Q Transform (CQT) loss를 도입하여 해당 문제를 해결함
- 추가적으로 DAC의 multiscale Mel loss와 같이 amplitude와 log-amplitude의 difference를 모두 사용하고, SI-SDR과 phase error를 반영하는 $L^{1}$ waveform-domain loss를 추가함
- 이때 다른 sampling rate, bitrate에 대한 adaptibility가 우수한 DAC를 underlying codec의 basis로 채택함

- Frequency-Dependent Noise Levels
- $\sigma_{y}$ choice는 output quality에 큰 영향을 미침
- 이때 single scalar $\sigma_{y}$를 사용하면 added Gausian noise가 high-frequency를 dominate 할 때 over-smoothing이 나타날 수 있음
- 따라서 논문은 각 STFT frequency band에 대해 (Eq. 12)의 heuristic quantile calculation을 independently performing 하여 frequency-dependent curve $\sigma_{y}(f)$를 calculate 함
3. Experiments
- Settings

- Results
- 전체적으로 FlowDec이 가장 우수한 성능을 보임

- Perception-Distortion trade-off 측면에서도 FlowDec은 DAC 보다 더 robust 함

- ScoreDec과의 비교에서도 FlowDec이 더 뛰어남

- Spectrogram 측면에서도 FlowDec은 더 나은 reconstruction이 가능함

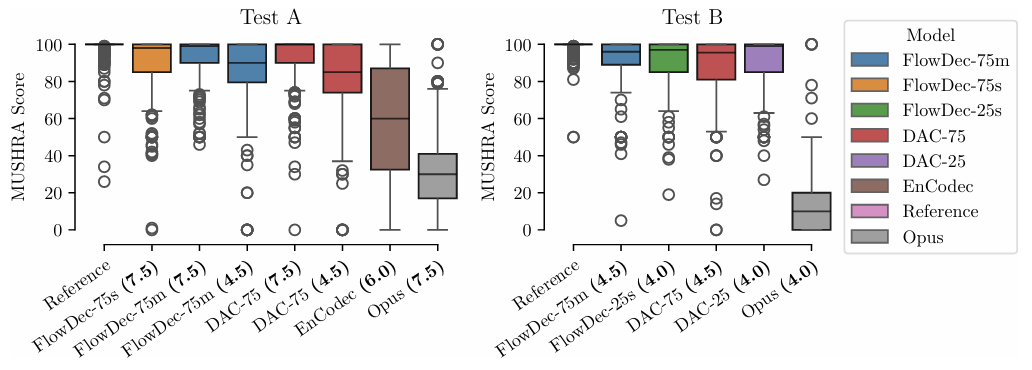
- Listening Test
- Subjective evaluation을 위한 listening test parameter는 아래 표와 같이 설정됨

- Subjective evaluation 측면에서도 FlowDec이 가장 우수함
- Real-Time-Factor (RTF)
- $\text{NFE}=6$의 default setting에서 FlowDec-75의 total RTF는 0.2285, FlowDec-25는 0.2235와 같음
- 즉, FlowDec은 ScoreDec의 1.707 RTF와 비교하여 상당한 RTF 개선을 보임
반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글