
티스토리 뷰
Paper/Language Model
[Paper 리뷰] AudioGen: Textually Guided Audio Generation
feVeRin 2024. 3. 5. 10:41반응형
AudioGen: Textually Guided Audio Generation
- Text-to-Audio 생성에는 몇 가지 어려움이 있음
- 동시에 말하는 speaker를 분리하는 것과 같이 object를 구별하는 것이 어려움
- Scarce text annotation은 모델의 확장을 어렵게 함
- 고품질 audio 합성을 위해서는 높은 sampling rate가 필요하므로 sequence가 길어짐 - AudioGen
- Learnt discrete audio representation을 기반으로 동작하는 autoregressive 모델
- 다양한 audio sample을 mix 하여 모델이 source 분리를 internally learn 하는 augmentation을 도입
- 빠른 추론을 위해 multi-stream 모델링을 채택하고 text condition을 따르도록 유도하는 Classifier Free-Guidance를 도입
- 논문 (ICLR 2023) : Paper Link
1. Introduction
- 이미지 생성에서 주로 활용되는 textually guided generative model을 audio 생성으로 확장할 수 있음
- 이미지와 audio 생성은 공통점이 많지만, 아래의 주요한 차이점이 존재함
- Audio는 1D signal이므로 overlapping object를 구별할 수 있는 degrees of freedom이 낮음
- Psychoacoustic과 Psychovisual property는 서로 다름
- Textual description이 포함된 audio dataset은 availability가 떨어짐
- 위의 한계점들로 인해 unseen audio composition을 구성하는 것은 어려움
- 이미지와 audio 생성은 공통점이 많지만, 아래의 주요한 차이점이 존재함
-> 그래서 descriptive text condition을 기반으로 고품질의 audio sample을 생성할 수 있는 AudioGen을 제안
- AudioGen
- Autoregressive textually guided audio generative model을 기반으로 두 가지 주요 stage로 구성됨
- Neural audio compression model을 사용하여 raw audio를 discrete token sequence로 encoding
- 해당 모델은 perceptual loss를 추가하여 compressed representation에서 input audio를 reconstruction 하는 end-to-end 방식으로 학습됨 - 1단계에서 얻은 discrete audio token에서 동작하고 textual input에 따라 condition 되는 autoregressive Transformer-decoder Language Model을 활용
- T5로 pre-train 된 text encoder를 사용하여 text의 large corpus를 represent 하고 current text-audio dataset에 없는 text concept을 generalization
- Neural audio compression model을 사용하여 raw audio를 discrete token sequence로 encoding
- 결과적으로 compact 하면서도 고품질의 audio sample을 생성하고 제한적인 text annotation으로도 다양성을 확보
- Autoregressive textually guided audio generative model을 기반으로 두 가지 주요 stage로 구성됨
< Overall of AudioGen >
- Textual description이나 audio prompt를 condition으로 하는 autoregressive audio generation model
- Audio language model에 classifier free-guidance를 적용하여 text adherence를 보장
- Text condition/uncondition audio continuation으로 확장
- Residual vector quantization과 multi-stream transformer를 활용하여 audio-fidelity와 sampling time간의 trade-off를 explore
2. Method
- AudioGen의 training은 two-stage로 구성됨
- Autoencoding을 통해 raw audio의 discrete representation을 학습하는 단계
- Textual feature에 따라 audio encoder에서 얻은 learnt code에 대해 Transformer Language Model을 training 하는 단계
- 추론 시에는 language model에서 sampling을 통해 text feature가 주어진 audio token set을 생성함
- 해당 token은 위 1단계의 decoder를 사용하여 waveform domain으로 decoding 됨
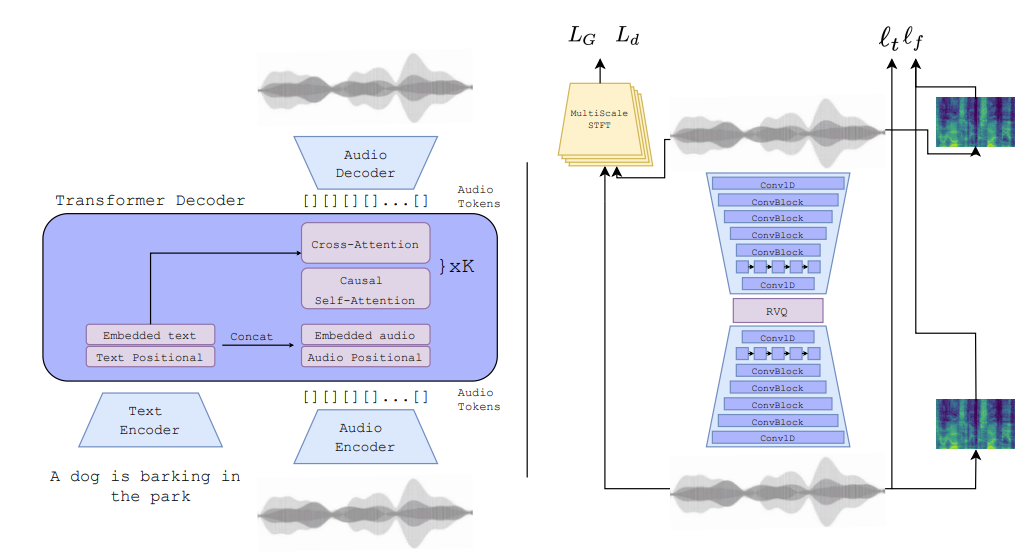
- Audio Representation
- Duration $d$의 audio signal은 audio channel 수 $C_{a}$, sampling rate $f_{sr}$에서의 audio sample 수$T=d\cdot f_{sr}$에 대해 $x \in [-1,1]^{C_{a}\times T}$ sequence로 represent 될 수 있음
- 이때 audio representation model은 아래 3가지 component로 구성됨:
- Audio segment를 input으로 하고 latent representation $z$를 output 하는 encoder network $E$
- Vector Quantization layer를 사용하여 compressed representation $z_{q}$를 생성하는 quantization layer $Q$
- Compressed latent representation $z_{q}$로부터 time-domain signal $\hat{x}$를 reconstruct 하는 decoder network $G$
- 전체 모델은 서로 다른 temporal resolution에서 동작하는 여러 discriminator의 perceptual loss와 함께 time, frequency domain 모두에 적용되는 reconstruction loss를 최소화하도록 end-to-end training 됨
- Pre-trained model을 사용하여 encoder와 quantizer component를 discrete feature extractor $Q \circ E$로 활용하고 $G$를 통해 representation을 time-domain signal로 decode 할 수 있음
- 여기서 $Q$의 경우 2048개의 code가 있는 single codebook을 사용하고 이때 각 code는 128 dimensional vector
- 이때 audio representation model은 아래 3가지 component로 구성됨:
- Architecture
- AudioGen은 autoencoder model architecture를 활용함
- Encoder $E$는 $C$ channel의 1D convolution이 있는 $B$ convolutional block으로 구성됨
- 각 convolution block은 single residual unit과 stride $S$의 2배 kernel size $K$를 가지는 strided convolution을 가지는 down-sampling layer로 구성됨
- Residual unit은 2개의 convolution과 skip connection이 포함되고, downsampling이 적용될 때마다 channel 수는 2배로 늘어남
- Convolutional bloack 다음에는 sequence 모델링을 위한 2-layer LSTM과 kernel size 7, output size $D$인 final 1D convolution layer가 적용됨 - Decoder는 strided convolution 대신 transposed convolution을 사용하고, encoder를 mirror 하여 최종 audio를 output 함
- Encoder $E$는 $C$ channel의 1D convolution이 있는 $B$ convolutional block으로 구성됨
- 전체적으로는 ELU activation과 LayerNorm이 적용됨
- AudioGen은 autoencoder model architecture를 활용함
- Training Objective
- Reconstruction loss와 adversarial loss의 조합을 jointly minimize 하는 GAN-based training objective를 사용
- Time-domain에서는 target audio와 reconstructed audio 간의 $L1$ distance를 최소화함:
$\ell_{t}(x,\hat{x})=||x-\hat{x}||_{1}$ - Frequency-domain은, 여러 time scale에 대해 mel-spectrogram의 $L1, L2$ loss 간의 linear combination을 사용:
(Eq. 1) $\ell_{f}(x,\hat{x})=\frac{1}{|\alpha|\cdot |s|}\sum_{\alpha_{i}\in \alpha}\sum_{i\in e}|| \mathcal{S}_{i}(x)-\mathcal{S}_{i}(\hat{x})||_{1}+\alpha_{i}|| \mathcal{S}_{i}(x)-\mathcal{S}_{i}(\hat{x})||_{2}$
- $\mathcal{S}_{i}$ : window size가 $2^{i}$이고 hop length가 $2^{i}/4$인 normalized STFT를 사용하는 64-bin mel-spectrogram
- $e=5,...,11$ : scale set, $\alpha$ : $L1, L2$ term 간의 balancing scalar coefficient
- Time-domain에서는 target audio와 reconstructed audio 간의 $L1$ distance를 최소화함:
- 생성된 sample의 품질을 향상하기 위해 multi-scale STFT (MS-STFT) discriminator를 추가적으로 최적화함
- Multi-scale discriminator는 audio signal의 다양한 structure를 capture 할 수 있다는 장점이 있음
- 구조적으로는 실수부와 허수부가 concatenate 되는 multi-scaled complex-valued STFT에서 동작하는 identically structured network를 활용 - Generator에 대한 adversarial loss는:
$\ell_{g}(\hat{x})=\frac{1}{K}\sum_{k}\max(0,1-D_{k}(\hat{x}))$
- $K$ : discriminator 수 - 이때 generator에 대한 feature matching loss를 추가함:
(Eq. 2) $\ell_{feat}(x,\hat{x})=\frac{1}{KL}\sum_{k=1}^{K}\sum_{l=1}^{L}|| D_{k}^{l}(x)-D_{k}^{l}(\hat{x})||_{1}$
- $(D_{k})$ : discriminator, $L$ : discriminator의 layer 수
- Multi-scale discriminator는 audio signal의 다양한 structure를 capture 할 수 있다는 장점이 있음
- 따라서 discriminator의 final loss는:
$L_{d}(x,\hat{x})=\frac{1}{K}\sum_{k=1}^{K}\max(0,1-D_{k}(x))+\max(0,1+D_{k}(\hat{x}))$
- 이때 generator의 loss $L_{G}=\lambda_{t}\cdot \ell_{t}(x,\hat{x})+\lambda_{f}\cdot \ell_{f}(x,\hat{x})+\lambda_{g}\cdot \ell_{g}(\hat{x})+\lambda_{feat}\cdot \ell_{feat}(x,\hat{x})$도 동시에 최적화됨
- Reconstruction loss와 adversarial loss의 조합을 jointly minimize 하는 GAN-based training objective를 사용
- Audio Language Modeling
- AudioGen의 목표는 text에 condition 된 audio를 생성하는 것
- 특히 textual input $c$가 주어지면 Audio Language Model (ALM)은 decoder $G$를 사용하여 raw audio로 decoding 될 수 있는 audio token sequence $\hat{z}_{q}$를 output 함
- Raw text input을 semantic dense representation $F(c)=u$로 mapping 하는 text encoder $F$가 있다고 하자
- 그러면 Look-up-Table (LUT)는 audio token $\hat{z}_{q}$를 continuous space $LUT(\hat{z}_{q}) =v$에 embed 함
- 이후 $u, v$를 concatenate 하여 $Z=u_{1},...,u_{T_{u}},v_{1},...,v_{T_{v}}$를 얻을 수 있음
- $T_{u}, T_{v}$ : 각각 text representation, audio representation의 length
- 위의 representation을 기반으로 cross-entropy loss를 사용하여 $\theta$로 parameterize 된 Transformer-decoder Language Model (LM)을 training 함:
(Eq. 3) $L_{LM}=-\sum_{i=1}^{N}\sum_{j=1}^{T_{v}}\log p_{\theta}(v_{j}^{i}|u_{1}^{1},...,u_{T_{u}}^{i},v_{1}^{1},...,v_{j-1}^{i})$ - Text representation은 pre-trained T5 text-encooder를 통해 얻어짐
- 추가적으로 LUT를 사용하여 text embedding을 적용할 수 있지만, T5 encoder에 비해 generalization이 떨어지는 것으로 나타남 - Transformer-decoder Language Model은 GPT2와 유사한 architecture를 활용함
- 이때 더 나은 text adherence를 위해 각 attention block에 audio와 text 간의 cross-attention을 추가
- 특히 textual input $c$가 주어지면 Audio Language Model (ALM)은 decoder $G$를 사용하여 raw audio로 decoding 될 수 있는 audio token sequence $\hat{z}_{q}$를 output 함
- Classifier Free-Guidence
- Classifier Free-Guidance (CFG)를 사용하면 sample 품질과 다양성 간의 trade-off를 제어할 수 있음
- 일반적으로 CFG는 diffusion model의 score function 추정을 위해 사용되었지만, AudioGen에서는 이를 autoregressive model로 확장 - 따라서 이를 기반으로 training 중에 conditional/unconditional 하게 Transformer-LM을 최적화
- 실적용에서는 training sample의 10%에 대한 text conditioning을 randomly omit 함 - 추론 시에는 conditional/unconditional probability의 linear combination으로 얻어진 분포를 활용하여 sampling을 수행:
(Eq. 4) $\gamma \log p_{\theta}(v_{j}^{i}|u_{1}^{1},...,u_{T_{u}}^{i},v_{1}^{1},...,v_{j-1}^{i})+(1-\gamma)\log p_{\theta}(v_{j}^{i}|v_{1}^{1},...,v_{j-1}^{i})$
- $\gamma$ : guidance scale
- Classifier Free-Guidance (CFG)를 사용하면 sample 품질과 다양성 간의 trade-off를 제어할 수 있음
- Multi-stream Audio Inputs
- 고품질 audio를 생성하기 위해, raw audio를 32배로 downsampling 함
- 결과적으로 audio가 $500 \, \textrm{token/sec}$로 represent 되므로 AudioGen은 매우 긴 sequence를 처리해야 함
- 따라서 긴 sequence를 효율적으로 처리하기 위해, multi-stream representation과 모델링을 도입
- 특히 AudioGen에서 채택된 transformer는 multiple stream을 simulataneous 하게 모델링할 수 있다는 장점이 있음 - $T_{v}$ length를 가진 sequence가 있다고 하자
- 그러면 동일한 bit-rate의 2개 paralle stream을 사용하여 length $T_{v}/2$의 representation을 학습할 수 있음
- 따라서 이를 $k$개 stream으로 generalize 하면, 각 stream length를 $T_{v}/k$, 각 codebook size를 $2048/k$로 represent 가능
- 위의 representation은 single codebook vector-quantization에서 Residual Vector Quantization module로 $Q$를 generalizing 함으로써 얻어짐
- 이를 위해 time $t$에서 network에는 $k$ discrete code가 제공되면 $k$ embedding layer를 사용하여 embedding 됨
- 이때 time $t$에서의 final embedding은 해당 $k$ embedding의 평균 - 이후 $k$ LM prediction head를 사용하여 $k$ code를 output 하도록 network를 adapt 함
- 이때 prediction head는 서로 independent 하게 동작함
- 이를 위해 time $t$에서 network에는 $k$ discrete code가 제공되면 $k$ embedding layer를 사용하여 embedding 됨
- 고품질 audio를 생성하기 위해, raw audio를 32배로 downsampling 함
3. Experiments
- Settings
- Dataset : AudioSet, BBC Sound Effects, AudioCaps, Clotho v2, VGG-Sound, FSD50K, Free To Use Sounds, Sonniss Game Effects, WeSoundEffects, Paramount Motion-Oden Cinematics Sound Effects
- Comparisons : DiffSound
- Results
- AudioGen은 더 적은 parameter 수를 가지지만 DiffSound 보다 뛰어난 합성 품질을 보임

- Audio Continuation 측면에서 비교해 보면
- (a) 생성 결과를 SRC, RND에 해당하는 audio와 비교, (b) RND text를 통한 생성 audio에 대해 text condition 여부에 따른 결과를 비교, (c) SRC text를 통한 생성 audio에 대해 text condition 여부에 따른 생성 결과를 비교
- 결과적으로
- 짧은 audio prompt를 사용함으로써 생성 결과를 conditioning text로 잘 유도할 수 있음
- 긴 audio prompt를 사용하면 textual guidance를 위한 공간이 줄어드는 것으로 나타남

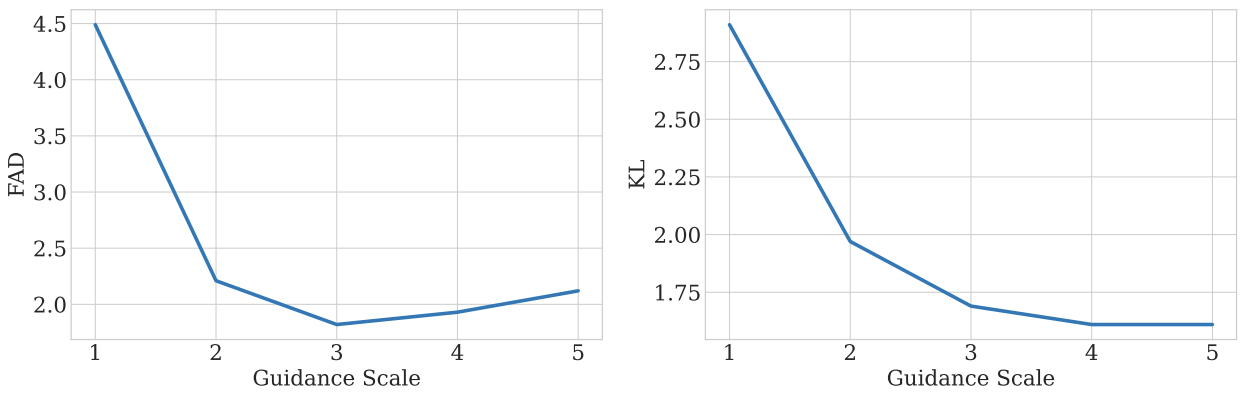
- Guidance를 사용하지 않는 $\gamma = 1.0$의 경우 그렇지 않은 경우에 비해 성능이 크게 저하됨
- $\gamma = 3.0$일 때 품질과 다양성 측면에서 최적의 결과를 제공
- Audio representation의 품질을 비교해 보면
- Single stream encoder는 SI-SNR을 측면에서 조금 더 우수하지만 ViSQOL이 나타내는 perceptual 품질 측면에서는 큰 차이를 보이지 않음
- 즉, multi-stream encoder를 사용하면 합성 품질의 큰 저하 없이 생성 가속 효과를 얻을 수 있음

반응형
'Paper > Language Model' 카테고리의 다른 글
| [Paper 리뷰] Textually Pretrained Speech Language Models (0) | 2024.03.31 |
|---|---|
| [Paper 리뷰] AudioLM: A Language Modeling Approach to Audio Generation (0) | 2024.03.10 |
| [Paper 리뷰] MusicLM: Generating Music From Text (0) | 2024.03.09 |
| [Paper 리뷰] Pengi: An Audio Language Model for Audio Tasks (0) | 2024.03.07 |
| [Paper 리뷰] Simple and Controllable Music Generation (0) | 2024.03.04 |
댓글