

티스토리 뷰
Paper/Conversion
[Paper 리뷰] StableVC: Style Controllable Zero-Shot Voice Conversion with Conditional Flow Matching
feVeRin 2025. 1. 28. 14:40반응형
StableVC: Style Controllable Zero-Shot Voice Conversion with Conditional Flow Matching
- Zero-Shot Voice Conversion은 다음의 한계점이 있음
- Style과 timbre를 서로 다른 unseen speaker에게 independently transfer 할 수 없음
- Autoregressive modeling이나 sampling step으로 인해 추론 속도가 느림
- Converted sample의 품질과 similarity는 여전히 만족스럽지 않음 - StableVC
- Speech를 linguistic content, timbre, style로 decompose하고 conditional flow matching module을 사용하여 high-quality mel-spectrogram을 생성함
- Zero-shot ability를 위해 conventional feature concatenation 대신 adaptive gate를 활용한 dual attention mechanism을 도입함
- 논문 (AAAI 2025) : Paper Link
1. Introduction
- Zero-shot Voice Conversion (VC)은 linguistic content를 유지하면서 source speaker timbre를 unseen speaker에게 transfer 하는 것을 목표로 함
- BUT, 기존 방식은 unseen speaker에 timbre를 adapt하는데 focus 하므로 style attribute를 overlooking 함
- 추가적으로 기존 VC system은 complicated training setup과 autoregressive formulation으로 인해 computationally expensive 함
-> 그래서 style-controllable VC 품질을 향상하면서 inference speed 문제를 해결한 StableVC를 제안
- StableVC
- Speech를 content, timbre, style로 decompose 한 다음, flow matching generative module을 사용하여 high-quality mel-spectrogram을 reconstruct
- Flow matching module은 multiple Diffusion Transformer (DiT)로 구성되어 target mel-spectrogram의 probabilistic distribution을 modeling 하는 vector field를 predict 하도록 training 됨
- Attribute disentanglement의 경우, $k$-means clustering을 도입한 pre-trained self-supervised model을 사용하여 linguistic content를 추출하고 factorized codec을 통해 style representation을 추출함
- 추가적으로 style/timbre modeling에 conventional concatenation 대신 adaptive gate 기반의 dual attention mechanism을 적용
- Speech를 content, timbre, style로 decompose 한 다음, flow matching generative module을 사용하여 high-quality mel-spectrogram을 reconstruct
< Overall of StableVC >
- Style, timbre를 condition으로 하는 probability-density path prediction을 위한 conditional flow matching module을 도입하여 efficiency를 향상
- Flow matching module에 adaptive gate control을 포함한 dual attention mechanism을 적용하여 distinct timbre/style을 capture 함
- 결과적으로 기존보다 빠른 inference speed와 뛰어난 conversion 품질을 달성
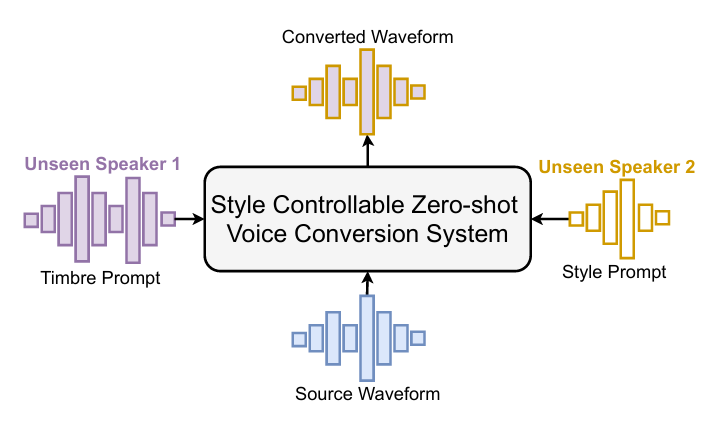
2. Method
- Overview
- StableVC는 zero-shot VC task에 flexible style control capability를 제공하는 것을 목표로 함
- 먼저 waveform에서 linguistic content, style representation, mel-spectrogram을 추출함
- 이후 linguistic information을 disentangle 하기 위해 pre-trained WavLM model을 적용하고 $k$-means clustering을 통해 discrete token을 추출함
- 여기서 $k$-means cluster 수는 1024로 설정하고 adjacent token을 deduplicate 한 다음, $k$-means embedding으로 replace 함
- Deduplication은 각 token의 duration을 repredict 하여 same linguistic content의 duration을 다른 timbre/style에 맞게 adpat 할 수 있도록 함
- Style representation의 경우 factorized codec을 style extractor로 사용함
- 해당 model은 speech style의 disentangled subspace representation을 추출함 - Timbre representation의 경우 multiple reference speech에서 mel-spectrogram을 추출하여 사용함
- Disentangled feature는 multiple DiT block으로 구성된 content module을 통해 encoding 됨
- 이후 duration module을 통해 duration을 predict 하고 hidden representation을 frame-level에 align 함
- 여기서 duration module output은 timestep fusion이 있는 multiple DiT block으로 구성된 flow matching module을 사용하여 mel-spectrogram으로 변환됨
- Style/timbre는 각 DiT block 내의 DualAGC에 의해 modeling 되고, 최종적으로 generated mel-spectrogram은 Vocoder를 통해 waveform으로 reconstruct 됨

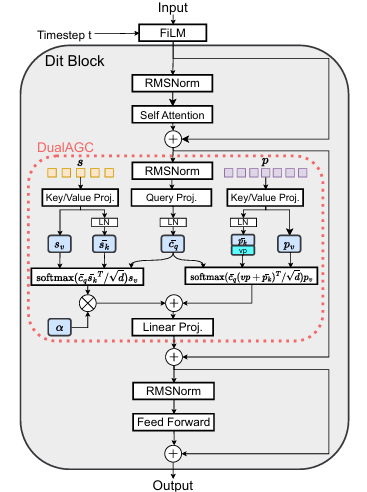
- DualAGC
- DiT block은 adaptive layer norm이나 cross-attention을 사용하여 external condition을 append 함
- 이때 StableVC는 style information과 speaker timbre를 capture 하기 위해, dual attention mechanism을 incorporate 한 DualAGC를 도입함
- 즉, timbre modeling의 stability를 향상하기 위해 dual attention mechanism에 timbre prior information을 도입하고,
- Adaptive gate mechanism을 사용하여 style information을 content/timbre로 gradually integrate 함
- DiT block의 input이 $c$이고 style encoder와 mel-extractor의 output을 각각 $s,p$라고 하자
- 먼저 논문은 DiT block 앞에 FiLM layer를 추가하여 time step $t$에 condition 된 affine feature-wise transformation을 적용함
- 다음으로 style extractor에서 추출된 quantized style embedding은 average pooling layer와 convolutional block을 통과함
- Style encoder는 quantized embedding을 time dimension에서 $\times 4$ compress 하고 style information의 correlation을 capture 함
- 이때 $p$는 multiple reference speech에서 추출한 mel-spectrogram을 의미하고, $\bar{c}_{q}$는 query projection과 query-key normalization으로 얻어진 hidden representation을 의미함
- 이때 StableVC는 style information과 speaker timbre를 capture 하기 위해, dual attention mechanism을 incorporate 한 DualAGC를 도입함
- Timbre Attention
- 논문은 speaker timbre를 represent 하는 reference speech에서 fine-grained information을 추출하는 것을 목표로 함
- 이를 위해 attention query로 $\bar{c}_{q}$를 사용하고, multiple reference에서 추출한 mel-spectrogram을 timbre attention의 value로 사용함
- Cross-attention mechanism은 input position에 agnostic 하고 mel-spectrogram에 대한 temporal shuffling을 effectively resemble 함
- 즉, 해당 process는 linguistic content와 같은 other detail은 minimizing 하면서 speaker information은 preserving 하여 cross-attention mechanism이 reference speech에서 speaker timbre를 capture 하는데 focus 하도록 함
- 추가적으로 timbre modeling의 stability를 향상하기 위해 pre-trained speaker verification model에서 global speaker embedding을 추출하여 attention key로 mel-spectrogram과 concatenate 함
- 결과적으로 추출된 speaker embedding은 instructive timbre prior 역할을 하여, timbre attention이 timbre-related information을 추출하도록 guiding 함
- Style Attention
- Compressed style representation $s$는 style attention에서 key, value로 사용되고 $\bar {c}_{q}$는 attention query로 사용됨
- Style information을 linguistic content와 timbre에 gradually inject 하기 위해, adaptive gating mechanism을 도입함
- 여기서 injection process를 control 하는 gate로써 zero-initialized learnable parameter $\alpha$를 사용함
- Style key $s_{k}$, style value $s_{v}$, timbre key $p_{k}$, timbre value $p_{v}$가 주어졌을 때, DualAGC의 final output $O$는:
(Eq. 1) $O=\text{softmax}\left(\frac{\bar{c}_{q}(\text{vp}\oplus\bar{p}_{k})^{\top}}{\sqrt{d}}\right)p_{v}+ \tanh(\alpha)\text{softmax}\left(\frac{\bar{c}_{q}\bar{s}_{k}^{\top}}{\sqrt{d}}\right)s_{v}$
- $\bar{s}_{k},\bar{p}_{k}$ : query-key norm, $d$ : query dimension, $\oplus$ : concatentation
- $\text{vp}$ : pre-trained speaker verification model에서 추출된 global speaker embedding
- Style injection process는 timbre modeling에 영향을 주지 않으면서 adaptive style modeling을 지원함
- Conditional Flow Matching
- Vector field에 의해 생성된 probability-density path로부터 flow matching module의 training objective를 도출하자
- Flow matching은 target distribution $p_{1}(x)$와 standard distribution $p_{0}(x)$ 간의 time-dependent probability path를 fit 하기 위해 사용됨
- Flow matching은 continuous normalizing flow와 연관되어 있지만, simulation-free fashion으로 efficiently training 될 수 있음
- 먼저 flow $\phi:[0,1]\times \mathbb{R}^{d}\rightarrow \mathbb{R}^{d}$는 ODE를 사용하여 두 density function 간의 mapping으로 정의됨:
(Eq. 2) $\frac{d}{dt}\phi_{t}(x)=v_{t}(\phi_{t}(x));\,\,\, \phi_{0}(x)=x $
- $v_{t}(x)$ : time-dependent vector field로써 learnable component
- 이때 더 적은 step으로 target distribution을 efficiently sample 하기 위해 optimal transport에 기반한 conditional flow matching을 적용함 - 즉, 논문은 marginal flow를 pratically determine 하는 것이 어려우므로 다음과 같이 multiple conditional flow에 대해 marginalizing 함:
(Eq. 3) $\phi_{t,x_{1}}(x)=\sigma_{t}(x_{1})x+\mu_{t}(x_{1})$
- $\sigma_{t}(x), \mu_{t}(x)$ : distribution $p_{1}(x), p_{0}(x)$ 간의 distribution을 parameterize 하는 데 사용되는 time-conditional affine transformation
- Training data에 대한 unknown distriubtion $q(x)$의 경우, $\sigma_{\min}=0.0001$의 white noise로 individual sample을 perturbing 한 다음 $q(x)$의 approximation으로 $p_{1}(x)$를 정의함 - 결과적으로 다음과 같이 simple linear trajectory를 통해 trajectory를 specify 할 수 있음:
(Eq. 4) $\mu_{t}(x)=tx_{1},\,\,\sigma_{t}(x)=1-(1-\sigma_{\min})t$
- 먼저 flow $\phi:[0,1]\times \mathbb{R}^{d}\rightarrow \mathbb{R}^{d}$는 ODE를 사용하여 두 density function 간의 mapping으로 정의됨:
- Conditional flow matching을 사용한 vector field의 final training objective는:
(Eq. 5) $\mathcal{L}_{CFM}=\mathbb{E}_{t,q(x_{1}),p(x_{0})}|| v_{t}(\phi_{t,x_{1}}(x_{0});h)- (x_{1}-(1-\sigma_{\min})x_{0})||^{2}$
- $h$ : duration module의 output과 style/timbre representation을 포함하는 conditional set - Conditional flow matching은 additional distillation 없이도 source/target distribution 간의 simpler, straighter trajectory를 제공함
- 이때 $t=0$에서 initial condition으로 standard Gaussian distribution $p_{0}(x)$에 대한 sampling을 수행하고,
- 10 Euler step을 사용하여 ODE에 대한 solution을 approximate 하고 target distribution과 match 하는 sample을 efficiently generate 함
- Training Objectives
- Factored codec에서 추출된 representation은 주로 style-related information을 포함하고 있지만, 여전히 potential timbre leakage가 발생할 수 있음
- 따라서 style/timbre 간의 더 나은 disentanglement를 위해 Gradient Reversal Layer (GRL)가 있는 adversarial classifier를 사용하여 style encoder output에서 potential timbre information을 제거함
- 먼저 style encoder output을 fixed-dimensional global representation으로 average 하고 additional speaker classifier를 사용하여 speaker identity를 예측함
- 이때 GRL loss는:
(Eq. 6) $\mathcal{L}_{GRL}=\mathbb{E}[-\log(C_{\theta}(I|\text{avg}(s)))]$
- $C_{\theta}$ : speaker classifier, $I$ : speaker identity label - Gradient는 style encoder를 optimize 하고 potential timbre information을 제거하기 위해 reverse 됨
- 이때 GRL loss는:
- Duration module은 style/timbre representation에 따라 content extractor의 deduplicated length를 repredict 하도록 training 됨
- 이를 통해 생성된 waveform은 다른 timbre/style을 기반으로 다른 duration을 adapt 할 수 있음
- Duration module의 training objective $\mathcal{L}_{dur}$은 log-scale predicted duration과 ground-truth 간의 mean squared error를 minimize 하는 것과 같음
- 결과적으로 StabelVC의 overall training loss는:
(Eq. 7) $\mathcal{L}=\mathcal{L}_{CFM}+\mathcal{L}_{dur}+\lambda\mathcal{L}_{GRL}$
- $\lambda=0.1$ : hyperparameter
3. Experiments
- Settings
- Dataset : LibriLight, VCTK, ESD
- Comparisons : StyleVC, LM-VC, VALL-E, NaturalSpeech, DDDM-VC, SEF-VC
- Results
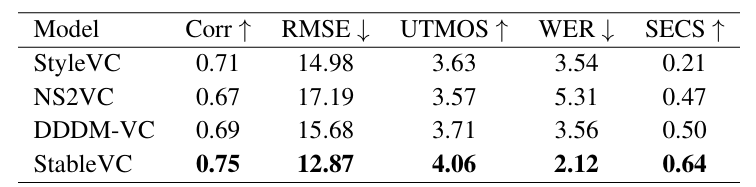
- Zero-Shot VC
- 전체적으로 StabelVC의 성능이 가장 뛰어남

- Style Transfer
- Style Transfer 측면에서도 StableVC가 가장 우수함
- Violin plot으로 similarity를 비교했을 때도 StableVC가 가장 높은 similarity를 보임

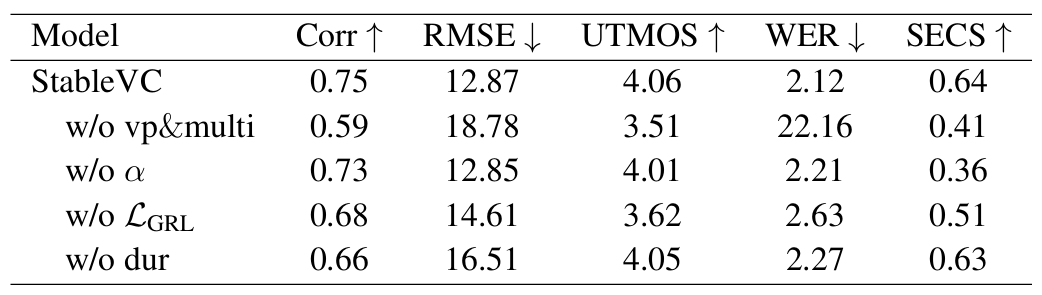
- Ablation Study
- Euler step 수 $N$을 줄이는 경우 RTF는 빨라지지만 합성 품질은 저하됨

- StableVC의 각 component를 제거하는 경우에도 성능 저하가 발생함
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글