

티스토리 뷰
Paper/Neural Codec
[Paper 리뷰] FunCodec: A Fundamental, Reproducible and Integrable Open-Source Toolkit for Neural Speech Codec
feVeRin 2025. 4. 8. 19:57반응형
FunCodec: A Fundamental, Reproducible and Integrable Open-Source Toolkit for Neural Speech Codec
- SoundStream, EnCodec과 같은 neural codec에 대한 open-source toolkit이 필요함
- FunCodec
- Downstream task에 easily integrate 될 수 있는 open-source codec
- Lower computation, parameter complexity를 가지는 frequency-domain codec을 지원
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Speech codec은 speech를 compact representation으로 encode 하는 encoder와 reconstruct 하는 decoder로 구성됨
- 특히 SoundStream, EnCodec과 같은 neural codec은 Residual Vector Quantization (RVQ), Transformer architecture 등을 활용하여 구성됨
- 이러한 neural codec은 signal compression 외에도 discrete speech representation 추출을 위해 사용될 수 있음
- 대표적으로 VALL-E는 text, speech token sequence를 사용하여 zero-shot synthesis를 수행함 - BUT, 대부분의 speech codec은 reproducible 하지 않으므로 downstream task에서 활용하기 어려움
-> 그래서 open-source, reproducible codec toolkit인 FunCodec을 제안
- FunCodec
- Open-Source codebase를 통해 codec model의 활용도를 향상
- 추가적으로 더 적은 parameter를 가지는 frequency-domain codec인 FreqCodec을 지원
< Overall of FunCodec >
- 다양한 neural codec에 대한 reproducible, integrate open-source toolkit
- 특히 FreqCodec은 더 적은 complexity로 기존 수준의 reconstruction 성능을 달성 가능

2. Method
- Model Architecture
- FunCodec은 speech signal $x$가 주어지면 domain transformation module로 전달함
- 이때 SoundStream, EnCodec과 같은 time-domain model에 대해서는 identity mapping을 사용함
- Frequency-domain model의 경우 $X_{\text{mag, ang}},X_{\text{mag, pha}}$의 2가지 representation을 고려할 수 있음:
(Eq. 1) $X=\text{STFT}(x)$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, X_{\text{mag, ang}}=\log(|X|),\,\, \text{angle}(X_{i},X_{r})$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, X_{\text{mag, pha}}=\log(|X|),\,\,\frac{X_{r}}{|X|},\frac{X_{i}}{|X|}$
- $X_{r},X_{i}$ : complex spectrum의 real/imaginary part
- $|\cdot |$ : complex value에 대한 norm - Domain transformation module 이후에는, encoder를 사용하여 $V_{a}=\text{Encoder}(X)$와 같이 acoustic representation을 추출함
- Time-domain model인 경우, EnCodec, SoundStream과 동일한 SEANet architecture를 사용함
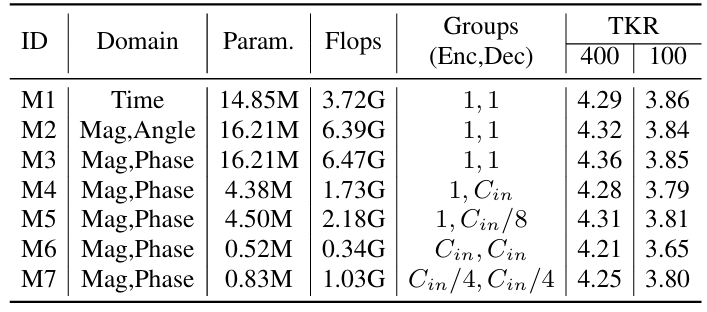
- Frequency-domain model (FreqCodec)의 경우, 아래 표와 같은 architecture를 채택함
- 최종적으로는 encoder의 mirror인 decoder와 domain-inverse module을 통해 raw waveform을 reconstruct 함

- Semantic-Augmented Residual Vector Quantization
- Discrete speech token을 얻기 위해, 여러 quantizer로 구성된 Residual Vector Quantization (RVQ) module을 사용함
- 이때 formulation은:
(Eq. 2) $Q_{n}=\text{VQ}\left(Q_{0}-\sum_{i=1}^{n-1}Q_{i}\right)$
- $Q_{n}$ : $n$-th vector quantizer output, $Q_{0}$ : RVQ input - 논문은 code utilization 향상을 위해 $k$-means를 통해 first mini-batch sample을 clustering 하여 VQ codebook을 initialize 한 다음, decay rate가 0.99인 moving average를 사용하여 update 함
- 여기서 mini-batch에서 code가 2번 미만으로 activate 되는 경우, reassign을 수행함 - Encoder output 외에도 다음과 같이 semantic information을 codec model에 incorporate 할 수 있음:
(Eq. 3) $f_{\text{cat}}(V_{a},V_{s})=\text{Concat}(\text{RVQ}(V_{a}),V_{s}),$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, f_{\text{add}}(V_{a},V_{s})=\text{RVQ}(V_{a})+V_{s},$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, f_{\text{res}}(V_{a},V_{s})=\text{RVQ}(V_{a}-V_{s})+V_{s}$
- $V_{s}$ : frame-aligned phoneme label, HuBERT embedding과 같은 semantic token - 추가적으로 variable bitrate에서 single model을 동작하기 위해, structured quantization dropout을 적용함
- 이때 formulation은:

- Adversarial Training Objective with Multiple Discriminators
- FunCodec의 training objective는 reconstruction loss, adversarial loss, RVQ commit loss로 구성됨
- 먼저 original speech $x$와 reconstructed $\hat{x}$ 간의 $L1$ distance $\mathcal{L}_{t}(x,\hat{x})=||x-\hat{x}||_{1}$를 time-domian에 따라 minimize 함
- Frequency-domain의 경우 multiple mel/magnitude spectra에 대해 $L1, L2$ distance를 minimize 함:
(Eq. 4) $\mathcal{L}_{f}(x,\hat{x})=\frac{1}{|\alpha|}\sum_{i\in\alpha}\left(|| \mathcal{S}_{i}(x)-\mathcal{S}_{i}(\hat{x})||_{1}+|| \mathcal{S}_{i}(x)-\mathcal{S}_{i}(\hat{x})||_{2} + || \mathcal{M}_{i}(x)-\mathcal{M}_{i}(\hat{x}) ||_{1}+|| \mathcal{M}_{i}(x)-\mathcal{M}_{i}(\hat{x})||_{2}\right)$
- $\mathcal{S}_{i},\mathcal{M}_{i}$ : 각각 window size $2^{i}$, shift length $2^{i}/4$에 대한 log-compressed power/mel-spectra
- $\alpha=[5,6,...,11]$로 설정
- 여기서 log-compressed power spectrum은 speech quality를 향상하는데 도움을 줌 - Adversarial loss의 경우, Multi-Scale Discriminator (MSD), Multi-Period Discriminator (MPD), Multi-Scale STFT Discriminator (MSTFTD)를 기반으로 feature matching loss를 추가적으로 활용함:
(Eq. 5) $\mathcal{L}_{\text{adv}}(\hat{x})=\mathbb{E}_{\hat{x}}\left[\frac{1}{K}\sum_{k,t}\frac{1}{T_{k}}\max(0,1-\mathcal{D}_{k,t}(\hat{x}))\right],$
$\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\, \mathcal{L}_{\text{feat}}(x,\hat{x})=\mathbb{E}_{x,\hat{x}}\left[\frac{1}{KL}\sum_{k,t,l}\frac{1}{T_{k}}|| \mathcal{D}_{k,t}^{(l)}(x)-\mathcal{D}_{k,t}^{(l)}(\hat{x})||_{1}\right]$
- $\mathcal{D}_{k,t}$ : timestep $t$에서 discriminator $k$의 output, $\mathcal{D}_{k,t}^{(l)}$ : layer $l$의 output - Commit loss는 whole RVQ module과 sub-quantizer의 quantization error를 사용함:
(Eq. 6) $\mathcal{L}_{\text{cm}}=|| V-\text{RVQ}(V)||_{2}+\frac{1}{N}\sum_{i=1}^{N}|| Q_{i-1}-\text{VQ}_{i}(Q_{i-1})||_{2}$
- $V$ : RVQ input으로써 semantic augmentation method에 따라 달라짐 - 결과적으로 total objective는:
(Eq. 7) $\mathcal{L}=\lambda_{t}\mathcal{L}_{t}+\lambda_{f}\mathcal{L}_{f}+ \lambda_{\text{adv}}\mathcal{L}_{\text{adv}}+\lambda_{\text{feat}} \mathcal{L}_{\text{feat}}+\lambda_{\text{cm}}\mathcal{L}_{\text{cm}}$
3. Experiments
- Settings
- Dataset : LibriSpeech, AISHELL-1, AISHELL-2, WeNet, GigaSpeech
- Comparisons : SoundStream, EnCodec
- Results
- 전체적으로 FunCodec의 성능이 가장 우수함

- Evaluation of Generalized Models on Multiple Corpus
- FunCodec은 다양한 token rate에 대해서도 consistent 한 compressed quality를 제공함

- Comparison of Frequency and Time Domain Models
- Higher token rate에서 frequency-domain model이 더 우수한 성능을 보임
- 특히 magnitude, normalized phase spectra의 사용이 magnitude, angle spectra 보다 더 적합함
- The Impact of Semantic Augmentation
- Semantic token에 대해 residual combination method를 사용하는 것이 효과적임

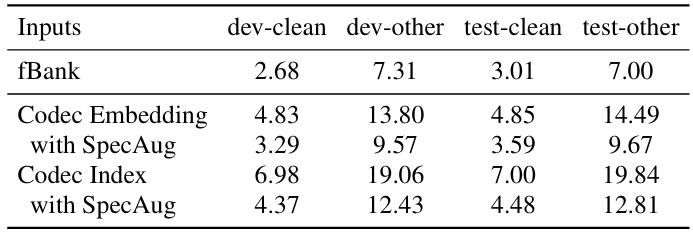
- Applying to Down-Stream Tasks
- ASR에 활용하는 경우, codec-based discrete input이 continuous fbank feature 보다 더 sensitive 함
반응형
'Paper > Neural Codec' 카테고리의 다른 글
댓글