

티스토리 뷰
Paper/Conversion
[Paper 리뷰] SEF-VC: Speaker Embedding Free Zero-Shot Voice Conversion with Cross Attention
feVeRin 2024. 8. 15. 09:26반응형
SEF-VC: Speaker Embedding Free Zero-Shot Voice Conversion with Cross Attention
- Zero-shot voice conversion은 unseen target speaker로의 변환을 수행할 수 있지만, speaker similarity 측면에서 한계가 있음
- SEF-VC
- Speaker embedding을 사용하지 않고 Position-Agnostic Cross-Attention을 도입하여 reference speech에서 speaker timbre를 학습
- 이후 HuBERT semantic token으로부터 non-autoregressive 방식으로 waveform을 reconstruct
- 논문 (ICASSP 2024) : Paper Link
1. Introduction
- Zero-Shot Voice Conversion (VC)는 주어진 speech content를 유지하면서 unseen target speaker로 변환하는 것을 목표로 함
- 이때 VC system은 다음의 2가지를 수행할 수 있어야 함
- Speaker/content information disentanglement
- 이를 통해 source speech에서 speaker information을 제거할 수 있음 - Speaker representation modeling
- Speaker identity를 효과적으로 반영할 수 있음
- Speaker/content information disentanglement
- Speaker information disentanglement를 위해서는 주로 information bottleneck을 활용함
- AdaIN-VC와 같이 bottleneck feature를 활용하면 disentanglement가 용이하지만, 음성 품질 측면에서 한계가 있음
- 그 외에도 YourTTS와 같이 normalizing flow를 활용할 수도 있고, VQ-Wav2Vec이나 HuBERT와 같은 self-supervised semantic feature를 활용할 수도 있음
- 특히 self-supervised semantic feature는 speaker-variant 없이 linguistic content를 효과적으로 유지 가능
- Speaker representation modeling 측면에서 대부분의 VC system은 speaker verification network에 의존적임
- 이때 VC system은 다음의 2가지를 수행할 수 있어야 함
-> 그래서 speaker embedding에 의존하지 않는 zero-shot VC model인 SEF-VC를 제안
- SEF-VC
- 효과적인 speaker reprentation modeling을 위해 Position-Agnostic Cross-Attention을 도입
- 해당 cross-attention으로 reference timbre를 학습한 다음, non-autoregressive 방식으로 HuBERT semantic token에서 wavefom을 reconstruct
< Overall of SEF-VC >
- Position-Agnostic Cross-Attention을 도입한 speaker-embedding free VC model
- 결과적으로 기존보다 뛰어난 conversion 성능을 달성
2. Method
- Non-Autoregressive Semantic Backbone
- SEF-VC는 vec2wav와 같은 discrete self-supervised speech representation에 대한 standard vocoder를 backbone으로 함
- 먼저 pre-trained HuBERT에서 추출한 continuous feature에 대해 $K$-means quantization을 수행하여 semantic token을 얻음
- 추가적으로 합성 품질을 향상하기 위해 adversarial training을 도입함
- 여기서 discriminator는 HiFi-GAN과 같이 multi-period discriminator (MPD), multi-scale discriminator (MSD)를 활용

- Position-Agnostic Cross-Attention Mechanism
- Self-supervised semantic token은 speaker information을 제공하지 않으므로, timbre conversion은 speaker information을 따라야 함
- 따라서 논문은 기존의 speaker embedding 대신, speaker embedding free cross-attention task로 formulate 함
- 이때 Semantic backbone은 reference speech에서 speaker timbre를 직접 학습하고 incorporate 함
- 추가적으로 mel-spectrogram에 reference speech의 충분한 speaker information을 반영하도록, position-agnostic cross-attention mechanism을 통해 speaker information을 semantic backbone에 통합
- 구체적으로 semantic backbone에서 각 semantic encoder는 Conformer block으로 구성됨
- Conformer block은 self-attention layer와 convolution module 사이에 cross-attention module을 배치하여 구성됨
- 한편으로 cross-attention 이전에 target mel-spectrogram은 1D convolution layer로 구성된 pre-net에 기반한 mel-encoder로 전달됨
- Conformer block은 self-attention layer와 convolution module 사이에 cross-attention module을 배치하여 구성됨
- 이때 cross-attention은 input position에 agnostic 하므로 encoded mel-sequence에서 key/value matrix를 계산할 때, positional encoding이 cancel 됨
- 이는 encoded mel-spectrogram을 shuffling 하는 것과 동일함
- 특히 speaker timbre는 time-order와 무관하기 때문에 sequential order가 breaking 되어도 다른 information과 달리 speaker information은 그대로 유지될 수 있음
- 이를 통해 cross-attention mechanism은 reference speech에서 speaker timbre를 capture 하도록 유도됨
- 해당 cross-attention mechanism은 short/long reference 모두에서 활용가능함
- Short reference의 경우, cross-attention은 기본적으로 mel-spectrogram을 fully explore 하고 활용할 수 있음
- Long reference의 경우, position-agnostic cross-attention을 통해 arbitrary length의 reference speech를 충분히 대응할 수 있음
- 결과적으로 semantic content에 acoustic prompt를 prefix 하고 self-attention를 적용한 autoregressive model과 비교하여, SEF-VC는 position-agnostic cross-attention을 통해 non-autoregressive 하게 동작하고 stability를 향상할 수 있음
- 따라서 논문은 기존의 speaker embedding 대신, speaker embedding free cross-attention task로 formulate 함
- Training and Inference
- SEF-VC는 non-parallel data를 활용하여 training 됨
- 여기서 single utterance는 2개의 segment로 나누어짐
- First segment는 speaker information을 제공하는 mel-spectrogram을 추출하는데 사용
- 2~3초의 varying length에서 random starting point를 crop 하여 얻어짐 - First segment를 제외한 나머지는 second segment로 사용되고, pre-trained HuBERT로 전달되어 semantic token을 추출하도록 함
- 이를 통해 oracle speaker label 없이 두 segment가 항상 동일한 speaker에 속하도록 할 수 있음
- First segment는 speaker information을 제공하는 mel-spectrogram을 추출하는데 사용
- Auxiliary feature adaptor는 first semantic encoder의 output을 사용하여 PPE를 예측함
- 이후 ground-truth PPE를 first semantic encoder에 전달하여 나머지 module이 waveform을 reconstruct 하도록 도움 - Generator loss $\mathcal{L}_{G}$는 다음의 weighted sum으로 정의됨:
(Eq. 1) $\mathcal{L}_{G}=\lambda_{rec}\mathcal{L}_{rec}+\lambda_{feat}\mathcal{L}_{feat}+\lambda_{mel}\mathcal{L}_{mel}+\lambda_{aux}\mathcal{L}_{aux}+\lambda_{adv}\mathcal{L}_{adv}$
- $\mathcal{L}_{rec}$ : ground-truth와 synthetic mel-spectrogram 간의 $L1$ distance로 얻어지는 reconstruction loss
- $\mathcal{L}_{feat}$ : discriminator의 intermediate ouptut 간의 $L1$ feature matching loss
- $\mathcal{L}_{mel}$ : second semantic encoder output과 target mel-spectrogram 간의 $L1$ loss
- $\mathcal{L}_{aux}$ : ground-truth $PPE$와 auxiliary feature adaptor로 얻어진 $\widehat{PPE}$ 간의 $L1$ loss
- $\mathcal{L}_{adv}$ : $L2$ adversarial loss - 추론 시에는 target reference speech를 통해 speaker information이 포함된 mel-spectrogram을 추출하고, pre-trained HuBERT를 통해 source speech에 대한 semantic token을 얻음
- 이때 PPE는 target speaker에 대한 semantic information과 reference speech를 기반으로 예측됨
- 여기서 single utterance는 2개의 segment로 나누어짐
3. Experiments
- Settings
- Results
- Any-to-Any Voice Conversion
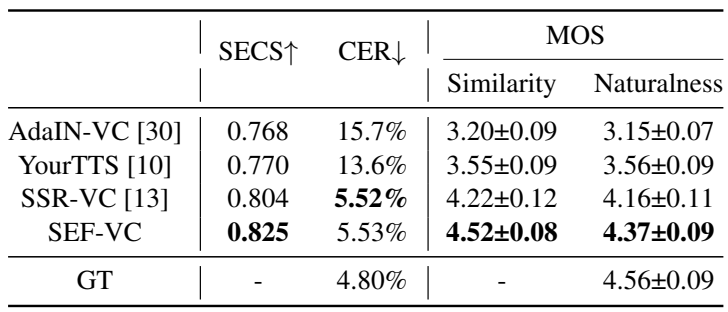
- SECS, CER, MOS 측면에서 SEF-VC가 가장 우수한 성능을 달성함
- Different Reference Lengths
- 일반적으로 reference speech length가 길어질수록 성능이 향상됨
- Prompt가 길수록 speaker information을 모델링하기 쉬워지기 때문 - BUT, 2초의 짧은 reference를 사용하더라도 SEF-VC는 SSR-VC보다 뛰어난 성능을 달성 가능함
- 일반적으로 reference speech length가 길어질수록 성능이 향상됨

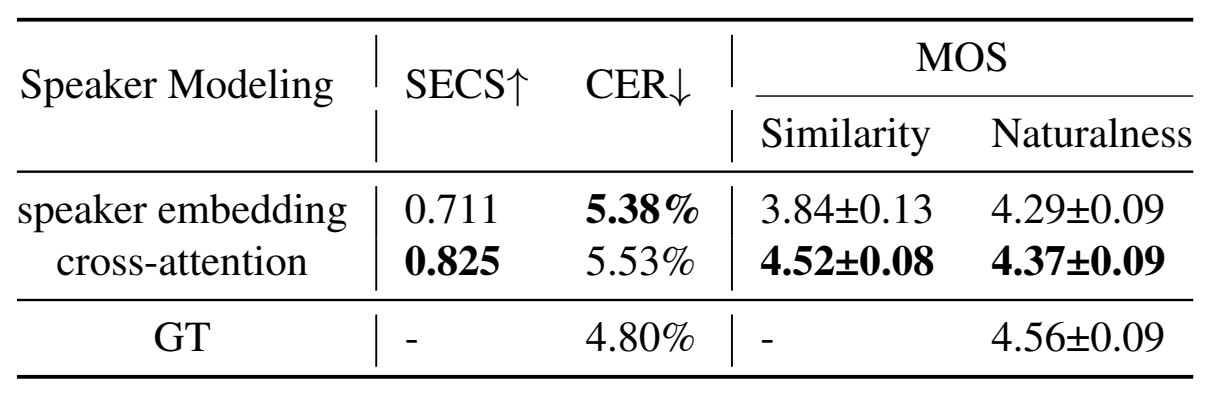
- Cross-Attention vs. Speaker Embedding
- Cross-attention을 사용하는 것이 speaker embedding을 사용하는 것보다 더 뛰어남
반응형
'Paper > Conversion' 카테고리의 다른 글
댓글