
티스토리 뷰
반응형
Simple and Controllable Music Generation
- Conditional music generation을 위해 Language Model (LM)을 도입
- MusicGen
- Token interleaving pattern을 활용하는 single-stage transformer LM으로 구성하여 cascading한 model 구성을 회피
- Textual description이나 melodic feature를 condition으로 하여 고품질 음성을 생성 가능
- 논문 (NeurIPS 2024) : Paper Link
1. Introduction
- Text-to-Music은 text description이 주어지면 그에 해당하는 음악을 생성하는 작업
- 일반적으로 음악을 생성하는 것은 long-range sequence를 모델링해야 하기 때문에 어려움이 있음
- 음성과 달리 음악은 전체 frequency spectrum을 요구하므로 더 높은 sampling rate가 필요함
- 다양한 악기의 harmony와 melody를 포함하는 복잡한 structure를 모델링할 수 있어야 함
- Key, Genre, Melody 등 다양한 condition에 대한 제어 능력도 요구됨 - Self-supervised audio representation learning과 Sequential modeling의 발전은 text-to-music 모델을 지원하고 있음
- 특히 audio signal을 동일한 signal을 나타내는 discrete token의 multiple stream으로 표현하면 audio 모델링을 tractable 하게 만들 수 있음 - BUT, 위 방식은 고품질 생성과 효과적인 audio 모델링을 가능하게 하지만, 높은 계산 비용을 가진다는 단점이 존재
- 일반적으로 음악을 생성하는 것은 long-range sequence를 모델링해야 하기 때문에 어려움이 있음
-> 그래서 textual description이 주어졌을 때 고품질 음악 합성을 지원하는 simple, controllable 음악 생성 모델인 MusicGen을 제안
- MusicGen
- Audio token의 multiple parallel stream을 모델링하는 framework를 제안
- Codebook interleaving strategy를 통해 single-stage language model만으로 consistent 한 음악을 생성 가능 - 해당 framework를 기반으로 추가적인 계산 비용 없이 stereo audio 생성으로 확장
- 생성된 sample의 controllability 향상을 위해 unsupervised melody conditioning을 추가로 도입
- Audio token의 multiple parallel stream을 모델링하는 framework를 제안
< Overall of MusicGen >
- 32kHz에서 고품질의 음악을 생성하는 simple한 모델
- Text, melody-conditioned 생성 모두를 지원하고 제공된 melody와 text conditiong을 충실히 반영 가능
- 결과적으로 다른 비교 모델에 비해 우수한 합성 품질을 달성
2. Method
- MusicGen은 text/melody representation으로 condition 된 autoregressive transformer-based decoder로 구성됨
- Language Model (LM)은 low frame rate discrete representation에서 high-fidelity reconstruction을 제공하는 EnCodec audio tokenizer의 quantized unit을 사용
- 이때 compression model은 Residual Vector Quanitzation을 사용하여 parallel stream을 생성함
- 여기서 각 stream은 서로 다른 learned codebook에서 얻어지는 discrete token으로 구성됨 - 이러한 token을 모델링하기 위해, MusicGen은 codebook interleaving pattern을 generalize 하는 framework를 도입
- 결과적으로 pattern을 통해 quantized audio token의 internal structure를 활용할 수 있음 - 마지막으로 MusicGen은 text/melody를 기반으로 conditional generation을 지원함
- Audio Tokenization
- MusicGen은 Residual Vector Quantization (RVQ)를 사용한 quantized latent space와 adversarial reconstruction loss를 가지는 convolutional autoencoder인 EnCodec을 사용
- Audio duration $d$와 sample rate $f_{s}$를 가지는 reference audio random variable $X \in \mathbb{R}^{d\cdot f_{s}}$가 주어지면 EnCodec은 이를 frame rate $f_{r} \ll f_{s}$의 continuous tensor로 encoding 함
- 이후 해당 representation은 $Q \in \{1,..., M\}^{d \cdot f_{r}\times K}$로 quantize 됨
- $K$ : RVQ에 사용되는 codebook 수, $M$ : codebook size - Quantization 이후에는 각 length가 $T=d\cdot f_{r}$인 $K$개의 parallel discrete token sequence가 얻어짐
- RVQ에서 각 quantizer는 previos quantizer에서 남겨진 quantization error를 encoding 하기 때문에, 서로 다른 codebook에 대한 quantized value는 non-independent 하므로 first codebook의 중요도가 높음
- Codebook Interleaving Patterns
- Exact Flattened Autoregressive Decomposition
- Autoregressive model은 sequence length $S$를 가지는 discrete random sequence $U\in \{ 1,...,M\}^{S}$를 필요로 함
- 일반적으로 sequence의 시작을 나타내는 deterministic special token $U_{0}=0$를 사용하여 분포를 모델링할 수 있음:
(Eq. 1) $\forall t>0, \,\, p_{t}(U_{t-1},...,U_{0}) \triangleq \mathbb{P}[U_{t}|U_{t-1},...,U_{0}]$ - Autoregressive density $p$를 사용하여 random variable의 second sequence $\tilde{U}$를 build 하기 위해, 모든 $t>0$에 대해 reculsive하게 $\tilde{U}_{0} =0$을 정의하면:
(Eq. 2) $\forall t>0, \,\, \mathbb{P}[\tilde{U}_{t}|\tilde{U}_{t-1},...,\tilde{U}_{0}]=p_{t}(\tilde{U}_{t-1},...,\tilde{U}_{0})$ - 결과적으로 $U$와 $\tilde{U}$는 동일한 분포를 따름
- 즉, $p$의 완벽한 추정치 $\hat{p}$를 fit 할 수 있다면, $U$의 분포를 정확하게 찾을 수 있다는 것을 의미함
- 일반적으로 sequence의 시작을 나타내는 deterministic special token $U_{0}=0$를 사용하여 분포를 모델링할 수 있음:
- 이때 EnCodec 모델에서 얻어진 representation $Q$는 각 time step마다 $K$개의 codebook이 존재한다는 문제가 있음
- 따라서 $Q$를 flatten 한 $S=d\cdot f_{r}\cdot K$를 취하는 것으로 이를 해결할 수 있음
- 먼저 first time step의 first codebook을 예측한 다음, first time step의 second codebook을 예측함
- 이후 (Eq. 1), (Eq. 2)를 사용하여 $Q$ 분포에 대한 exact model을 fit 할 수 있음
- BUT, lowest sample rate $f_{r}$에서 얻어지는 gain의 일부가 손실되어 complexity가 증가한다는 단점이 있음
- 하나 이상의 possible flattening이 존재하는 경우, 모든 $\hat{p}_{t}$ function이 single model을 통해 추정될 필요는 없음
- 이 경우, autoregressive step의 수는 $df_{r} \cdot K$
- Autoregressive model은 sequence length $S$를 가지는 discrete random sequence $U\in \{ 1,...,M\}^{S}$를 필요로 함
- Inexact Autoregressive Decomposition
- 다른 대안으로써 일부 codebook이 parallel 하게 예측되는 autoregressive decomposition을 고려할 수 있음
- $V_{0}=0$이고, 모든 $t\in \{1,...,T\}, k\in \{1,...,K\}$에 대해 $V_{t,k}=Q_{t,k}$인 sequence가 있다고 하자
- $V_{t}$에서 codebook index $k$를 dropping 하는 것은 time $t$에서 모든 codebook의 concatenation을 의미:
(Eq. 3) $p_{t,k}(V_{t-1},...,V_{0})\triangleq \mathbb{P}[V_{t,k}|V_{t-1},...,V_{0}]$ - 마찬가지로 모든 $t>0$에 대해 recursive 하게 $\tilde{V}_{0}=0$를 정의하면:
(Eq. 4) $\forall t>0, \, \forall k, \,\, \mathbb{P}[\tilde{V}_{t,k}]=p_{t,k}(\tilde{V}_{t-1},...,\tilde{V}_{0})$
- 위 결과는 (Eq. 2)와 달리 exact 분포 $p_{t,k}$에 접근할 수 있더라도 $\tilde{V}$와 $V$가 일반적으로 서로 동일한 분포를 따른다고 할 수 없음
- 실제로 모든 $t, (V_{t,k})_{k}$에 대해 $V_{t-1},...,V_{0}$가 conditinally independent인 경우에만 적절한 생성 모델을 얻을 수 있음
- 따라서 $t$가 증가함에 따라 error는 복잡해지고 두 분포는 서로 멀어질 수 있음 - 이러한 decomposition은 inexact 하지만, original frame rate를 유지하여 long sequence에 대해 학습/추론 속도를 향상할 수 있음
- 다른 대안으로써 일부 codebook이 parallel 하게 예측되는 autoregressive decomposition을 고려할 수 있음
- Arbitrary Codebook Interleaving Patterns
- 앞선 decomposition들의 영향을 측정하기 위해, codebook interleaving pattern을 도입
- $\Omega = \{(t,k):\{1,...,d\cdot f_{r}\},k\in \{1,...,K\}\}$를 모든 time step과 codebook index pair 간의 집합이라 하자
- 그러면 codebook pattern은 sequence $P=(P_{0},P_{1},P_{2},...,P_{S})$
- $P_{0}=\emptyset$이고 모든 $0<s\leq S$에 대해 $P_{s} \subset \Omega$이므로 $P$는 $\Omega$의 partition임 - 따라서 $P_{0},P_{1},...,P_{s-1}$의 모든 position에 대해 conditional 하게 $P_{s}$의 모든 position을 parallel 하게 예측하여 $Q$를 모델링함
- 이때 각 codebook index가 $P_{s}$에서 최대 한 번만 나타나는 pattern으로 restrict 함
- 따라서 다음과 같이 주어진 parallel pattern을 쉽게 decompose 할 수 있음:
(Eq. 5) $P_{s}=\{(s,k):k\in \{ 1,...,K\}\}$ - 추가적으로 codebook 간의 delay를 도입할 수도 있음:
(Eq. 6) $P_{s}=\{(s-k+1,k):k\in \{ 1,...,K\}, s-k\geq 0 \}$
- 앞선 decomposition들의 영향을 측정하기 위해, codebook interleaving pattern을 도입

- Model Conditioning
- Text Conditioning
- Input audio $X$에 대한 textual description이 주어지면, autoregressive model에서 inner dimenstion $D$를 사용하여 conditioning tensor $C\in \mathbb{R}^{T_{C}\times D}$를 계산
- 일반적으로 conditional audio 생성을 위한 text representation에는 3가지 approach가 있음
- T5와 같은 pre-trained text encoder의 사용
- Instruct-based language model의 사용
- CLAP과 같은 joint text-audio representation의 사용
- 실험적으로 MusicGen에서는 T5 encoder의 사용이 가장 적합한 것으로 나타남
- Melody Conditioning
- Text condition 외에 melodic structure를 condition으로 하여 model output을 iterative refine 할 수도 있음
- 이를 위해 input chromagram과 text description을 jointly conditioning 함
- 이때 실험적으로 raw chromagram에 대한 conditioning의 경우, original sample이 reconstruct 되어 overfitting이 발생하는 것으로 나타남 - 따라서 이를 해결하기 위해, 각 time step에서 dominant time-frequency bin을 선택하는 information bottleneck을 도입
- 이때 MusicGen은 unsupervised approach를 활용

- Model Architecture
- Codebook Projection and Positional Embedding
- Codebook pattern이 주어지면, 일부 codebook만이 각 pattern step $P_{s}$에서 나타남
- 이를 위해,
- $P_{s}$의 index 값을 $Q$에서 retrieve 해보면, 각 codebook은 $P_{s}$에 최대 한번 존재하거나 전혀 존재하지 않음
- 존재하는 경우, $N$개의 entry와 dimension $D$가 있는 learned embedding을 사용하여 $Q$의 관련 값을 나타냄
- 그렇지 않은 경우, 해당 값의 absence를 나타내는 special token을 사용함 - 위의 변환 이후, 각 codebook의 contribution을 합산하고,
- 이때 $P_{0}=\emptyset$이므로, 첫 번째 token input은 항상 special token의 합임 - Current step $s$를 encoding 하기 위해 sinusoidal embedding을 합산함
- $P_{s}$의 index 값을 $Q$에서 retrieve 해보면, 각 codebook은 $P_{s}$에 최대 한번 존재하거나 전혀 존재하지 않음
- Transformer Decoder
- Input은 $L$개의 layer와 dimension $D$가 있는 transformer에 제공됨
- 각 layer는 causual self-attention block으로 구성되고, conditioning signal $C$가 제공되는 cross-attention block이 추가됨- Melody conditioning을 사용할 때는, transformer input의 prefix로 conditioning tensor $C$를 사용함 - Layer는 $D$에서 $4\cdot D$ channel까지의 linear layer, ReLU activation으로 구성된 fully connected block으로 끝남
- Attention block과 fully connected block은 residual skip connection으로 wrapping 됨
- Layer Normalization은 residual skip connection과 더해지기 이전에 각 block에 적용됨
- Input은 $L$개의 layer와 dimension $D$가 있는 transformer에 제공됨
- Logits Prediction
- Pattern step $P_{s}$에서 transformer decoder의 output은 $P_{s+1}$로 주어진 index에서 취한 $Q$ 값에 대한 logits prediction으로 변환됨
- 이때 각 codebook은 $P_{s+1}$에 최대 한번 존재함 - Codebook이 존재하는 경우, $D$ channel부터 $N$ channel까지 codebook specific linear layer를 사용하여 logits prediction을 얻음
- Pattern step $P_{s}$에서 transformer decoder의 output은 $P_{s+1}$로 주어진 index에서 취한 $Q$ 값에 대한 logits prediction으로 변환됨
3. Experiments
- Settings
- Dataset
- Training : Internal dataset, ShutterStock, Pond5
- Evaluation : Music Caps - Comparisons : Riffusion, Mousai, MusicLM, Noise2Music
- Results
- Comparison with the Baselines
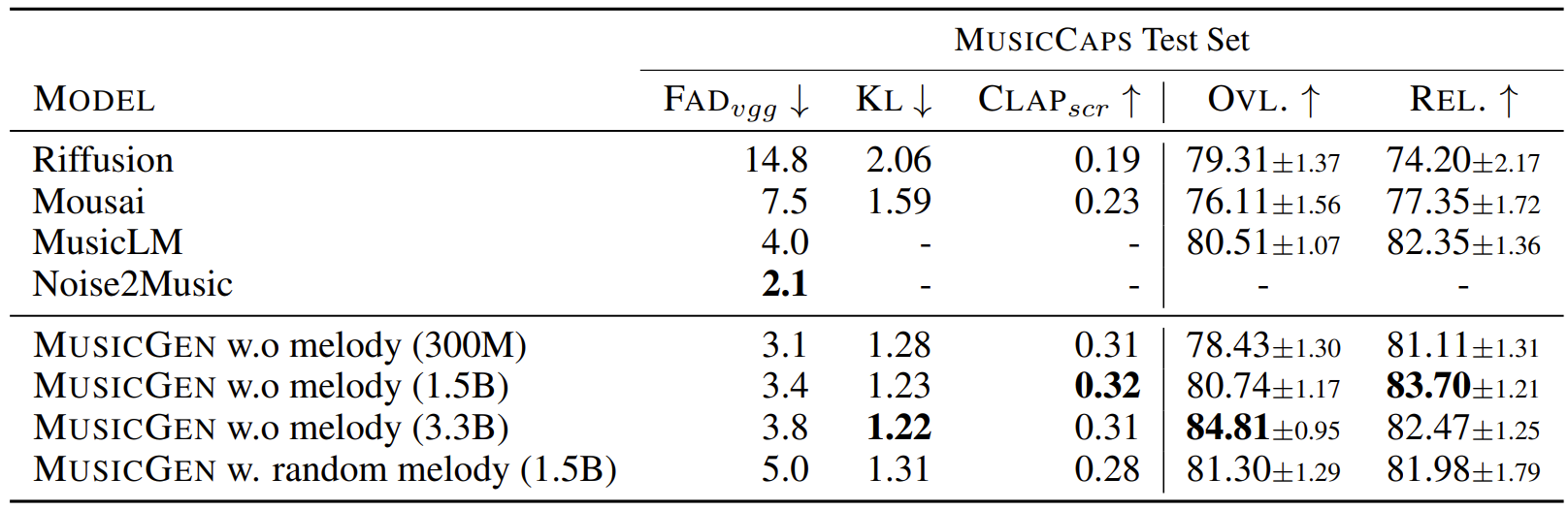
- Text-to-Music 작업에 대한 결과를 비교해 보면, MusicGen이 합성 품질과 text description 반영 측면에서 가장 우수한 성능을 보임
- Melody conditioning을 추가한 경우, 정량적인 지표 결과는 저하되지만 human evaluation에는 큰 영향을 주지 않음
- Melody Evaluation
- Melody 생성 측면에서 결과를 비교해 보면, chromagram conditioning을 활용하는 MusicGen이 주어진 melody를 따르는 음악을 가장 성공적으로 생성함
- 특히 MusicGen은 추론 시 chorma를 dropping 하는 것에 대해 robust 한 결과를 보임

- Fine-tuning for Stereophonic Generation
- Stereophonic data 생성으로 MusicGen을 확장하기 위해 delay pattern을 reuse 함
- Stereo delay : 동일한 codebook level에 대해 left/right channel 간의 delay를 반영
- Stereo partial delay : 주어진 level에 대해 left/right channel codebook에 동일한 delay를 적용 - 이를 통해 추가적인 계산 비용 없이 stereo audio를 생성 가능
- Stereophonic data 생성으로 MusicGen을 확장하기 위해 delay pattern을 reuse 함

- 결과적인 측면에서
- Stereo output을 mono로 downminxing 할 때 품질은 mono model과 거의 동일함
- Stereo partial delay가 Stereo delay pattern에 비해 전반적인 품질과 text relevance 모두에서 성능 향상을 보임

- Ablation
- Effect of the Codebook Interleaving Patterns
- Flattening은 생성 결과를 개선하지만 높은 계산 비용을 가짐
- 그에 비해 Simple delay approach를 사용하면 더 적은 비용으로 비슷한 성능에 도달할 수 있음

- Effect of Model Size
- 당연하게도 모델 size가 증가할수록 좋은 품질을 보이지만 학습/추론 시간이 증가함
- 주관적 평가 측면에서, 1.5B parameter를 가진 모델이 가장 optimal 한 것으로 나타남

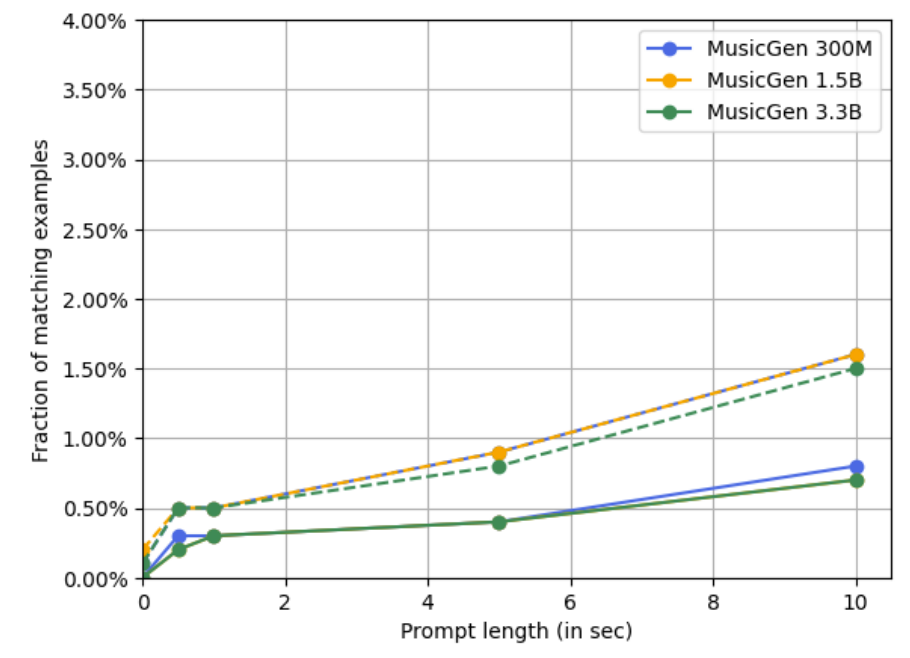
- Memorization Experiment
- 생성된 audio token과 source audio 간의 일치 여부를 비교해 보면
- MusicGen은 prompt length가 길어져도 우수한 memorization 성능을 보임
반응형
'Paper > Language Model' 카테고리의 다른 글
| [Paper 리뷰] Textually Pretrained Speech Language Models (0) | 2024.03.31 |
|---|---|
| [Paper 리뷰] AudioLM: A Language Modeling Approach to Audio Generation (0) | 2024.03.10 |
| [Paper 리뷰] MusicLM: Generating Music From Text (0) | 2024.03.09 |
| [Paper 리뷰] Pengi: An Audio Language Model for Audio Tasks (0) | 2024.03.07 |
| [Paper 리뷰] AudioGen: Textually Guided Audio Generation (0) | 2024.03.05 |
댓글