
티스토리 뷰
Paper/Conversion
[Paper 리뷰] DualVC: Dual-mode Voice Conversion Using Intra-model Knowledge Distillation and Hybrid Predictive Coding
feVeRin 2024. 9. 28. 09:35반응형
DualVC: Dual-mode Voice Conversion Using Intra-model Knowledge Distillation and Hybrid Predictive Coding
- 일반적인 non-streaming voice conversion은 전체 utterance를 full context로 활용할 수 있지만, streaming voice conversion은 future information이 제공되지 않으므로 품질이 상당히 저하됨
- DualVC
- Jointly trained separate network parameter를 활용하여 streaming/non-streaming mode를 지원하는 dual-mode conversion을 활용
- Streaming conversion의 성능을 향상하기 위해 intra-model knowledge distillation과 Hybrid Predictive Coding을 도입
- 추가적으로 data agumentation을 통해 noise-robust autoregressive decoder를 training 함
- 논문 (INTERSPEECH 2023) : Paper Link
1. Introduction
- Voice Conversion (VC)는 linguistic content를 변경하지 않고 다른 speaker voice로 변환하는 것을 목표로 함
- 최근의 VQMIVC, AutoVC와 같은 non-streaming VC model은 우수한 conversion 성능에 비해 full utterance가 필요하고 real-time application에는 적합하지 않다는 단점이 있음
- Streaming VC model의 경우 chunk/frame-wise input을 on-the-fly로 처리해야 하고, future information에 access 할 수 없어 conversion 품질이 상당히 낮음
- 이를 해결하기 위해 일반적인 bottleneck feature (BNF) 대신 Intermediate Bottleneck Feature (IBF)를 활용할 수 있지만, source speaker timbre가 leakage 될 수 있다는 단점이 있음
- 구조적인 측면에서는 VQVC+와 같이 vector quantization (VQ)를 활용하거나 Contrastive Predictive Coding (CPC)를 활용하여 speaker timbre와 linguistic content를 disentangle 하는 방법을 활용할 수 있음
- 한편으로 streaming VC system의 성능을 향상하기 위해 non-streaming system을 teacher로 활용하여 streaming system에 대한 augmentation을 수행할 수 있음
- BUT, teacher guidance는 별도의 pre-trained VC model에 의존하므로 pipeline이 복잡해짐
- 최근의 VQMIVC, AutoVC와 같은 non-streaming VC model은 우수한 conversion 성능에 비해 full utterance가 필요하고 real-time application에는 적합하지 않다는 단점이 있음
-> 그래서 streaming VC의 성능을 크게 향상하고, inference 과정에서 streaming/non-streaming을 모두 지원할 수 있는 DualVC를 제안
- DualVC
- Pre-trained non-streaming teacher model을 사용하지 않고 dual-mode convolution을 활용하여 non-streaming teacher와 streaming student를 single model로 통합
- 이때 mutual effect가 있는 shared parameter를 사용하지 않고 서로 다른 mode에 대한 distinct parameter를 적용
- 추가적으로 distillation loss는 intermediate feature 사이에서 계산되고, potential interference를 방지하기 위해 distillation process에서 non-streaming module을 detach 함 - Streaming mode에서 future information의 부재를 compensate 하는 Hybrid Predictive Coding (HPC)를 채택
- Contrastive, autoregressive predictive coding을 결합하여, encoder가 future information이 없을 때 resilient feature structure를 학습하도록 함 - 추가적으로 long-sentence에서 error accumulation 문제를 완화하기 위해 input mel-spectrogram과 autoregressive module gradient에 noise를 도입
- Pre-trained non-streaming teacher model을 사용하지 않고 dual-mode convolution을 활용하여 non-streaming teacher와 streaming student를 single model로 통합
< Overall of DualVC >
- Intra-model distillation과 HPC를 활용하여 streaming/non-streaming에 대한 dual-mode VC를 지원
- 결과적으로 기존보다 뛰어난 conversion 성능을 달성
2. Method
- DualVC는 encoder, HPC module, decoder를 기반으로 구축됨
- 먼저 pre-trained ASR model을 통해 input mel-spectrogram으로부터 BNF를 추출하고, 해당 BNF를 encoder로 전달하여 context information을 추출함
- HPC module은 training stage에서만 사용되고, unsupervised learning method를 통해 effective latent representation을 추출하는 역할
- 최종적으로 target speaker embedding은 latent representation에 concatenate 되어 decoder input으로 전달되어 converted mel-spectrogram을 생성함
- Streamable Architecture
- DualVC는 CBHG encoder와 autoregressive (AR) decoder로 구성된 CBHG-AR을 backbone으로 함
- 이때 streaming이 가능하려면 future information에 의존하는 component를 수정하거나 교체해야 함
- 따라서 bidirectional GRU layer와 convolution layer는 unidirectional GRU layer, causal convolution layer로 교체됨
- 일반적인 convolution network에서 padding은 input의 양 side에 추가되어 input/output feature length를 동일하게 만드므로, perceptive field 내에서 hisotrical/current/future information에 access 할 수 있음
- BUT, streaming inference 시에는 future information을 사용할 수 없으므로 모든 padding이 left-shift 된 causal convolution layer를 사용해야 함 - Unidirectional GRU layer도 마찬가지로 current frame과 last hidden state만을 input으로 제공하여 model이 future information에 의존하지 않고 inference를 수행하도록 함
- 일반적인 convolution network에서 padding은 input의 양 side에 추가되어 input/output feature length를 동일하게 만드므로, perceptive field 내에서 hisotrical/current/future information에 access 할 수 있음
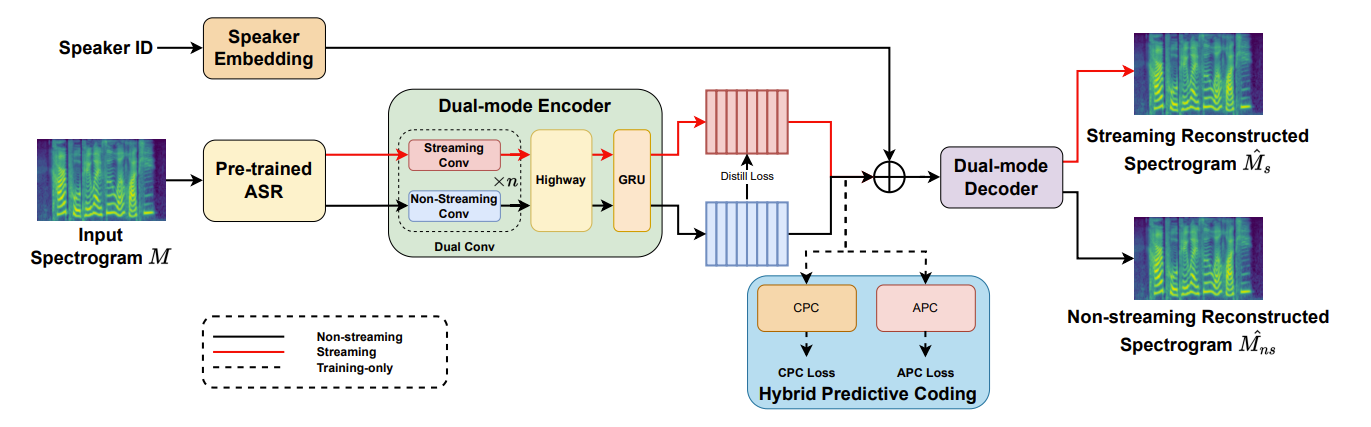
- Dual-mode Convolution
- Casual convolution을 활용하면 future information을 missing 할 수 있어 성능이 저하됨
- 이를 해결하기 위해 논문은 intra-model knowledge distillation을 사용하는 dual-mode convolution을 도입함
- 구조적으로는 depthwise separable convolution variant를 basic convolution layer로 활용
- 2개의 pointwise convolution layer 사이에 depthwise convolution layer가 위치하고 dropout layer를 추가 - Dual-mode convolution block은 2개의 parallel basic convolution layer로 구성
- 각각 streaming mode에 대해 causal, non-streaming mode에 대해 non-causal 함 - 결과적으로 backbone model의 모든 convolution layer는 dual-mode convolution block으로 대체됨
- 구조적으로는 depthwise separable convolution variant를 basic convolution layer로 활용
- 한편으로 streaming intermediate representation을 non-streaming representation에 가깝게 만들기 위해, streaming encoder output $Z$와 non-streaming encoder output $\hat{Z}$ 간의 loss를 계산함
- 이때 해당 두 mode는 pre-trained teacher model에 의존하지 않고 jointly train 되므로 intra-model knowledge distillation이라고 함
- 결과적으로 knowledge distillation loss는:
(Eq. 1) $\mathcal{L}_{distill}=\text{SmoothL1Loss}(Z,detach(\hat{Z}))$
- $\text{SmoothL1Loss}$ : Fast RCNN의 smoothed $L1$ loss로써 $Z, \hat{Z}$ 간의 element-wise differnece를 측정함
- $\hat{Z}$는 non-streaming mode에 영향을 주지 않으면서 streaming mode output을 non-streaming mode에 가깝게 만들기 위해 detach 됨
- Dual-mode convolution은 streaming, non-streaming scenario 모두에서 single model을 사용할 수 있게 하고, training 중에 non-streaming convolution ouput을 guidance로 사용하여 streaming convolution의 성능을 향상 가능
- 특히 DualVC에서는 streaming/non-streaming에 대해 distinct convolution parameter를 사용하고, 추론 시에는 streaming/non-streaming convolution이 선택적으로 활용되므로 computational overhead가 발생하지 않음
- Dual-mode decoder의 경우 output이 ground-truth mel-spectrogram에 의해 directly bound 되므로 distillation loss가 필요하지 않음
- 이를 해결하기 위해 논문은 intra-model knowledge distillation을 사용하는 dual-mode convolution을 도입함
- HPC for Unsupervised Latent Representation Learning
- 앞선 dual-mode convolution 외에도 CBHG encoder에서 추출된 latent representaion을 향상해 conversion 품질을 더욱 개선할 수 있음
- 이를 위해 논문은 unsupervised representation learning method인 CPC와 Autoregressive Predictive Coding (APC)를 결합한 HPC를 도입함
- 먼저 CPC는 autoregressive-based g-net을 사용하여 $Z$에서 aggregation $R_{k}=\{r_{k,1},r_{k,2},...\}$를 추출하고 InfoNCE loss로 training 됨
- 특히 g-net은 $r_{k,t}$를 input으로 하여 future $m$ step $[z_{k,t+1},z_{k,t+m}]$에서 positive/negative sample을 distinguish 해 latent representaiton $Z$가 better feature structure를 반영하도록 함
- 이때 negative sample selection은 encoded representation에 영향을 미치므로, prior knowledge를 사용하여 feature의 important part만을 추출하고 unwanted part를 제거할 수 있음
- 한편으로 APC는 $L1$ loss를 최소화하여 $[z_{k,t+1},z_{k,t+m}]$을 예측하는 autoregressive model과 같음
- CPC와 달리 APC는 representation learning을 위한 prior knowledge를 사용하지 않으므로 더 많은 information을 preserve 할 수 있음 - 결과적으로 hybrid 방식인 HPC는 아래 그림과 같이 CPC와 APC를 결합하여 구성됨
- HPC는 CPC와 APC에 대해 개별적인 g-net을 채택하고 staright prediction과 positive/negative sample 간의 classification을 수행함
- Streaming 중에는 future information을 얻을 수 없지만, 해당 HPC module에서 capture 된 common feature structure를 통해 DualVC는 future information을 어느 정도 추론할 수 있음 - 이때 HPC loss는:
(Eq. 2) $\mathcal{L}_{HPC}+\mathcal{L}_{CPC}+\mathcal{L}_{APC}$
- HPC는 CPC와 APC에 대해 개별적인 g-net을 채택하고 staright prediction과 positive/negative sample 간의 classification을 수행함

- Noise Robust Autoregressive Decoder
- AR decoder를 활용하여 historical information을 기반으로 generation을 수행할 수 있음
- BUT, loss가 적용된 upstream feature에 대한 AR process는 error가 accumulate 되므로 시간에 따라 conversion 품질이 저하되는 경향이 있음
- 특히 infinite length의 input audio를 가지는 streaming model의 경우 해당 문제에 취약함 - 따라서 해당 autoregressive structure의 robustness를 향상해야 하기 위해, DualVC는 input feature augmentation과 gradient augmentation을 결합한 data augmentation을 도입함
- 먼저 normally distributed noise $n\in\mathcal{N}(0,1)$를 AR의 ground-truth input에 추가한 다음, AR step에서 error가 포함된 feature를 재도입
- 추가적으로 training 중에 noise $\hat{n}\in\mathcal{N}(0,10^{-6})$을 AR module의 gradient에 더함
- Overall objective function은 앞선 $\mathcal{L}_{distill}, \mathcal{L}_{HPC}$를 포함하여, ground-truth mel-spectrogram $Y$와 generated $\hat{Y}$ 사이에서 계산된 reconstruction loss $\mathcal{L}_{rec}$로 구성됨:
(Eq. 3) $\mathcal{L}_{rec}=\text{MSELoss}(Y,\hat{Y})$
(Eq. 4) $\mathcal{L}=\mathcal{L}_{distill}+\mathcal{L}_{HPC}+\mathcal{L}_{rec}$
- BUT, loss가 적용된 upstream feature에 대한 AR process는 error가 accumulate 되므로 시간에 따라 conversion 품질이 저하되는 경향이 있음
3. Experiments
- Settings
- Dataset : Mandarin corpus (internal)
- Comparisons : IBF-VC
- Results
- 전체적으로 DualVC가 가장 우수한 naturalness와 similarity를 보임
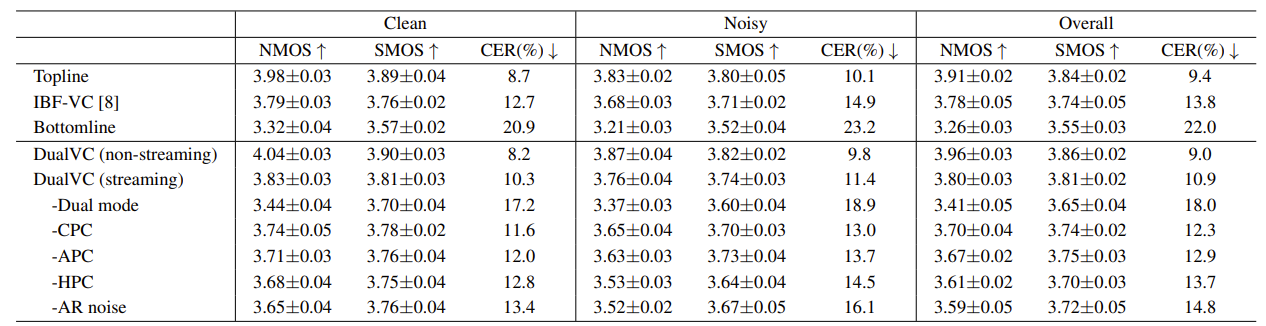
- Computational Efficiency Evaluation
- System latency는 다음과 같이 계산됨:
(Eq. 5) $\text{Latency}=\text{chunksize}\times (1+\text{RTF})$ - 결과적으로 DualVC는 160ms chunk size에 대해 92.8ms의 inference latency와 252.8ms의 total latency를 보임
- System latency는 다음과 같이 계산됨:

반응형
'Paper > Conversion' 카테고리의 다른 글
댓글